
Podatki že stoletja igrajo pomembno vlogo v našem življenju. Vsak dan ustvarimo 2,5 kvintiljona bajtov podatkov. To pomeni, da je bilo 90% svetovnih podatkov ustvarjenih samo v zadnjih dveh letih. In ta obsežen obsežen nabor podatkov, ki je tako velik, da ga ni mogoče analizirati s tradicionalnimi metodami, se imenuje Big Data. Za pregled teh strukturiranih in nestrukturiranih podatkov se uporablja tehnika analitike Big Data.
V tem članku bomo razpravljali o tem, kakšna je ta velika količina podatkov, kaj je Big Data Analytics in zakaj je pomembna.
Ta in številna druga vprašanja se nam porajajo, ko iščemo odgovor na to, kaj so veliki podatki? Ok, zadnje vprašanje morda ni tisto, kar vprašate, vendar obstajajo tudi druga.
Tu bomo torej opredelili, kaj je to, kakšen je njegov namen ali vrednost in zakaj uporabljamo to veliko količino podatkov.
Podjetja danes iščejo nove in boljše načine, kako ostati konkurenčna, donosna in pripravljena na prihodnost, in, po mnenju strokovnjakov iz panoge analitika Big Data ponuja načine, kako se naučiti novih idej, pridobiti nov vpogled in iti naprej krivulja.
Veliki podatki se nanaša na ogromen obseg strukturiranih in nestrukturiranih podatkov, ki vsakodnevno prevladajo nad podjetji. Vendar ni pomembna velikost podatkov, pomembno je, kako se uporabljajo in obdelujejo. Lahko ga analiziramo z uporabo analitike velikih podatkov za sprejemanje boljših strateških odločitev za podjetja.
Po Gartnerju:
Veliki podatki so obsežna, hitrostna in raznovrstna informacijska sredstva, ki zahtevajo stroškovno učinkovite, inovativne oblike obdelave informacij za boljši vpogled in odločanje.
Najboljši način za razumevanje stvari je poznavanje njene zgodovine.
Podatki obstajajo že leta; a koncept se je v začetku 2000-ih zaželel in od takrat so podjetja začela zbirati informacije in voditi analitiko velikih podatkov, da bi razkrila podrobnosti za prihodnjo uporabo. S tem organizacijam omogočijo hitro delo in gibčnost.
To je bil čas, ko je Doug Laney te podatke opredelil kot tri V (prostornina, hitrost in raznolikost):

Glasnost: je količina podatkov, premeščenih iz gigabajtov v terabajtov in več.
Hitrost: Hitrost obdelave podatkov je hitrost.
Raznolikost: podatki so različnih vrst, od strukturiranih do nestrukturiranih. Strukturirani podatki so ponavadi številčni, medtem ko so nestrukturirani - besedilo, dokumenti, e-pošta, video, zvok, finančne transakcije itd.

