
Stup este un Depozit de date model în Hadoop Eco-Sistem. Poate funcționa ca un instrument ETL deasupra Hadoop. Activarea disponibilității ridicate (HA) pe Hive nu este similară cu ceea ce facem în Master Services, cum ar fi Namenode și Manager de resurse.
Reluarea automată nu va avea loc în Stup (Hiveserver2). Dacă există Hiveserver2 (HS2) eșuează, rularea lucrărilor pe care a eșuat HS2 va primi eșec. Trebuie să retrimitem jobul, astfel încât jobul să poată rula pe altul HiveServer2. Deci, permițând HA pe HS2 nu este altceva decât creșterea numărului de HS2 componente în Cluster.
În acest articol, vom vedea pașii pentru instalarea și activarea Valabilitate ridicată de Stup.
Să începem…
1. Conectați la Manager Cloudera la adresa URL de mai jos și navigați la Manager Cloudera–>Adăugați un serviciu.
http://13.233.129.39:7180/cmf/home.
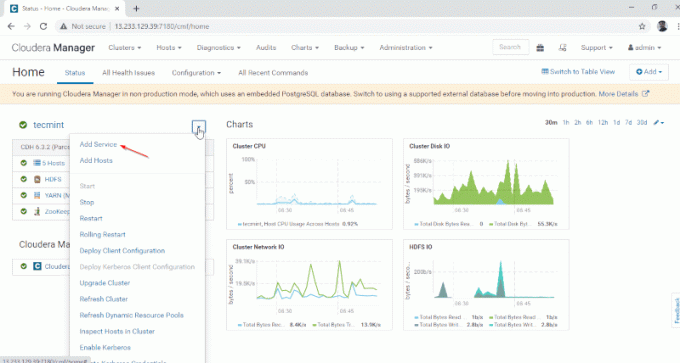
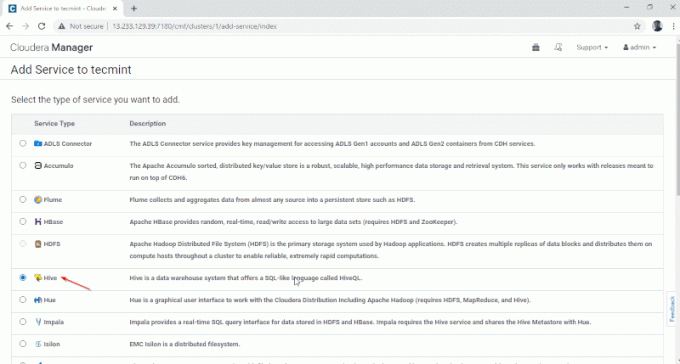
2. Selectați serviciul „Stup‘.
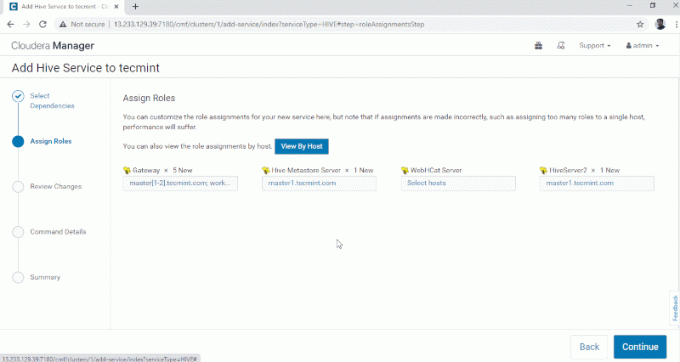
3. Atribuiți serviciile pe noduri.
