17. Odată ce clusterul cu nod unic hadoop a fost configurat, este timpul să inițializăm sistemul de fișiere HDFS formatând /opt/volume/namenode director de stocare cu următoarea comandă:
$ hdfs namenode -format.

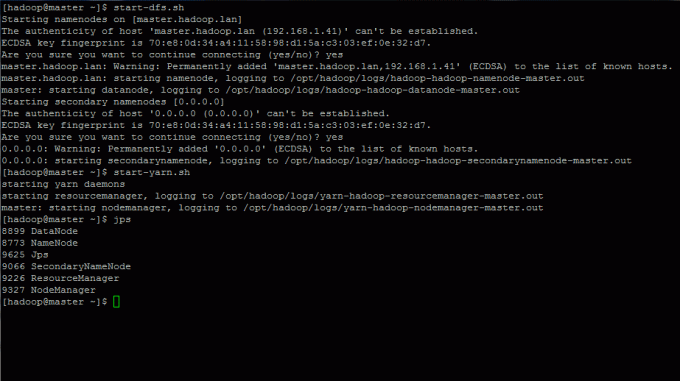
18. Comenzile Hadoop sunt localizate în $ HADOOP_HOME / sbin director. Pentru a porni serviciile Hadoop, executați comenzile de mai jos pe consola dvs.:
$ start-dfs.sh. $ start-yarn.sh.
Verificați starea serviciilor cu următoarea comandă.
$ jps.
Alternativ, puteți vizualiza o listă a tuturor soclurilor deschise pentru Apache Hadoop pe sistemul dvs. utilizând ss comanda.
$ ss -tul. $ ss -tuln # Ieșire numerică.

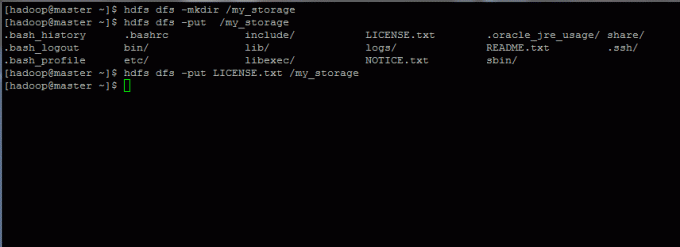
19. Pentru a testa clusterul de sistem de fișiere hadoop, creați un director aleatoriu în sistemul de fișiere HDFS și copiați un fișier din sistemul de fișiere local în HDFS stocare (introduceți date în HDFS).
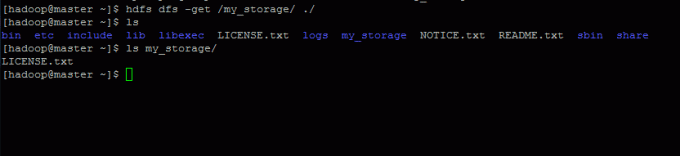
$ hdfs dfs -mkdir / my_storage. $ hdfs dfs -put LICENȚĂ.txt / depozitul_meu.
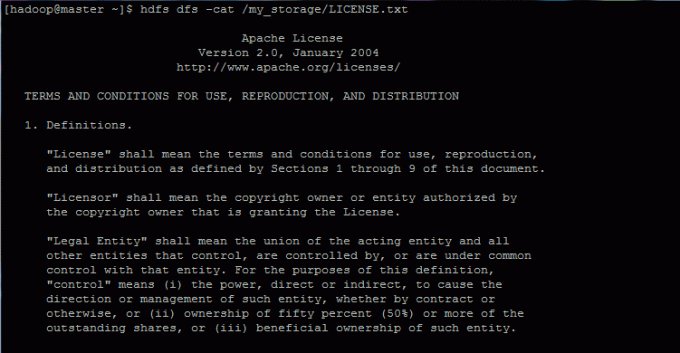
Pentru a vizualiza conținutul unui fișier sau a afișa un director în sistemul de fișiere HDFS, lansați comenzile de mai jos:
$ hdfs dfs -cat /my_storage/LICENSE.txt. $ hdfs dfs -ls / depozitul_meu /

