
Хоча Linux дуже надійний, мудрі системні адміністратори повинні знайти спосіб постійно стежити за поведінкою та використанням системи. Забезпечення безперебійної роботи максимально близько 100% наскільки це можливо, а наявність ресурсів є критичною потребою у багатьох середовищах. Вивчення минулого та поточного стану системи дозволить нам передбачити та, швидше за все, запобігти можливим проблемам.

Представляємо програму сертифікації Linux Foundation
У цій статті ми наведемо перелік кількох інструментів, доступних у більшості дистрибутивів у потоці, для перевірки стану системи, аналізу перебоїв у роботі та усунення поточних проблем. Зокрема, з незліченної кількості доступних даних ми зосередимось на процесорі, обсязі пам’яті та використанні пам’яті, базовому управлінні процесами та аналізі журналів.
У Linux є 2 добре відомі команди, які використовуються для перевірки використання місця для зберігання: df та du.
Перший, df (що означає «вільний диск»), зазвичай використовується для звітування про загальне використання дискового простору файловою системою.
Без варіантів, df повідомляє про використання дискового простору в байтах. З -ч прапорець, він відображатиме ту саму інформацію, використовуючи MB або GB. Зауважте, що цей звіт також містить загальний розмір кожної файлової системи (у блоках 1-K), вільні та доступні місця та точку монтування кожного пристрою зберігання.
# df. # df -h.

Це, звичайно, приємно - але є ще одне обмеження, яке може зробити файлову систему непридатною, і це закінчується inodes. Усі файли у файловій системі зіставляються з анодом, що містить його метадані.
# df -hTi.
Ви можете побачити кількість використаних та доступних індодексів:
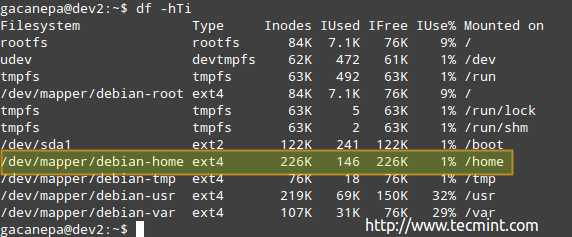
Відповідно до наведеного вище зображення, існують 146 використані inodes (1%) in /home, що означає, що ви все ще можете створити 226K файлів у цій файловій системі.
Зауважте, що ви можете вичерпати місце для зберігання даних задовго до того, як закінчиться inodes, і навпаки. З цієї причини вам потрібно стежити не тільки за використанням місця для зберігання, але і за кількістю індексів, що використовуються файловою системою.
Використовуйте наведені нижче команди, щоб знайти порожні файли або каталоги (які займають 0B), які без причини використовують inodes:
# find /home -type f -порожній. # find /home -type d -порожній.
Також ви можете додати -видалити позначити в кінці кожної команди, якщо ви також хочете видалити ці порожні файли та каталоги:
# find /home -type f -empty --delete. # find /home -type f -порожній.
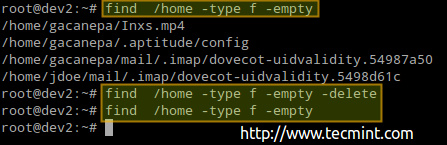
Попередня процедура видалила 4 файли. Давайте ще раз перевіримо кількість використаних / доступних вузлів знову в / home:
# df -hTi | бігти додому.