Odată selectate serverele, faceți clic pe „Continua' a inainta, a merge mai departe.
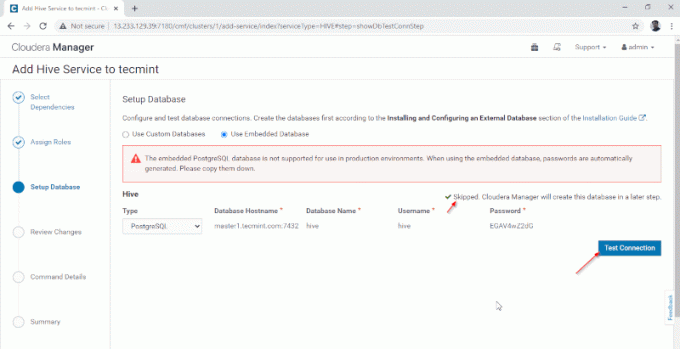
4. Hive Metastore are nevoie de o bază de date de bază pentru stocarea metadatelor. Aici folosim valoarea implicită PostgreSQL baza de date care este încorporată cu CDH.
Detaliile bazei de date menționate mai jos vor fi introduse automat, „Test de conexiune’Va fi omis pe măsură ce baza de date menționată va fi creată din mers. În timp real, trebuie să creăm baza de date în baza de date externă și să testăm conexiunea pentru a continua mai departe. După ce ați terminat, faceți clic pe „Continua’.
5. Configurați fișierul Depozit Hive director, /user/hive/warehouse este calea directoare implicită pentru stocarea tabelelor Hive. Apasă pe 'Continua’.
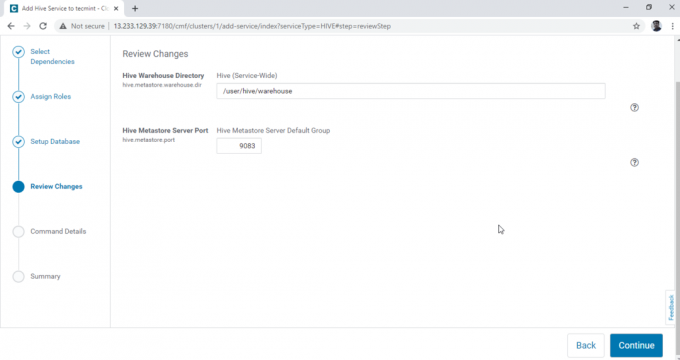
6. Instalarea Hive este începută.
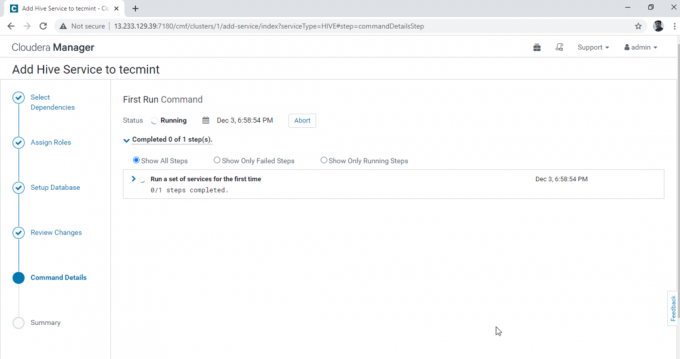
7. După finalizarea instalării, puteți obține „Terminat' stare. Faceți clic pe „Continua'Pentru a continua mai departe.