Pentru a prelua date de pe HDFS în sistemul nostru de fișiere local, utilizați comanda de mai jos:
$ hdfs dfs -get / my_storage / ./
Obțineți lista completă a opțiunilor de comandă HDFS prin emiterea:
$ hdfs dfs -help.
20. Pentru a accesa serviciile Hadoop dintr-un browser la distanță, vizitați următoarele linkuri (înlocuiți adresa IP a FQDN în consecință). De asemenea, asigurați-vă că porturile de mai jos sunt deschise pe paravanul de protecție al sistemului.
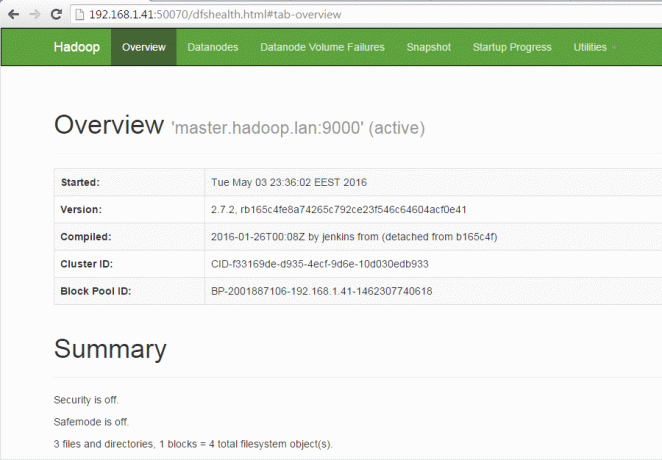
Pentru Hadoop Prezentare generală a serviciului NameNode.
http://192.168.1.41:50070
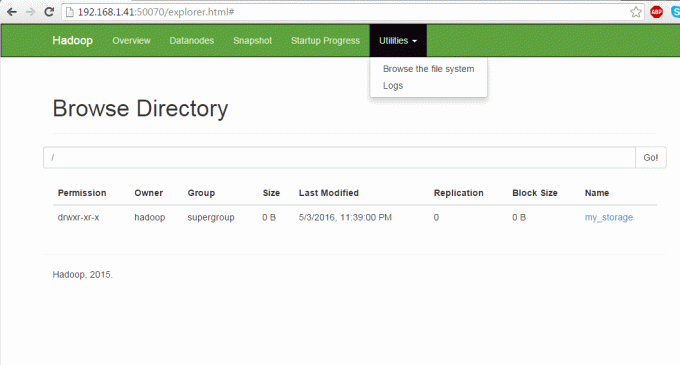
Pentru navigarea în sistemul de fișiere Hadoop (Directory Browse).
http://192.168.1.41:50070/explorer.html.
Pentru informații despre cluster și aplicații (ResourceManager).
http://192.168.1.41:8088

Pentru informații despre NodeManager.
http://192.168.1.41:8042

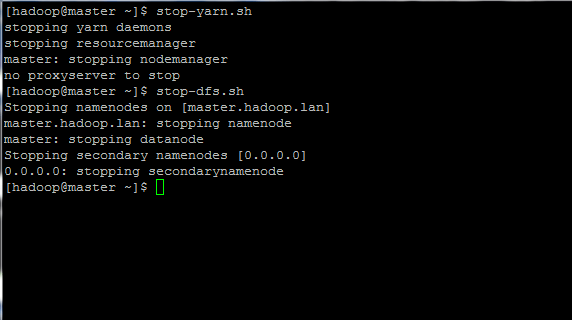
21. Pentru a opri toate instanțele hadoop rulați comenzile de mai jos:
$ stop-yarn.sh. $ stop-dfs.sh.
22. Pentru a activa daemonii Hadoop la nivel de sistem, conectați-vă cu utilizatorul root, deschideți /etc/rc.local fișier pentru editare și adăugați rândurile de mai jos:
$ su - rădăcină. # vi /etc/rc.local.
Adăugați aceste extrase la rc.local fişier.
su - hadoop -c "/opt/hadoop/sbin/start-dfs.sh" su - hadoop -c "/opt/hadoop/sbin/start-yarn.sh" ieșire 0.
Apoi, adăugați permisiuni executabile pentru rc.local înregistrați și activați, porniți și verificați starea serviciului prin emiterea comenzilor de mai jos:
$ chmod + x /etc/rc.d/rc.local. $ systemctl activează rc-local. $ systemctl începe rc-local. $ systemctl status rc-local.

Asta e! Data viitoare tu reporniți mașina ta Hadoop serviciile vor fi pornite automat pentru dvs.! Tot ce trebuie să faceți este să declanșați o aplicație compatibilă Hadoop și sunteți gata de plecare!
Pentru informații suplimentare, vă rugăm să consultați oficialul Documentația Apache Hadoop pagină web și Hadoop Wiki pagină.