Po celé storočia hrajú údaje v našich životoch dôležitú úlohu. To znamená, že každý deň vytvoríme 2,5 kvintiliónu bajtov údajov. To znamená, že 90% svetových údajov bolo vytvorených iba za posledné dva roky. A táto obrovská objemná množina dát, ktorá je taká veľká, že ju nemožno analyzovať pomocou tradičných metód, sa nazýva Big Data. Na preskúmanie týchto štruktúrovaných a neštruktúrovaných údajov sa používa technika analýzy veľkých dát.
V tomto článku si rozoberieme, čo je to veľký objem dát, čo je Big Data Analytics a prečo je to dôležité.
Tieto a niekoľko ďalších otázok nás napadne, keď hľadáme odpoveď na otázku, čo sú veľké dáta? Dobre, posledná otázka nemusí byť to, na čo sa pýtate, ale iné sú možnosti.
Preto tu definujeme, čo to je, aký je jeho účel alebo hodnota a prečo používame tento veľký objem údajov.
Podniky dnes hľadajú nové a lepšie spôsoby, ako zostať konkurencieschopnými, ziskovými a pripravenými na budúcnosť, a podľa odborníkov v odbore analýza veľkých dát ponúka spôsoby, ako sa naučiť nové nápady, získať nový prehľad a udržať si náskok krivka.
Veľké dáta sa vzťahuje na obrovské množstvo štruktúrovaných aj neštruktúrovaných údajov, ktoré dennodenne premáhajú podniky. Nezáleží však na veľkosti dát, dôležité je, ako sa používajú a spracovávajú. Môže byť analyzovaný pomocou analýzy veľkých dát, aby bolo možné podniknúť lepšie strategické rozhodnutia pre presun.
Podľa Gartnera:
Veľké dáta sú veľké objemy, vysoké rýchlosti a rozmanité informačné aktíva, ktoré si vyžadujú nákladovo efektívne a inovatívne formy spracovania informácií pre lepší prehľad a rozhodovanie.
Najlepší spôsob, ako pochopiť vec, je poznať jej históriu.
Údaje existujú už roky; ale tento koncept nabral na obrátkach začiatkom roku 2000 a odvtedy začali podniky zhromažďovať informácie, spustiť analýzu veľkých dát a odhaliť podrobnosti pre budúce použitie. Týmto dáva organizáciám schopnosť pracovať rýchlo a zostať svižní.
To bol čas, kedy Doug Laney definoval tieto údaje ako tri V (objem, rýchlosť a rozmanitosť):

Objem: je množstvo dát presunutých z gigabajtov do terabajtov a viac.
Rýchlosť: Rýchlosť spracovania údajov je rýchlosť.
Odroda: dáta prichádzajú v rôznych druhoch od štruktúrovaných po neštruktúrované. Štruktúrované údaje sú zvyčajne číselné, zatiaľ čo neštrukturované - text, dokumenty, e-mail, video, zvuk, finančné transakcie atď.