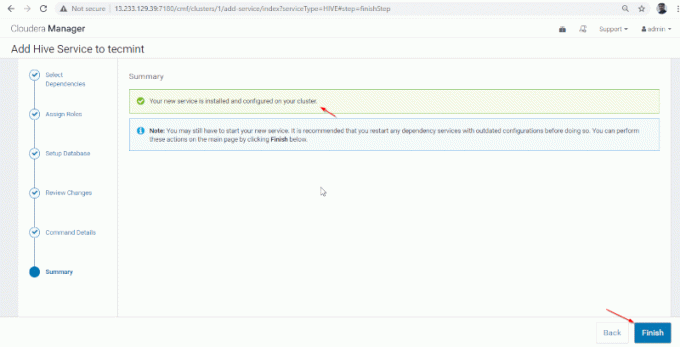
8. Instalarea și configurarea stupului au fost finalizate cu succes. Faceți clic pe „finalizarea‘Pentru a finaliza procedura de instalare.
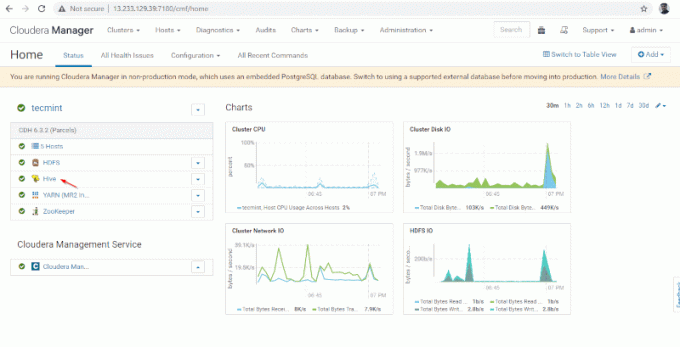
9. Poti vedea Stup serviciu adăugat în Cluster prin Tabloul de bord Cloudera Manager.
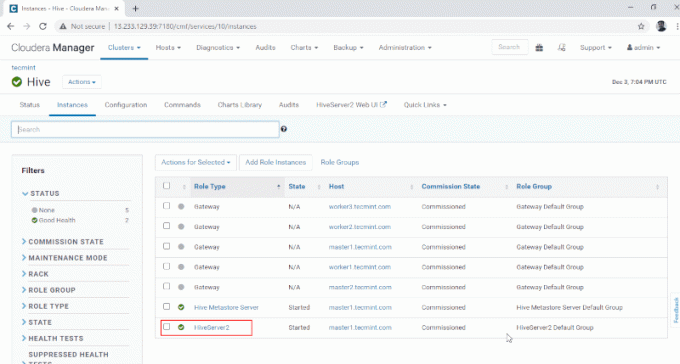
10. Puteți vizualiza Hiveserver2 în Instanțe de Stup. Am adăugat Hiveserver2 în stăpân1.
Manager Cloudera –> Stup –> Instanțe –> Hiveserver2.
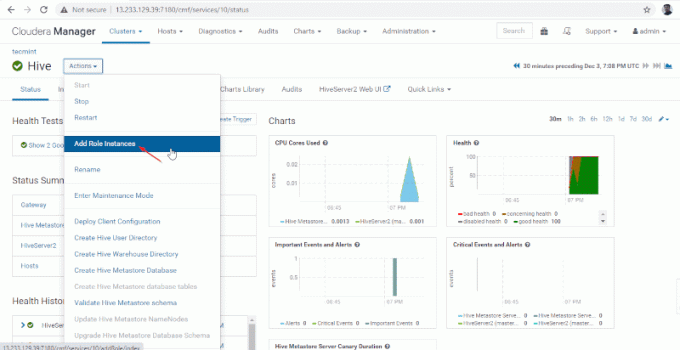
11. Apoi adăugați rolul Hive mergând la Manager Cloudera –> Stup –> Acțiuni –> Adăugați un rol Instanțe.
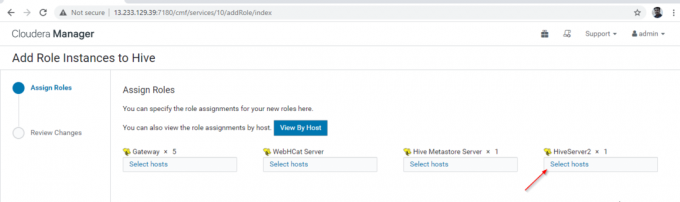
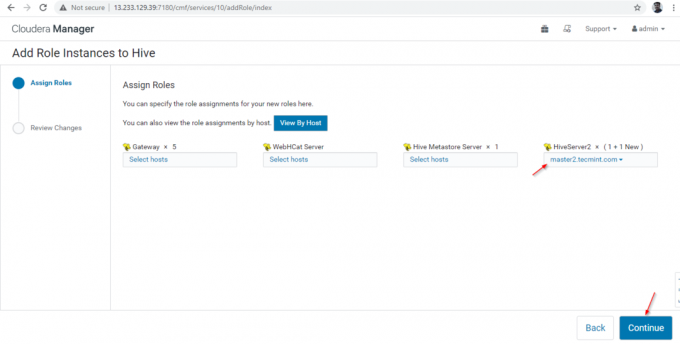
12. Selectați serverele în care doriți să plasați suplimentar Hiveserver2. Puteți adăuga mai mult de două, nu există nicio limită. Aici adăugăm unul suplimentar Hiveserver2 în stăpân2.