Kjer so ti trije V-ji olajšali razumevanje velikih podatkov, so celo jasno povedali, da ravnanje s to veliko količino podatkov s tradicionalnim ogrodjem ne bo enostavno. To je bil čas, ko je nastal Hadoop in nekatera vprašanja, kot so:
Vsi ti so nastali.
Začnimo jim odgovarjati.
Za primer vzemimo analogijo restavracij, da razumemo razmerje med velikimi podatki in Hadoopom
Tom je pred kratkim odprl restavracijo s kuharjem, kjer prejme 2 naročili na dan, tako da lahko enostavno ravna z njimi, tako kot RDBMS. Toda sčasoma je Tom pomislil, da bi razširil posel in tako pritegnil več kupcev, zato je začel sprejemati spletna naročila. Zaradi te spremembe se je stopnja, s katero je prejemal naročila, povečala in zdaj je namesto 2 začel prejemati 10 naročil na uro. Enako se je zgodilo s podatki. Z uvedbo različnih virov, kot so pametni telefoni, družbeni mediji itd., Je rast podatkov postala velika, vendar zaradi nenadne spremembe obdelava velikih naročil / podatkov ni enostavna. Zato se pojavlja potreba po drugačni strategiji za obvladovanje tega problema.
Tom se je zavedal te situacije in začel razmišljati o rešitvi. Podobno so se z napredovanjem tehnologije začeli generirati podatki z zaskrbljujočo hitrostjo. Za izvedbo velikega števila naročil je Tom najel še 4 kuharje. Vse je šlo dobro, a ker je bila polica s hrano, ki so jo uporabljali 4 kuharji, enaka, je postajala ozko grlo, zato rešitev ni bila tako učinkovita
Za reševanje podatkovnih težav so bili nameščeni več procesnih enot, vendar tudi to ni bilo učinkovito, saj je centralizirana enota za shranjevanje postala ozko grlo. To pomeni, da če se centralizirana enota spusti, je celoten sistem ogrožen. Zato je bilo treba poiskati boljšo rešitev za podatke in restavracije.
Tom je prišel z učinkovito rešitvijo, kuharje je razdelil na dve hierarhiji, torej mlajši in glavni kuhar, in vsakemu mlajšemu kuharju dodelil polico s hrano. Recimo, da je jed na primer testeninska omaka. Zdaj bo po Tomovem načrtu en mlajši kuhar pripravil testenine, drugi mlajši kuhar pa omako. V nadaljevanju bodo predali testenine in omako glavnemu kuharju, kjer bo glavni kuhar po združitvi obeh sestavin pripravil testeninsko omako, končno naročilo pa bo dostavljeno. Ta rešitev je odlično delovala za Tomovo restavracijo, za Big Data pa Hadoop.
Hadoop je odprtokodni programski okvir, ki se uporablja za shranjevanje in obdelavo podatkov na porazdeljen način v velikih grozdih blagovne strojne opreme. Hadoop podatke shranjuje porazdeljeno z replikacijami, da zagotovi odpornost na napake in končni rezultat, ne da bi se soočil z ozkimi grli. Zdaj ste morali imeti idejo, kako Hadoop rešuje problem velikih podatkov, tj.
Torej to pomeni, da sta Big Data in Hadoop enaka?
Tega ne moremo reči, saj obstajajo razlike med obema.
Zdaj, ko vemo, kakšni so ti podatki, kako delujejo Hadoop in veliki podatki. Čas je, da vemo, kako imajo podjetja koristi od teh podatkov.
Nekaj primerov, ki pojasnjujejo, kako ti veliki podatki podjetjem pomagajo pridobiti dodatno prednost:
Coca-Cola je podjetje, ki ga ni treba predstavljati. To podjetje je že stoletja vodilno v potrošniškem pakiranju. Vsi njeni izdelki se distribuirajo po vsem svetu. Ena stvar, zaradi katere je Coca Cola zmagala, so podatki. Ampak kako?
Coca Cola in veliki podatki:
Z uporabo zbranih podatkov in njihovo analizo s pomočjo analitike velikih podatkov se Coca Cola lahko odloči za naslednje dejavnike:
Da bi ostal pred drugimi storitvami pretakanja videov, Netflix nenehno analizira trende in poskrbi, da ljudje dobijo tisto, kar iščejo na Netflixu. Podatke iščejo v:
Za mnoga podjetja za pretakanje video posnetkov in zabavo je analitika velikih podatkov ključnega pomena naročnikov, si zagotovite prihodek in razumete vrsto vsebine, ki jo imajo gledalci, na podlagi geografskih lokacijah. Ti obsežni podatki ne samo, da Netflixu omogočajo to sposobnost, ampak celo pomagajo drugim storitvam za pretakanje videoposnetkov, da razumejo, kaj gledalci želijo in kako jih lahko Netflix in drugi dostavijo.
Poleg tega obstajajo podjetja, ki shranjujejo naslednje podatke, ki analitiki velikih podatkov pomagajo do natančnih rezultatov, kot so:
Hmm, tako podjetja vedo o našem vedenju in nam oblikujejo storitve.
Proces preučevanja in proučevanja velikih naborov podatkov za razumevanje vzorcev in pridobivanje vpogledov se imenuje analitika velikih podatkov. Vključuje algoritemski in matematični postopek za pridobitev smiselne korelacije. Analiza podatkov se osredotoča na sklepe, ki temeljijo na znanju raziskovalcev.
V idealnem primeru veliki podatki obdelujejo napovedi / napovedi obsežnih podatkov, zbranih iz različnih virov. To podjetjem pomaga do boljših odločitev. Nekatera področja, na katerih se uporabljajo podatki, so strojno učenje, umetna inteligenca, robotika, zdravstvo, navidezna resničnost in različna druga področja. Zato moramo poskrbeti, da bodo podatki neredni in organizirani.
To daje organizacijam priložnost, da se spremenijo in rastejo. In zato postaja analitika velikih podatkov priljubljena in je izjemnega pomena. Glede na naravo ga lahko razdelimo na 4 različne dele:

