Fundația Linux a anunțat LFCS (Sysadmin certificat de Linux Foundation) certificare, un nou program care urmărește să ajute persoanele din întreaga lume să obțină certificarea în sarcinile de administrare a sistemelor de bază până la intermediare pentru sistemele Linux. Aceasta include sprijinirea sistemelor și serviciilor în funcțiune, împreună cu depanarea și analiza directă a problemelor și luarea de decizii inteligente pentru escaladarea problemelor către echipele de ingineri.

Vă rugăm să urmăriți următorul videoclip care demonstrează despre Programul de certificare Linux Foundation.
Seria va fi intitulată Pregătirea pentru LFCS (Sysadmin certificat de Linux Foundation) Părți 1 prin 10 și acoperă următoarele subiecte pentru Ubuntu, CentOS și openSUSE:
Partea 1: Cum se utilizează comanda GNU „sed” pentru a crea, edita și manipula fișiere în Linux
Important: Datorită modificărilor cerințelor de certificare LFCS eficiente Februarie 2, 2016, includem următoarele subiecte necesare pentru seria LFCS publicată aici. Pentru a vă pregăti pentru acest examen, sunteți foarte încurajați să utilizați Seria LFCE de asemenea.
Această postare este parte 1 de o Seria de 20 de tutoriale, care va acoperi domeniile și competențele necesare care sunt necesare pentru LFCS examen de certificare. Acestea fiind spuse, declanșați terminalul și să începem.
Linux tratează intrarea și ieșirea din programe ca fluxuri (sau secvențe) de caractere. Pentru a începe să înțelegem redirecționarea și conductele, trebuie mai întâi să înțelegem cele mai importante trei tipuri de fluxuri I / O (intrare și ieșire), care sunt de fapt fișiere speciale (prin convenție în UNIX și Linux, fluxurile de date și perifericele sau fișierele dispozitivului sunt, de asemenea, tratate ca fișiere obișnuite).
Diferența dintre > (operator de redirecționare) și | (operator de conducte) este că, în timp ce primul conectează o comandă cu un fișier, acesta din urmă conectează ieșirea unei comenzi cu o altă comandă.
# comandă> fișier. # command1 | comanda2.
Deoarece operatorul de redirecționare creează sau suprascrie fișiere în tăcere, trebuie să-l folosim cu precauție extremă și să nu-l confundăm niciodată cu o conductă. Un avantaj al conductelor pe sistemele Linux și UNIX este că nu există niciun fișier intermediar implicat o conductă - stdout-ul primei comenzi nu este scris într-un fișier și apoi citit de al doilea comanda.
Pentru următoarele exerciții practice vom folosi poezia „Un copil fericit”(Autor anonim).
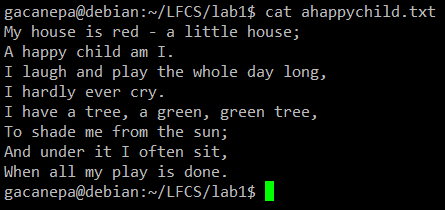
Numele sed este scurt pentru editorul de flux. Pentru cei care nu sunt familiarizați cu termenul, un editor de flux este utilizat pentru a efectua transformări de text de bază pe un flux de intrare (un fișier sau intrare dintr-o conductă).
Cea mai simplă (și populară) utilizare a sed este înlocuirea caracterelor. Vom începe prin a schimba fiecare apariție a literei mici y la majuscule Da și redirecționarea ieșirii către ahappychild2.txt. g semnalizatorul indică faptul că sed ar trebui să efectueze înlocuirea tuturor instanțelor de termen pe fiecare linie de fișier. Dacă acest semnal este omis, sed va înlocui doar prima apariție a termenului pe fiecare linie.
# sed fișier ‘s / term / replacement / flag’.
# sed ‘s / y / Y / g’ ahappychild.txt> ahappychild2.txt.