Tam, kde tieto tri V uľahčili pochopenie veľkých dát, dokonca objasnili, že manipulácia s týmto veľkým objemom dát pomocou tradičného rámca nebude ľahká. To bolo v čase, keď Hadoop existoval a niektoré otázky ako:
Všetky tieto vznikli.
Takže poďme na ne odpovedať.
Zoberme si analogiu reštaurácie ako príklad na pochopenie vzťahu medzi big data a Hadoop
Tom nedávno otvoril reštauráciu so šéfkuchárom, kde prijíma 2 objednávky denne, takže tieto objednávky ľahko vybaví, rovnako ako RDBMS. Ale časom Tom myslel na rozšírenie podnikania a tým aj na zapojenie ďalších zákazníkov, začal prijímať objednávky online. Z dôvodu tejto zmeny sa zvýšila rýchlosť prijímania objednávok a teraz namiesto dvoch začal dostávať 10 objednávok za hodinu. To isté sa stalo s dátami. So zavedením rôznych zdrojov, ako sú smartfóny, sociálne médiá atď., Sa rast dát stal obrovským, ale z dôvodu náhlej zmeny nie je ľahké vybaviť veľké objednávky / dáta. Preto vzniká potreba iného druhu stratégie na vyrovnanie sa s týmto problémom.
Uvedomujúc si túto situáciu začal Tom vymýšľať riešenie. Podobne s vývojom technologických údajov sa začali generovať alarmujúcou rýchlosťou. Aby zvládol veľkú mieru objednávok, Tom najal ďalších 4 kuchárov. Všetko šlo dobre, ale keďže polička na potraviny, ktorú používali 4 kuchári, bola rovnaká, stal sa úzkym hrdlom, takže riešenie nebolo také efektívne
Rovnako bolo v záujme riešenia problému s dátami spojené s obrovskými súbormi údajov nainštalovaných viac spracovateľských jednotiek, čo však nebolo efektívne, pretože úzkym miestom sa stala centralizovaná úložná jednotka. To znamená, že ak dôjde k výpadku centralizovanej jednotky, dôjde k narušeniu celého systému. Preto bolo potrebné hľadať lepšie riešenie pre dáta aj pre reštauráciu.
Tom prišiel s efektívnym riešením, rozdelil kuchárov do dvoch hierarchií, teda na juniorského a hlavného kuchára a každému juniorskému kuchárovi pridelil poličku na jedlo. Napríklad jedlo je cestovinová omáčka. Teraz, podľa Tomovho plánu, jeden junior kuchár pripraví cestoviny a druhý junior kuchár pripraví omáčku. Vpred odovzdajú cestoviny aj omáčku šéfkuchárovi, kde hlavný kuchár pripraví cestovinovú omáčku po zmiešaní obidvoch ingrediencií. Konečná objednávka bude doručená. Toto riešenie fungovalo perfektne pre reštauráciu Tom a pre veľké dáta to robí Hadoop.
Hadoop je open-source softvérový rámec, ktorý sa používa na ukladanie a spracovanie údajov distribuovaným spôsobom na veľkých klastroch komoditného hardvéru. Spoločnosť Hadoop ukladá údaje distribuovaným spôsobom s replikáciami, aby poskytla odolnosť voči chybám a poskytla konečný výsledok bez toho, aby čelila problémom s úzkym hrdlom. Teraz musíte mať predstavu o tom, ako Hadoop rieši problém veľkých dát, t.j.
Znamená to teda, že Big Data aj Hadoop sú rovnaké?
To nemôžeme povedať, pretože medzi nimi sú rozdiely.
Teraz, keď vieme, čo sú tieto údaje, ako fungujú Hadoop a big data. Je čas vedieť, ako spoločnosti z týchto údajov profitujú.
Niekoľko príkladov na vysvetlenie toho, ako tieto veľké údaje pomáhajú spoločnostiam získať ďalší náskok:
Coca-Cola je spoločnosť, ktorú netreba zvlášť predstavovať. Táto spoločnosť je už po celé storočia lídrom v oblasti spotrebiteľského balenia tovaru. Všetky jej produkty sú distribuované globálne. Jednou z vecí, vďaka ktorej vyhráva Coca Cola, sú dáta. Ale ako?
Coca Cola a veľké dáta:
Na základe zhromaždených údajov a ich analýzy pomocou analýzy veľkých dát je spoločnosť Coca Cola schopná rozhodnúť o nasledujúcich faktoroch:
Aby si udržal náskok pred ostatnými službami pre streamovanie videa, Netflix neustále analyzuje trendy a zaisťuje, aby ľudia na Netflixe dostali to, čo hľadajú. Údaje hľadajú v:
Pre mnoho spoločností poskytujúcich streamovanie videa a zábavu je kľúčom k zachovaniu analýza veľkých dát predplatitelia, zabezpečené výnosy a porozumieť typom prehliadačov obsahu, napríklad na základe geografických údajov umiestnenia. Tieto objemné údaje nielenže dávajú Netflixu túto schopnosť, ale dokonca pomáhajú iným službám streamovania videa pochopiť, čo diváci chcú a ako to môže Netflix a ďalšie poskytnúť.
Vedľa sú spoločnosti, ktoré ukladajú nasledujúce údaje, ktoré pomáhajú analýze veľkých dát poskytovať presné výsledky, ako napríklad:
Hmm, tak takto vedia spoločnosti o našom správaní a navrhujú pre nás služby.
Proces štúdia a skúmania veľkých súborov údajov s cieľom porozumieť vzorom a získať prehľad sa nazýva analýza veľkých údajov. Zahŕňa algoritmický a matematický proces na odvodenie zmysluplnej korelácie. Analýza údajov sa zameriava na vyvodenie záverov založených na poznatkoch vedcov.
V ideálnom prípade veľké dáta spracúvajú predpovede / predpovede rozsiahlych údajov zhromaždených z rôznych zdrojov. To pomáha podnikom robiť lepšie rozhodnutia. Niektoré z oblastí, kde sa používajú dáta, sú strojové učenie, umelá inteligencia, robotika, zdravotníctvo, virtuálna realita a rôzne ďalšie sekcie. Preto musíme udržiavať prehľadnosť a organizovanosť údajov.
Toto dáva organizáciám príležitosť zmeniť sa a rásť. Z tohto dôvodu sa analýza veľkých dát stáva populárnou a je nanajvýš dôležitá. Podľa povahy ho môžeme rozdeliť na 4 rôzne časti:

Okrem toho hrajú veľké dáta dôležitú úlohu aj v týchto oblastiach:
Teraz, keď vieme, v ktorých všetkých poliach zohrávajú údaje dôležitú úlohu. Je čas pochopiť, ako fungujú veľké dáta a ich 4 rôzne časti.
Analýza údajov zahŕňa použitie pokročilých techník a nástrojov, ako je strojové učenie, dolovanie údajov, štatistika. Údaje takto získané z rôznych zdrojov a v rôznych veľkostiach sa používajú na vykonanie analýzy.
Data Sciences je na druhej strane zastrešujúcim pojmom, ktorý zahŕňa vedecké metódy spracovania údajov. Dátové vedy kombinujú viac oblastí ako matematika, čistenie dát atď., Aby pripravili a zosúladili veľké dáta.

Vďaka zložitosti, ktorú s tým súvisia, je dátová veda pomerne náročná, ale s nebývalým rastom generovaných informácií sa vyvíja aj koncept objemných údajov. Preto je oblasť dátových vied, ktoré zahŕňajú veľké dáta, neoddeliteľná. Dáta zahŕňajú štruktúrované a neštruktúrované informácie, zatiaľ čo dátové vedy sú viac zameraným prístupom, ktorý zahŕňa konkrétne vedecké oblasti.
V dôsledku nárastu dopytu rastie využitie nástrojov na analýzu údajov, ktoré pomáhajú organizáciám nájsť nové príležitosti a získať nové poznatky o efektívnom podnikaní.
Navyše zameraním na zákaznícke spoločnosti môžu zlepšiť svoje fungovanie a získať viac ziskov. Nástroje ako Hadoop pomáhajú znižovať náklady na úložisko. Tým sa zvyšuje efektivita podnikania, čo zase vedie k šetreniu peňazí, energie a rýchlejšiemu rozhodovaniu.
Údaje zaznamenali v priebehu rokov obrovský nárast, v dôsledku čoho sa zvýšila spotreba dát v odvetviach od:

Celkovo možno povedať, že dátová analýza sa dnes stala nevyhnutnou súčasťou spoločností.
Údaje sú takmer všade, a preto je nevyhnutné zhromažďovať a uchovávať údaje, ktoré sa generujú. Z tohto dôvodu je analýza veľkých dát na hranici IT a stala sa rozhodujúcou pri zlepšovaní podnikania a rozhodovaní. Profesionáli zruční v analýze údajov dostali oceán príležitostí. Sú to práve oni, ktorí môžu preklenúť priepasť medzi tradičnými a novými technikami podnikovej analýzy, ktoré pomáhajú podnikom rásť.
Žiadna jednotlivá technológia nemôže obsiahnuť veľké dáta, ale na dáta je možné použiť pokročilú analýzu veľkých dát, aby ste z týchto informácií vyťažili maximum.
Tu sú najväčší hráči:
Strojové učenie: Strojové učenie, trénuje stroj, aby sa učil a analyzoval väčšie a zložitejšie údaje, aby priniesol rýchlejšie a presnejšie výsledky. Využitie podmnožiny organizácií AI zameraných na strojové učenie môže identifikovať ziskové príležitosti - vyhnúť sa neznámym rizikám.
Správa údajov: S neustálym prúdením údajov dovnútra a von z organizácie potrebujeme vedieť, či sú údaje vysokej kvality a či je možné ich spoľahlivo analyzovať. Len čo sú údaje spoľahlivé, použije sa program na správu kmeňových údajov, aby sa organizácia dostala na jednu stránku a analyzovala údaje.