Poleg tega imajo veliki podatki pomembno vlogo tudi na naslednjih področjih:
Zdaj, ko vemo, na katerih vseh področjih imajo podatki pomembno vlogo. Čas je, da razumemo, kako delujejo veliki podatki in njihovi 4 različni deli.
Analiza podatkov vključuje uporabo naprednih tehnik in orodij, kot so strojno učenje, rudarjenje podatkov, statistika. Tako pridobljeni podatki iz različnih virov in v različnih velikostih se uporabljajo za analizo.
Podatkovne znanosti pa so krovni izraz, ki vključuje znanstvene metode za obdelavo podatkov. Podatkovne znanosti združujejo več področij, kot so matematika, čiščenje podatkov itd., Za pripravo in poravnavo velikih podatkov.

Zaradi zapletenosti podatkov je znanost o podatkih precej zahtevna, vendar se z naraščajočo rastjo informacij po vsem svetu razvija tudi koncept obsežnih podatkov. Zato je področje podatkovnih ved, ki vključuje velike podatke, neločljivo. Podatki zajemajo strukturirane, nestrukturirane informacije, medtem ko so podatkovne vede bolj usmerjen pristop, ki vključuje posebna znanstvena področja.
Zaradi naraščanja povpraševanja se uporaba orodij za analizo podatkov povečuje, saj organizacijam pomagajo najti nove priložnosti in pridobiti nove vpoglede za učinkovito poslovanje.
Poleg tega lahko s poudarkom na strankah stranke izboljšajo svoje poslovanje in zaslužijo več dobička. Orodja, kot je Hadoop, pomagajo zmanjšati stroške shranjevanja. S tem se poveča poslovna učinkovitost, to pa prihrani denar, energijo in hitrejše odločitve.
Podatki v preteklih letih beležijo izjemno rast, zaradi katere se je povečala uporaba podatkov v panogah, od:

Vse skupaj je danes podatkovna analitika postala bistveni del podjetij.
Podatki so skoraj povsod, zato je nujno treba zbrati in ohraniti vse ustvarjene podatke. Zato je analitika velikih podatkov na mejah informacijske tehnologije in je postala ključna pri izboljšanju poslovanja in sprejemanju odločitev. Strokovnjaki, ki so usposobljeni za analizo podatkov, imajo ogromno priložnosti. Ker so ti tisti, ki lahko premostijo vrzel med tradicionalnimi in novimi tehnikami poslovne analitike, ki podjetjem pomagajo pri rasti.
Nobena posamezna tehnologija ne more zajemati velikih podatkov, vendar je za njihovo največjo možno vrednost mogoče uporabiti napredno analitiko velikih podatkov.
Tu so največji igralci:
Strojno učenje: Strojno učenje, usposobi stroj za učenje in analizo večjih in bolj zapletenih podatkov za hitrejše in natančnejše rezultate. Z uporabo podskupine strojnega učenja organizacij umetne inteligence lahko prepoznate donosne priložnosti - izognete se neznanim tveganjem.
Upravljanje podatkov: S podatki, ki nenehno prihajajo v organizacijo in iz nje, moramo vedeti, ali so kakovostni in jih je mogoče zanesljivo analizirati. Ko so podatki zanesljivi, se za upravljanje organizacije na isti strani in analizo podatkov uporablja program za upravljanje glavnih podatkov.