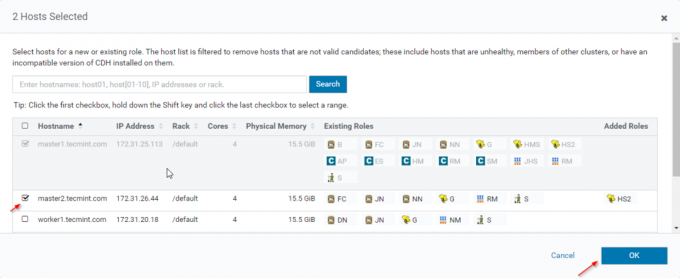
13. Odată selectat serverul, faceți clic pe „Continua’.
14. A Hiverserver2 va fi adăugat în Instanțe de stup, trebuie să o porniți mergând la Manager Cloudera –> Stup –> Instanțe –> (Selectați Hiveserver2 adăugat recent) -> Acțiune pentru selectați –> start.
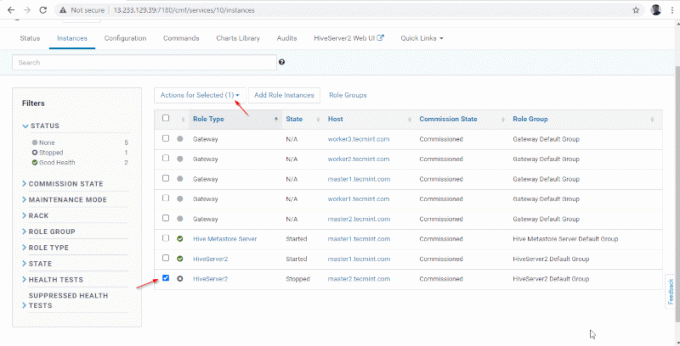
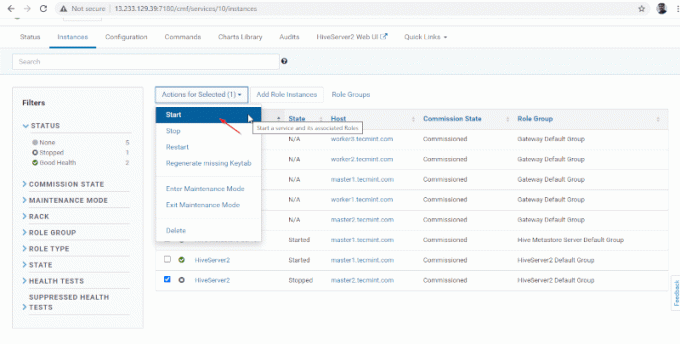
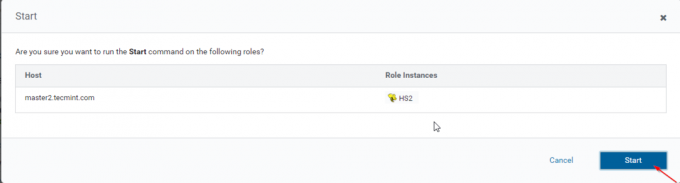
15. O singura data Hiveserver2 a început pe stăpân2, veți obține statutul „Terminat’. Clic Închide.
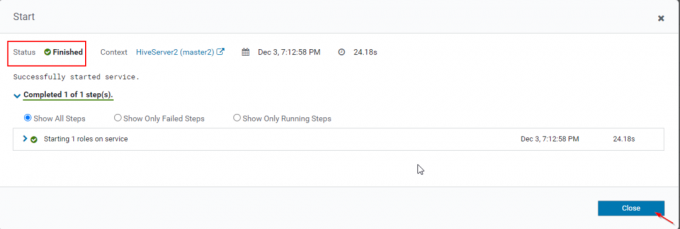
16. Puteți vizualiza, atât Hiveserver2s alearga.
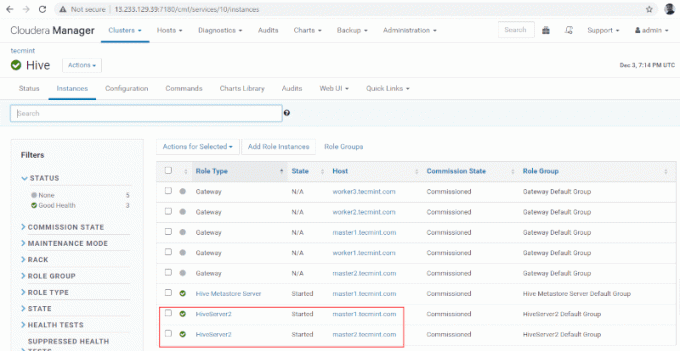
Putem conecta Hiveserver2 prin linia de direcție care este un client subțire și o linie de comandă. Folosește driverul JDBC pentru a stabili conexiunea.
17. Conectați-vă la server unde Hive Gateway rulează.
[[e-mail protejat] ~] $ beeline.

