
În acest ghid, vom descrie ce codificare a caracterelor și vom acoperi câteva exemple de conversie a fișierelor dintr-o codificare a caracterelor în alta folosind un instrument de linie de comandă. Apoi, în cele din urmă, vom analiza modul de convertire a mai multor fișiere din orice set de caractere (set de caractere) la UTF-8 codare în Linux.
Așa cum probabil ați avea deja în vedere, un computer nu înțelege și nu stochează litere, cifre sau orice altceva pe care noi, ca oameni, îl putem percepe, cu excepția biților. Un bit are doar două valori posibile, adică a 0 sau 1, Adevărat sau fals, da sau Nu. Orice alt lucru, cum ar fi litere, cifre, imagini trebuie să fie reprezentate în biți pentru ca un computer să poată fi procesat.
In termeni simpli, codificarea caracterelor este o modalitate de a informa computerul cum să interpreteze zero-urile brute și cele în caractere reale, unde un caracter este reprezentat de un set de numere. Când tastăm text într-un fișier, cuvintele și propozițiile pe care le formăm sunt preparate din diferite caractere, iar caracterele sunt organizate în a
set de caractere.Există diverse scheme de codificare, cum ar fi ASCII, ANSI, Unicode printre alții. Mai jos este un exemplu de ASCII codificare.
Biti de caracter. A 01000001. B 01000010.
În Linux, iconv instrumentul pentru linia de comandă este utilizat pentru a converti textul dintr-o formă de codificare în alta.
Puteți verifica codificarea unui fișier folosind fişier comanda, folosind -i sau --mima pavilion care permite imprimarea șirului de tip mime ca în exemplele de mai jos:
$ file -i Car.java. $ file -i CarDriver.java.

Sintaxa de utilizare iconv este după cum urmează:
$ iconv opțiune. $ iconv opțiuni -f de la-codificare -t la codificare inputfile (s) -o outputfile
Unde -f sau --de la cod înseamnă codificare de intrare și -t sau --la codificare specifică codarea ieșirii.
Pentru a lista toate seturile de caractere codate cunoscute, executați comanda de mai jos:
$ iconv -l

Apoi, vom învăța cum să convertim de la o schemă de codificare la alta. Comanda de mai jos convertește din ISO-8859-1 la UTF-8 codificare.
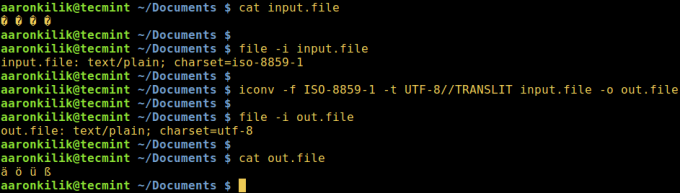
Luați în considerare un fișier numit fișier de intrare care conține caracterele:
Să începem prin a verifica codarea caracterelor din fișier și apoi să vizualizăm conținutul fișierului. Îndeaproape, putem converti toate personajele în ASCII codificare.
După rularea iconv, verificăm apoi conținutul fișierului de ieșire și noua codificare a caracterelor, după cum se arată mai jos.
$ fișier -i input.file. $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8 // TRANSLIT input.file -o out.file. $ cat out.file $ file -i out.file
Notă: În cazul în care șirul //IGNORE se adaugă la codificare, caractere care nu pot fi convertite și se afișează o eroare după conversie.
Din nou, presupunând șirul //TRANSLIT este adăugat la codificare ca în exemplul de mai sus (ASCII // TRANSLIT), caracterele convertite sunt transliterate după cum este necesar și dacă este posibil. Ceea ce implică în cazul în care un personaj nu poate fi reprezentat în setul de caractere țintă, poate fi aproximat prin unul sau mai multe personaje similare.
În consecință, orice caracter care nu poate fi transliterat și nu se află în setul de caractere țintă este înlocuit cu un semn de întrebare (?) în ieșire.
Revenind la subiectul nostru principal, pentru a converti mai multe sau toate fișierele dintr-un director în codificare UTF-8, puteți scrie un mic script shell numit codificare.sh după cum urmează:
#! / bin / bash. #entrarea codificării de intrare aici. FROM_ENCODING = "value_here" #codare de ieșire (UTF-8) TO_ENCODING = "UTF-8" #convertit. CONVERT = "iconv -f $ FROM_ENCODING -t $ TO_ENCODING" #loop pentru a converti mai multe fișiere pentru fișiere în * .txt; faceți $ CONVERT "$ file" -o "$ {file% .txt} .utf8.converted" Terminat. ieșire 0.
Salvați fișierul, apoi faceți scriptul executabil. Rulați-l din directorul în care fișierele dvs. (*.txt) sunt localizate.
$ chmod + x coding.sh. $ ./encoding.sh.
Important: Puteți utiliza și acest script pentru conversia generală a mai multor fișiere dintr-o codificare dată în alta, pur și simplu jucați cu valorile FROM_ENCODING și TO_ENCODING variabilă, fără a uita numele fișierului de ieșire „$ {file% .txt} .utf8.converted”.
Pentru mai multe informații, consultați iconv pagina man.
$ man iconv.
Pentru a rezuma acest ghid, înțelegerea codificării și modul de conversie dintr-o schemă de codificare a caracterelor în alta este o cunoaștere necesară pentru fiecare utilizator de computer, cu atât mai mult pentru programatori atunci când vine vorba de a face față text.
În cele din urmă, puteți lua legătura cu noi folosind secțiunea de comentarii de mai jos pentru orice întrebări sau feedback.