Як бачите, є 142 зараз використовується inodes (на 4 менше, ніж раніше).
Якщо використання певної файлової системи перевищує заздалегідь визначений відсоток, можна використовувати du (скорочення від використання диска), щоб дізнатися, які файли займають найбільше місця.
Приклад наведено для /var, який, як ви бачите на першому зображенні вище, використовується на 67%.
# du -sch /var /*
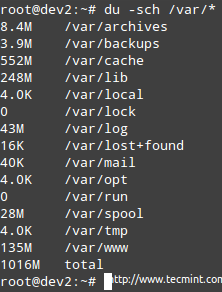
Примітка: Ви можете перейти до будь -якого з вищевказаних підкаталогів, щоб точно дізнатися, що в них є, і скільки кожен елемент займає. Потім ви можете використати цю інформацію, щоб видалити деякі файли, якщо вони не потрібні, або за потреби збільшити розмір логічного тому.
Читайте також
Класичний інструмент у Linux, який використовується для загальної перевірки використання процесора / пам'яті та управління процесами верхня команда. Крім того, зверху відображається перегляд працюючої системи в режимі реального часу. Існують інші інструменти, які можна використовувати з тією ж метою, наприклад htop, але я зупинився на найвищому, тому що він встановлюється в будь-якому дистрибутиві Linux.
Щоб почати зверху, просто введіть таку команду у своєму командному рядку та натисніть Enter.
# зверху.
Давайте розглянемо типовий верхній вихід:
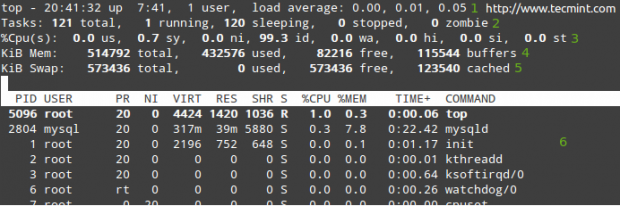
У рядках 1-5 відображається така інформація:
1. Поточний час (20:41:32 вечора) та час безперебійної роботи (7 годин 41 хвилина). У систему ввійшов лише один користувач, і середнє навантаження протягом останніх 1, 5 та 15 хвилин відповідно. 0,00, 0,01 і 0,05 вказують на те, що протягом цих часових інтервалів система простоювала протягом 0% часу (0,00: жодних процесів не було очікування на процесор), то він був перевантажений на 1% (0,01: в середньому 0,01 процесів чекали на процесор) і 5% (0.05). Якщо менше 0 і менше число (наприклад, 0,65), система не працювала протягом 35% протягом останніх 1, 5 або 15 хвилин, залежно від того, де з'являється 0,65.
2. Наразі працює 121 процес (повний перелік можна побачити у 6). Тільки 1 з них працює (в цьому випадку верхнє, як ви можете бачити у стовпці %CPU), а решта 120 чекають у фоновому режимі, але "сплять" і залишаться в такому стані, поки ми їм не зателефонуємо. Як? Ви можете перевірити це, відкривши запит mysql і виконавши пару запитів. Ви помітите, як збільшується кількість запущених процесів.
Крім того, ви можете відкрити веб -браузер і перейти до будь -якої сторінки, яка обслуговується Apache, і ви отримаєте той самий результат. Звичайно, ці приклади припускають, що обидві служби встановлені на вашому сервері.
3. us (час роботи користувача з процесами з незміненим пріоритетом), sy (час роботи процесів ядра), ni (час роботи користувачів із зміненим пріоритетом), wa (час очікування введення -виведення завершення), привіт (час, витрачений на обслуговування апаратних переривань), si (час, витрачений на обслуговування програмних переривань), st (час, вкрадений з поточної віртуальної машини гіпервізором - лише у віртуалізованому середовища).
4. Використання фізичної пам’яті.
5. Обмін місцями.
Для перевірки оперативної пам’яті та використання підкачки також можна скористатися безкоштовно команду.
# безкоштовно.

Звичайно, ви також можете використовувати -м (МБ) або -g (GB) перемикає для відображення тієї самої інформації у зчитуваній людиною формі:
# безкоштовно -м.