18. Introduceți fișierul JDBC șir de conexiune pentru a conecta Hiveserver2. În acest sens, şir menționăm Hiverserver2 (stăpân2) cu numărul de port implicit 10000. Acest șir de conexiune se va conecta numai la Hiveserver2 care rulează mai departe stăpân2.
beeline>! connect "jdbc: hive2: //master1.tecmint.com: 10000"
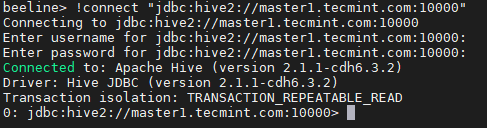
19. Rulați un eșantion de interogare.
0: jdbc: hive2: //master1.tecmint.com: 10000> arată baze de date;

Aceasta este baza de date implicită care vine încorporată.
20. Utilizați comanda de mai jos pentru a termina sesiunea Hive.
0: jdbc: hive2: //master1.tecmint.com: 10000>! Quit.

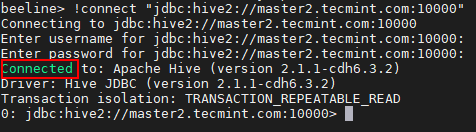
21. Puteți utiliza același mod pentru a vă conecta Hiveserver2 alergând mai departe stăpân2.
beeline>! connect "jdbc: hive2: //master2.tecmint.com: 10000"
23. Putem conecta Hiveserver2 în Zookeeper Discovery modul. În această metodă, nu este necesar să menționăm Hiveserver2 în șirul de conexiune pe care îl folosim Ingrijitor zoo pentru a descoperi disponibilul Hiveserver2.
Aici putem folosi un echilibru de încărcare terță parte pentru a echilibra sarcina dintre cele disponibile Hiverserver2. Este necesară configurarea de mai jos Zookeeper Discovery Mode mergând la Manager Cloudera –> Stup –> Configurare.

