10. Acum este timpul să vă configurați Cluster Hadoop pe un singur nod într-un mod pseudo distribuit prin editarea fișierelor sale de configurare.
Locația fișierelor de configurare hadoop este $ HADOOP_HOME / etc / hadoop /, care este reprezentat în acest tutorial de directorul de start al contului hadoop (/opt/hadoop/) cale.
După ce te-ai conectat la utilizator hadoop puteți începe să editați următorul fișier de configurare.
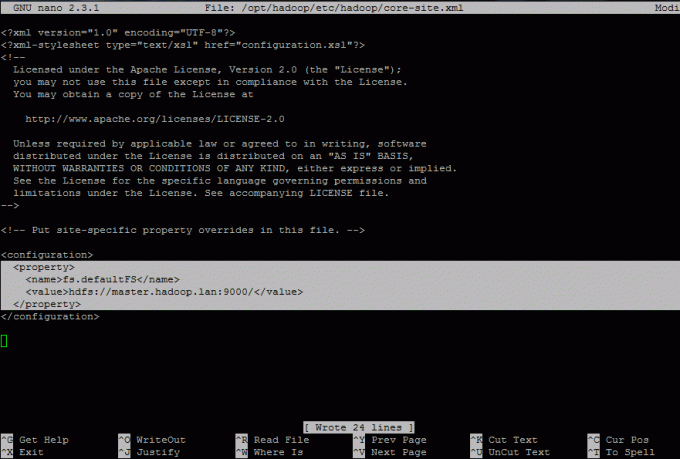
Primul care editează este core-site.xml fişier. Acest fișier conține informații despre numărul de port utilizat de instanța Hadoop, memoria alocată sistemului de fișiere, limita de memorie a stocării de date și dimensiunea bufferelor de citire / scriere.
$ vi etc / hadoop / core-site.xml.
Adăugați următoarele proprietăți între
fs.defaultFS hdfs: //master.hadoop.lan: 9000 /
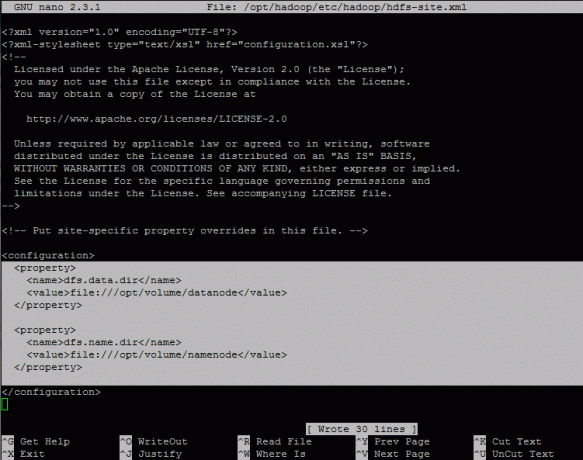
11. Apoi deschideți și editați hdfs-site.xml fişier. Fișierul conține informații despre valoarea datelor de replicare,
$ vi etc / hadoop / hdfs-site.xml.
Aici adăugați următoarele proprietăți între
Inlocuieste dfs.data.dir și dfs.name.dir valorează în consecință.
dfs.data.dir fișier: /// opt / volume / datanode dfs.name.dir fișier: /// opt / volume / namenode
12. Pentru că am specificat /op/volume/ ca stocare a sistemului de fișiere hadoop, trebuie să creăm aceste două directoare (datanode și namenode) din contul root și acordați toate permisiunile pentru contul hadoop executând comenzile de mai jos.
$ su root. # mkdir -p / opt / volume / namenode. # mkdir -p / opt / volume / datanode. # chown -R hadoop: hadoop / opt / volume / # ls -al / opt / #Verificați permisiunile. # ieșire # Ieșire din contul root pentru a reveni la utilizatorul hadoop.

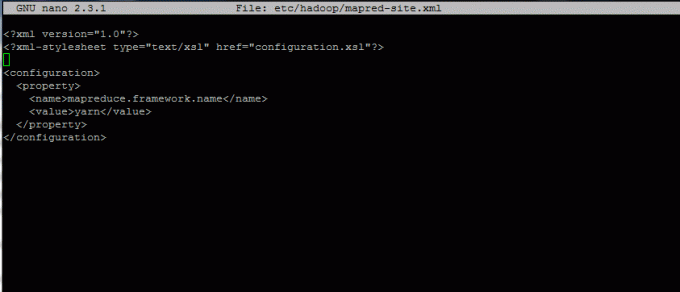
13. Apoi, creați fișierul mapred-site.xml fișier pentru a specifica că utilizăm cadrul MapReduce de fire.
$ vi etc / hadoop / mapred-site.xml.
Adăugați următorul fragment la mapred-site.xml fişier:
1.0 text / xslconfiguration.xsl mapreduce.framework.name fire
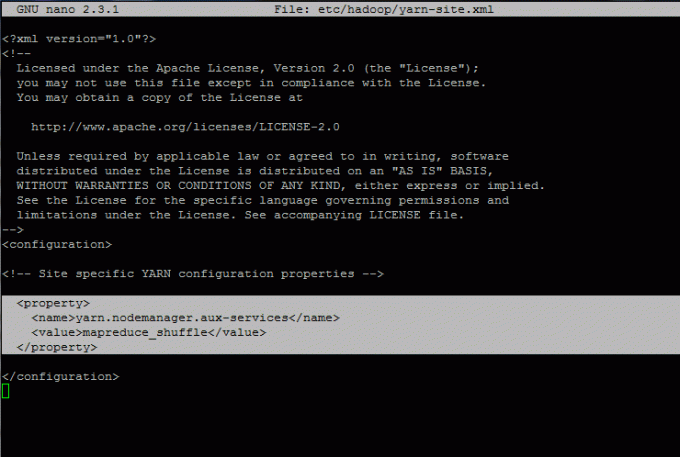
14. Acum, editați yarn-site.xml fișier cu declarațiile de mai jos atașate între
$ vi etc / hadoop / yarn-site.xml.
Adăugați următorul fragment la yarn-site.xml fişier:
yarn.nodemanager.aux-services mapreduce_shuffle
15. În cele din urmă, setați variabila de acasă Java pentru mediul Hadoop editând linia de mai jos de la hadoop-env.sh fişier.
$ vi etc / hadoop / hadoop-env.sh.
Editați următoarea linie pentru a indica calea sistemului dvs. Java.
export JAVA_HOME = / usr / java / implicit /

16. De asemenea, înlocuiți gazdă locală valoarea din fișierul sclavi pentru a indica numele gazdei mașinii dvs. configurat la începutul acestui tutorial.
$ vi etc / hadoop / slaves.