У будь -якому випадку вам потрібно знати про те, що ядро зберігає якомога більше пам’яті і робить її доступною для процесів, коли вони цього запитують. Зокрема, "-/+ буфери/кеш”Рядок показує фактичні значення після того, як цей кеш вводу -виводу врахований.
Іншими словами, обсяг пам'яті, що використовується процесами, і обсяг, доступний для інших процесів (у цьому випадку, 232 МБ використовували і 270 МБ доступні відповідно). Коли процесам потрібна ця пам'ять, ядро автоматично зменшить розмір кешу вводу -виводу.
Читайте також: 10 Корисна «безкоштовна» команда для перевірки використання пам’яті Linux
У будь -який момент часу в нашій системі Linux працює багато процесів. Для того, щоб уважно стежити за процесами, ми будемо використовувати два інструменти: ps та pstree.
Використовуючи -е та -f варіанти, об'єднані в один (-еф) Ви можете перерахувати всі процеси, які зараз виконуються у вашій системі. Ви можете передати цей результат іншим інструментам, таким як grep (як пояснюється в Частина 1 серії LFCS), щоб звузити вихід до бажаного процесу (-ів):
# ps -ef | grep -i кальмар | grep -v grep.
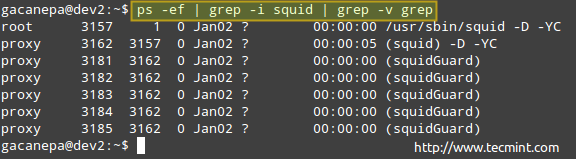
Перелік процесу вище показує таку інформацію:
власник процесу, PID, батьківський PID (батьківський процес), використання процесора, час початку команди, tty (? вказує, що це демон), накопичений час процесора та команда, пов'язана з процесом.
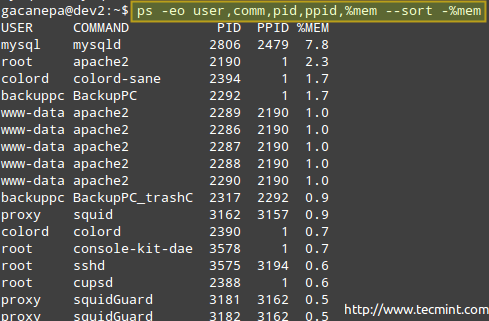
Однак, можливо, вам не потрібна вся ця інформація, і ви хотіли б показати власнику процесу, команду, яка його розпочала, його PID та PPID, та відсоток пам’яті, який він зараз використовує, - у такому порядку та сортувати за використанням пам’яті у порядку зменшення (зверніть увагу, що ps за замовчуванням відсортовано за PID).
# ps -eo user, comm, pid, ppid,%mem --sort -%mem.
Де знак мінус перед %mem вказує на сортування в порядку спадання.
Якщо з якоїсь причини процес починає забирати занадто багато системних ресурсів, і це може загрожувати загальному функціональності системи, ви хочете зупинити або призупинити її виконання, передавши один із наведених нижче сигналів за допомогою вбити програму до нього. Інші причини, чому ви вирішили б це зробити, - це коли ви розпочали процес на передньому плані, але хочете призупинити його та відновити у фоновому режимі.
| Назва сигналу | Номер сигналу | Опис |
| SIGTERM | 15 | Витончено вбийте процес. |
| SIGINT | 2 | Це сигнал, який надсилається, коли ми натискаємо Ctrl + C. Він має на меті перервати процес, але процес може ігнорувати його. |
| SIGKILL | 9 | Цей сигнал також перериває процес, але робить це беззастережно (використовуйте з обережністю!), Оскільки процес не може його ігнорувати. |
| ВІДМІТ | 1 | Скорочене від «Замовкнути», цей сигнал вказує демонам перечитати файл конфігурації, не зупиняючи процес. |
| SIGTSTP | 20 | Призупиніть виконання та почекайте, щоб продовжити. Це сигнал, який надсилається, коли ми вводимо комбінацію клавіш Ctrl + Z. |
| SIGSTOP | 19 | Процес призупинено і не привертає більше уваги з боку циклів процесора, поки він не перезапуститься. |
| SIGCONT | 18 | Цей сигнал повідомляє процесу відновлення виконання після отримання або SIGTSTP, або SIGSTOP. Це сигнал, який надсилає оболонка, коли ми використовуємо команди fg або bg. |
Коли нормальне виконання певного процесу передбачає, що жоден вихід не надсилатиметься на екран, поки він є запущеного, ви можете або почати його у фоновому режимі (додавши амперсанд у кінці команда).
ім'я_процесу &
або,
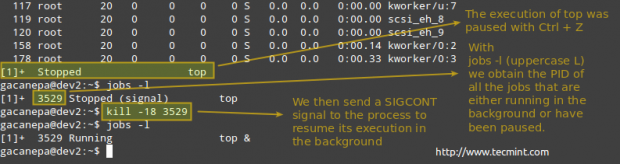
Як тільки він почне працювати на передньому плані, призупиніть його та надішліть на задній план за допомогою
Ctrl + Z.
# kill -18 PID.
Зверніть увагу, що кожен дистрибутив надає інструменти для витонченої зупинки / запуску / перезапуску / перезавантаження загальних служб, таких як обслуговування у системах на базі SysV або systemctl у системах на основі systemd.
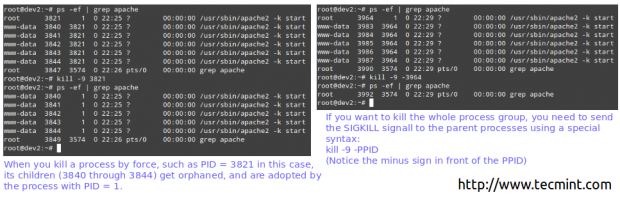
Якщо процес не реагує на ці утиліти, ви можете вбити його силою, надіславши йому сигнал SIGKILL.
# ps -ef | grep apache. # вбити -9 3821.
Якщо в системі стався будь -який збій (будь то відключення електроенергії, збій обладнання, заплановане або незаплановане переривання процесу або взагалі будь -які порушення), журнали в /var/log є твоїми найкращими друзями, щоб визначити, що сталося або що могло спричинити проблеми, з якими ти стикаєшся.
# cd /var /log.