24. Apoi, căutați proprietatea „Fragment de configurare avansată HiveServer2”Și faceți clic pe + simbol pentru a adăuga proprietatea de mai jos.
Nume: hive.server2.support.dynamic.service.discovery. Valoare: adevărat. Descriere:
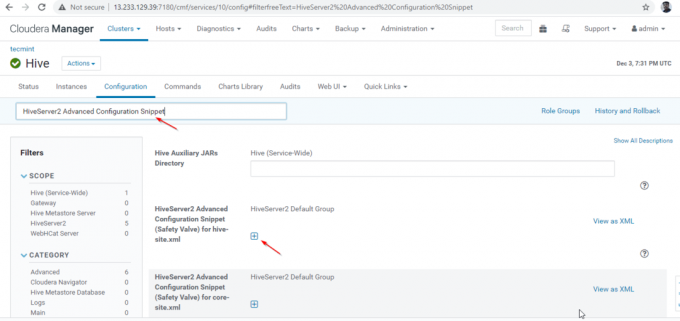
25. După ce ați introdus proprietatea, faceți clic pe „Salvează modificările’.
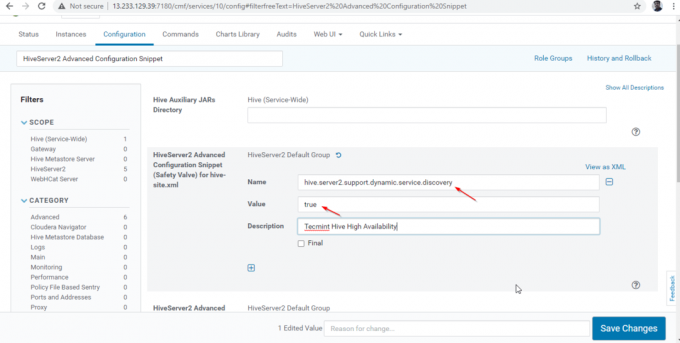
26. Pe măsură ce am făcut modificări la configurație, trebuie să reporniți serviciile afectate făcând clic pe simbolul portocaliu pentru a reporni serviciile.
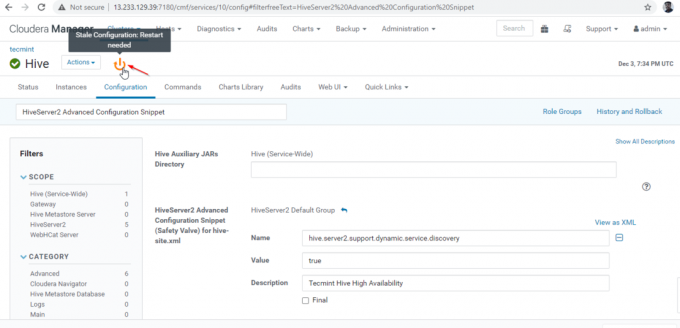
27. Faceți clic pe „Reporniți Stale' Servicii.
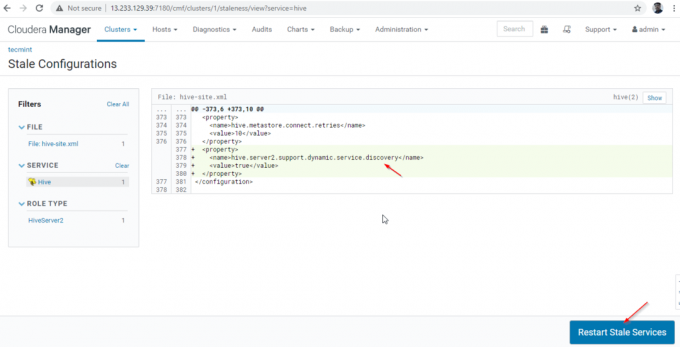
28. Există două opțiuni disponibile. Dacă clusterul este în producție live, trebuie să preferăm repornirea în rulare pentru a minimiza întreruperea. Pe măsură ce instalăm recent, putem alege a doua opțiune „Re-implementați configurația clientuluiȘi faceți clic pe „Reporniți acum’.
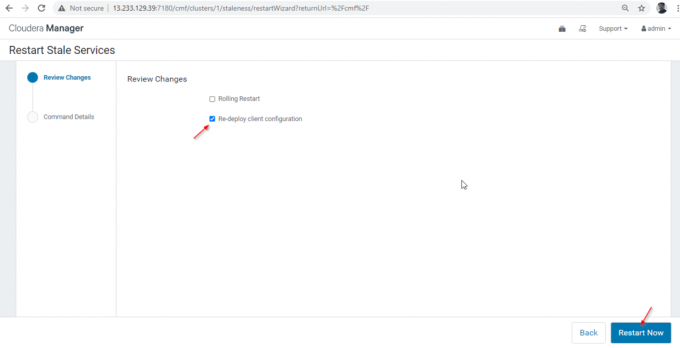
29. Odată ce repornirea a fost finalizată cu succes, veți obține starea „Terminat’. Faceți clic pe „finalizarea'Pentru a finaliza procesul.
30. Acum vom conecta Hiveserver2 folosind Zookeeper Discovery modul. În JDBC conexiune, șirul pe care trebuie să îl folosim Ingrijitor zoo servere cu numărul său de port 2081. Colectați serverele Zookeeper accesând Manager Cloudera –> Ingrijitor zoo –> Instanțe -> (Notați numele serverelor).
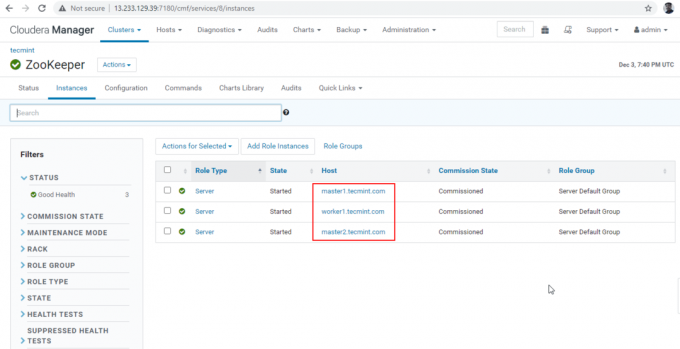
Acestea sunt cele trei servere care au Zookeeper, 2181 este numărul portului.
2181. master1.tecmint.com: 2181. master2.tecmint.com: lucrător1.tecmint.com: 2181.
31. Acum intră linie dreaptă.
[[e-mail protejat] ~] $ beeline.