Podatkovno rudarjenje: Tehnologija podatkovnega rudarjenja pomaga analizirati skrite vzorce podatkov, tako da jih je mogoče uporabiti v nadaljnji analizi, da dobite odgovor na zapletena poslovna vprašanja. Podjetja lahko z uporabo algoritma za podatkovno rudarjenje sprejemajo boljše odločitve in lahko celo določajo težavna področja za povečanje prihodkov z zniževanjem stroškov. Podatkovno rudarjenje je znano tudi kot odkrivanje podatkov in odkrivanje znanja.
Hadoop: Hadoop je odprtokodna programska oprema, ki pomaga organizirano upravljati obdelavo podatkov in shranjevanje podatkovnih aplikacij na računalniških strežnikih. Hadoop je postal ključna tehnologija, ki podpira napredne pobude za analizo velikih podatkov, vključno s strojnim učenjem, podatkovnim rudarjenjem itd. Sistem Hadoop lahko obdeluje različne oblike strukturiranih in nestrukturiranih podatkov, kar daje dodatno prednost za enostavno zbiranje, obdelavo in analizo podatkov.
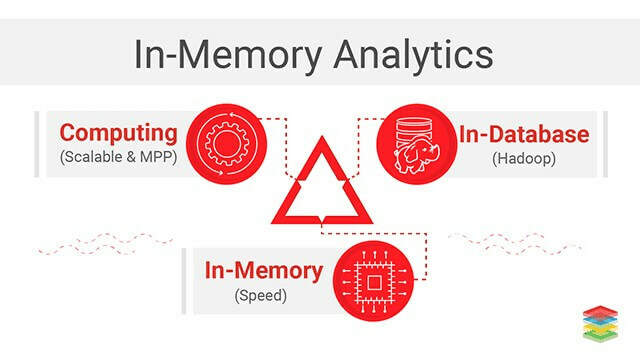
Analiza v pomnilniku: Ta metodologija poslovne inteligence (BI) se uporablja za reševanje zapletenih poslovnih problemov. Z analizo podatkov iz sistemskega pomnilnika računalnika lahko odzivni čas poizvedbe skrajšate in sprejmete hitrejše poslovne odločitve. Ta tehnologija celo odpravlja režijske stroške shranjevanja zbirnih tabel podatkov ali indeksiranja podatkov, kar ima za posledico hitrejši odzivni čas. Ne samo, da ta analitika v pomnilniku celo pomaga organizaciji pri izvajanju iterativne in interaktivne analitike velikih podatkov.
Napovedovalna analitika: Predvidevalna analitika je metoda pridobivanja informacij iz obstoječih podatkov za določanje in napovedovanje prihodnjih rezultatov in trendov. tehnike, kot so podatkovno rudarjenje, modeliranje, strojno učenje, umetna inteligenca, se uporabljajo za analizo trenutnih podatkov za napovedi v prihodnosti. Predvidevalna analitika omogoča organizacijam, da postanejo proaktivne, predvidevajo prihodnost, predvidevajo izid itd. Poleg tega gre še dlje in predlaga ukrepe, ki bodo koristili napovedi, in tudi odločitev, da bodo koristili napovedim in posledicam.

Iskanje besedil: Besedilo besedila, ki se imenuje tudi besedilo, je postopek pridobivanja visokokakovostnih informacij iz nestrukturiranih besedilnih podatkov. S tehnologijo rudarjenja besedil odkrijete vpoglede, ki jih prej niste opazili. Rudarjenje besedil uporablja strojno učenje in je za znanstvenike in druge uporabnike bolj praktično razvijati platforme za velike podatke in pomagati pri analizi podatkov za odkrivanje novih tem.
Vsako minuto se ustvari ogromno podatkov, zato postaja zahtevno delo za njihovo shranjevanje, upravljanje, uporabo in analizo. Tudi velika podjetja se z upravljanjem in shranjevanjem podatkov borijo za ogromno količino podatkov. Te težave ni mogoče rešiti s preprostim shranjevanjem podatkov, zaradi katerih morajo organizacije prepoznati izzive in si prizadevati za njihovo reševanje:
Big Data ni uporaben za organizacijo podatkov, vendar podjetjem prinaša celo številne koristi. Prvih pet je:
S tem lahko sklepamo, da ni nobene posebne opredelitve, kaj so veliki podatki, vendar se vseeno strinjamo, da je velika količina podatkov velik podatek. Sčasoma se pomen analitike velikih podatkov povečuje, saj pomaga izboljšati znanje in prinaša donosne zaključke.
Če želite izkoristiti velike količine podatkov, vam bo zagotovo pomagala uporaba Hadoop-a. Ker gre za metodo, ki zna obvladovati velike podatke in jih narediti razumljive.