Деякі елементи в /var/log є звичайними текстовими файлами, інші - це каталогами, а треті - стиснутими файлами поворотних (історичних) журналів. Ви захочете перевірити тих, у кого в назві є помилка, але інший може також стати в нагоді.
Уявіть собі цей сценарій. Ваші клієнти LAN не можуть друкувати на мережевих принтерах. Першим кроком для усунення цієї ситуації буде /var/log/cups каталог і подивіться, що там є.
Ви можете використовувати хвіст команда для відображення останніх 10 рядків файлу error_log, або tail -f error_log для перегляду журналу в режимі реального часу.
# cd/var/log/cup. # ls. # хвост error_log.
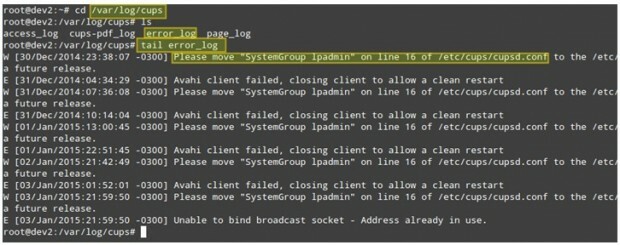
Знімок екрана вище містить деяку корисну інформацію, щоб зрозуміти, що може стати причиною вашої проблеми. Зауважте, що виконання кроків або виправлення несправності процесу все ще може не вирішити загальну проблему, але якщо ви звикли з самого початку перевіряти журнали щоразу, коли виникає проблема (будь то локальна чи мережева), ви точно будете праворуч трек.
Хоча несправності обладнання можуть бути складними для усунення несправностей, ви повинні перевірити dmesg журнали повідомлень та grep для відповідних слів до апаратної частини, що вважається несправною.
Зображення нижче взято з /var/log/messages після пошуку слова помилка за допомогою такої команди:
# менше/var/log/messages | Помилка grep -i.
Ми бачимо, що у нас є проблема з двома пристроями зберігання: /dev/sdb та /dev/sdc, що в свою чергу спричиняє проблеми з масивом RAID.

У цій статті ми розглянули деякі інструменти, які можуть допомогти вам завжди бути в курсі загального стану вашої системи. Крім того, вам потрібно переконатися, що ваша операційна система та встановлені пакети оновлені до останніх стабільних версій. І ніколи, ніколи не забувайте перевіряти журнали! Тоді ви рухатиметесь у правильному напрямку, щоб знайти остаточне вирішення будь -яких питань.
Не соромтеся залишати свої зауваження, пропозиції чи запитання, якщо у вас є такі, використовуючи форму нижче.