Dolovanie dát: Technológia dolovania dát pomáha analyzovať skryté vzorce údajov, aby ich bolo možné použiť v ďalšej analýze na získanie odpovede na zložité obchodné otázky. Vďaka použitiu algoritmu na dolovanie dát môžu podniky robiť lepšie rozhodnutia a dokonca môžu určiť problémové oblasti, aby zvýšili príjmy znížením nákladov. Data mining je tiež známy ako zisťovanie údajov a zisťovanie znalostí.
Hadoop: Hadoop je softvér s otvoreným zdrojovým kódom, ktorý pomáha organizovaným spôsobom spravovať spracovanie a ukladanie dátových aplikácií na počítačových serveroch. Hadoop sa stal kľúčovou technológiou, ktorá podporuje pokročilé iniciatívy v oblasti analýzy veľkých dát vrátane strojového učenia, dolovania dát atď. Systém Hadoop dokáže spracovať rôzne formy štruktúrovaných a neštruktúrovaných údajov, čo poskytuje ďalšiu výhodu v oblasti ľahkého zhromažďovania, spracovania a analýzy údajov.
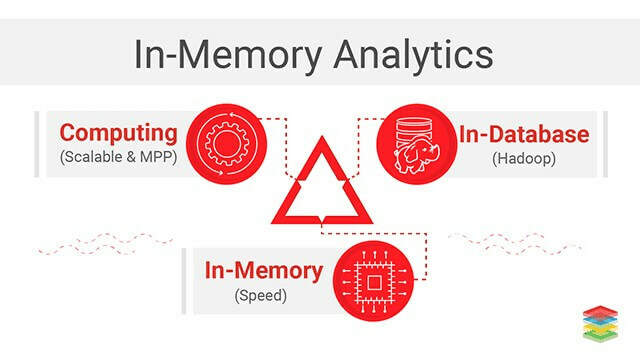
Analýza v pamäti: Táto metodológia business intelligence (BI) sa používa na riešenie zložitých obchodných problémov. Analýzou údajov z pamäte RAM v počítači je možné skrátiť čas odozvy systému a rýchlejšie prijímať obchodné rozhodnutia. Táto technológia dokonca eliminuje réžiu ukladania tabuliek agregujúcich údaje alebo indexovania údajov, čo vedie k rýchlejšej dobe odozvy. Nielen táto analýza v pamäti dokonca pomáha organizácii vykonávať iteratívnu a interaktívnu analýzu veľkých dát.
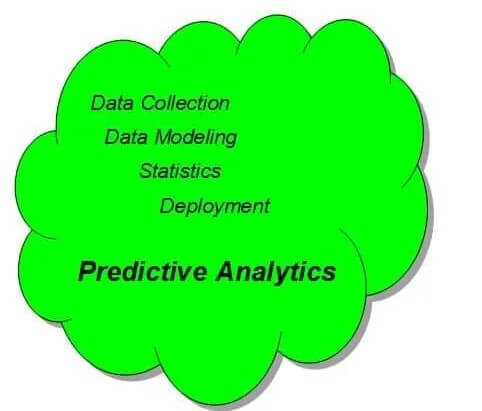
Prediktívna analýza: Prediktívna analýza je metóda získavania informácií z existujúcich údajov s cieľom určiť a predpovedať budúce výsledky a trendy. techniky ako dolovanie dát, modelovanie, strojové učenie, AI sa používajú na analýzu aktuálnych údajov na účely budúcich predpovedí. Prediktívna analýza umožňuje organizáciám stať sa proaktívnymi, predvídať budúcnosť, predvídať výsledok atď. Okrem toho ide ďalej a navrhuje opatrenia, ktoré majú prospech z predpovede, a tiež poskytujú rozhodnutie o výhodách pre jej predpovede a dôsledky.

Dolovanie textu: Dolovanie textu, ktoré sa tiež nazýva dolovanie textových údajov, je proces získavania vysoko kvalitných informácií z neštruktúrovaných textových údajov. Vďaka technológii na dolovanie textu objavujete štatistiky, ktoré ste si predtým nevšimli. Textová ťažba využíva strojové učenie a je pre vedcov v oblasti dát a ďalších používateľov praktickejšia pri vývoji platforiem pre veľké dáta a pri analýze dát s cieľom objavovať nové témy.
Každú minútu sa vyprodukuje obrovské množstvo dát, a preto sa stáva náročnou úlohou ich ukladať, spravovať, využívať a analyzovať. Dokonca aj veľké podniky zápasia so správou a ukladaním údajov, aby dosiahli obrovské množstvo využitia dát. Tento problém nemožno vyriešiť jednoduchým ukladaním údajov, čo je dôvod, prečo organizácie potrebujú na identifikáciu výziev a prácu na ich riešení:
Big Data nie je užitočné organizovať, ale pre podniky dokonca prináša množstvo výhod. Prvých päť je:
S týmto môžeme dospieť k záveru, že neexistuje konkrétna definícia toho, čo sú veľké dáta, ale všetci sa zhodneme na tom, že veľké objemové množstvo dát je big data. Časom tiež rastie dôležitosť analýzy veľkých dát, pretože pomáha rozširovať vedomosti a dospieť k ziskovým záverom.
Ak chcete využívať veľké dáta, potom použitie Hadoop určite pomôže. Ide o metódu, ktorá vie, ako spravovať veľké dáta a urobiť ich zrozumiteľnými.