32. Introduceți fișierul JDBC șir de conexiune, după cum se menționează mai jos. Trebuie să menționăm Modul de descoperire a serviciului și Spațiu de nume Zookeeper. ‘hiveserver2'Este spațiul de nume implicit al Hiveserver2.
beeline>! connect "jdbc: hive2: //master1.tecmint.com: 2181, master2.tecmint.com: 2181, worker1.tecmint.com: 2181 /; serviceDiscoveryMode = zookeeper; zookeeperNamespace = hiveserver2 "

33. Acum sesiunea este conectată la Hiveserver2 alergând mai departe stăpân1. Rulați un eșantion de interogare pentru validare. Utilizați comanda de mai jos pentru a crea o bază de date.
0: jdbc: hive2: //master1.tecmint.com: 2181, mast> crea baza de date tecmint;

34. Utilizați comanda de mai jos pentru a lista baza de date.
0: jdbc: hive2: //master1.tecmint.com: 2181, mast> arată baze de date;

35. Acum vom valida Disponibilitatea înaltă în Zookeeper Discovery Mode. Mergi la Manager Cloudera și opriți Hiveserver2 pe stăpân1 pe care le-am testat mai sus.
Manager Cloudera –> Stup –> Instanțe -> (selectați Hiveserver2 pe stăpân1) –> Acțiune pentru selectat –> Stop.

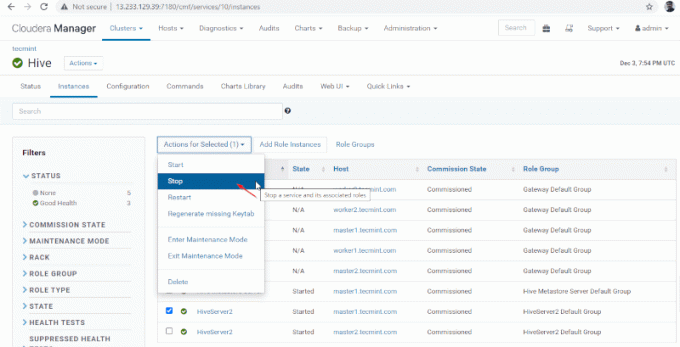
36. Apasă pe 'Stop’. Odată oprit, veți primi statutul „Terminat’. Verificați Hiveserver2 pe stăpân1 navigând în Stup –> Instanțe.

37. Intră în linie dreaptă și conectați Hiveserver2 folosind același lucru JDBC șir de conexiune cu Zookeeper Discovery Mode așa cum am făcut în pașii de mai sus.
[[e-mail protejat] ~] $ beeline beeline>! connect "jdbc: hive2: //master1.tecmint.com: 2181, master2.tecmint.com: 2181, worker1.tecmint.com: 2181 /; serviceDiscoveryMode = zookeeper; zookeeperNamespace = hiveserver2 "

Acum veți fi conectat la Hiveserver2 alergând mai departe stăpân2.
38. Validați cu un eșantion de interogare.
0: jdbc: hive2: //master1.tecmint.com: 2181, mast> arată baze de date;

În acest articol, am parcurs pașii detaliați pentru a avea Hive Data Warehouse model în Cluster cu Valabilitate ridicată. Într-un mediu de producție în timp real, mai mult de trei Hiveserver2 va fi plasat cu Zookeeper Discovery Mode activat.
Aici, toate Hiveserver2’s se înregistrează la Ingrijitor zoo sub o comună Spațiu de nume. Zookeeper dinamic descoperă disponibilul Hiveserver2 și stabilește sesiunea Hive.