Dacă doriți să căutați sau să înlocuiți un caracter special (cum ar fi /, \, &) trebuie să scăpați de el, în termenul sau înlocuirea șirurilor, cu o bară înapoi.
De exemplu, vom înlocui cuvântul și cu un ampersand. În același timp, vom înlocui cuvântul Eu cu Tu când primul se găsește la începutul unei linii.
# sed 's / și / \ & / g; s / ^ I / You / g 'ahappychild.txt.
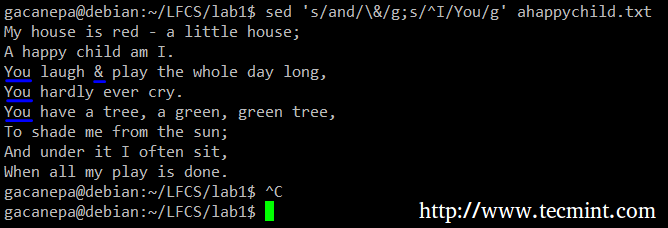
În comanda de mai sus, a ^ (semnul caret) este o expresie regulată bine cunoscută care este utilizată pentru a reprezenta începutul unei linii.
După cum puteți vedea, putem combina două sau mai multe comenzi de substituție (și putem folosi expresii regulate în interiorul lor) separându-le cu punct și virgulă și încadrând setul în ghilimele simple.
O altă utilizare a sed este afișarea (sau ștergerea) unei porțiuni alese dintr-un fișier. În exemplul următor, vom afișa primele 5 linii de /var/log/messages din 8 iunie.
# sed -n '/ ^ 8 iunie / p' / var / log / messages | sed -n 1,5p.
Rețineți că, în mod implicit, sed imprimă fiecare linie. Putem suprascrie acest comportament cu -n opțiune și apoi spuneți sed să tipărească (indicat prin p) numai partea din fișier (sau conducta) care se potrivește cu modelul (8 iunie la începutul liniei în primul caz și liniile 1 până la 5 inclusiv în al doilea caz).
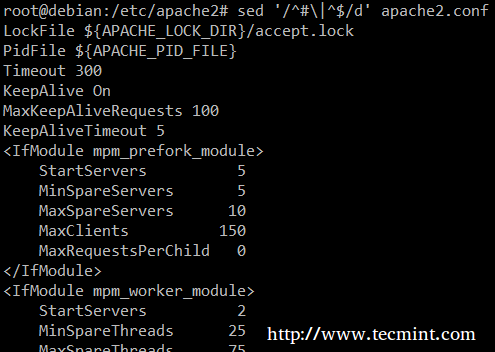
În cele din urmă, poate fi util în timp ce inspectați scripturile sau fișierele de configurare pentru a inspecta codul în sine și a lăsa comentarii. Următoarea sed un singur liner șterge (d) liniile goale sau cele care încep cu # ( | caracterul indică un OR boolean între cele două expresii regulate).
# sed '/ ^ # \ | ^ $ / d' apache2.conf.
uniq comanda ne permite să raportăm sau să eliminăm liniile duplicate dintr-un fișier, scriind în mod implicit pe stdout. Trebuie să observăm că uniq nu detectează liniile repetate decât dacă sunt adiacente. Prin urmare, uniq este frecvent utilizat împreună cu un precedent fel (care este folosit pentru sortarea liniilor de fișiere text). În mod implicit, fel ia primul câmp (separat prin spații) ca câmp cheie. Pentru a specifica un câmp cheie diferit, trebuie să folosim -k opțiune.
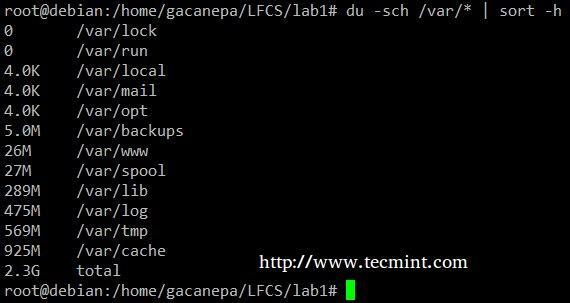
du –sch / cale / către / director / * comanda returnează utilizarea spațiului pe disc pentru fiecare subdirectoare și fișiere din directorul specificat în text lizibil de către om format (afișează, de asemenea, un total pe director) și nu comandă ieșirea după dimensiune, ci după subdirector și numele fișierului. Putem folosi următoarea comandă pentru a sorta după mărime.
# du -sch / var / * | sortează –h.
Puteți număra numărul de evenimente dintr-un jurnal după dată, spunând uniq pentru a efectua comparația folosind primele 6 caractere (-w 6) din fiecare linie (unde este specificată data) și prefixând fiecare linie de ieșire cu numărul de apariții (-c) cu următoarea comandă.
# cat /var/log/mail.log | uniq -c -w 6.

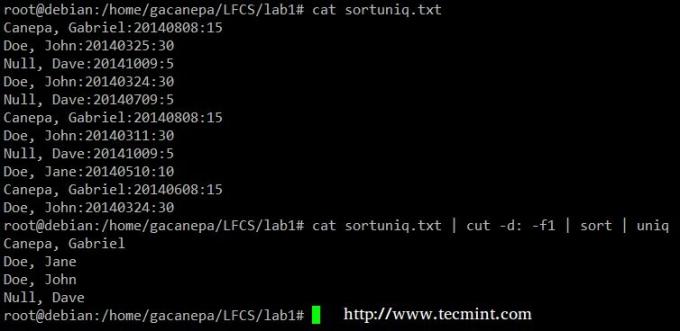
În cele din urmă, puteți combina fel și uniq (cum sunt de obicei). Luați în considerare următorul fișier cu o listă a donatorilor, data donației și suma. Să presupunem că vrem să știm câți donatori unici există. Vom folosi următoarea comandă pentru a tăia primul câmp (câmpurile sunt delimitate de două puncte), sortăm după nume și eliminăm liniile duplicat.
# cat sortuniq.txt | tăiat -d: -f1 | sortare | uniq.
Citește și: 13 Exemple de comandă „pisică”
grep caută fișiere text sau (ieșire comandă) pentru apariția unei expresii regulate specificate și scoate orice linie care conține o potrivire cu ieșirea standard.
Afișați informațiile de la /etc/passwd pentru utilizatorul gacanepa, ignorând majuscule.
# grep -i gacanepa / etc / passwd.

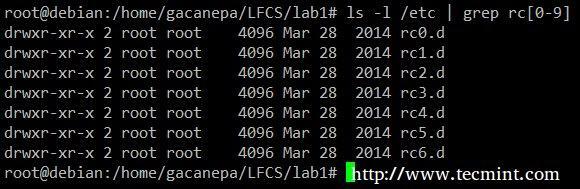
Afișează tot conținutul /etc al cărui nume începe cu rc urmat de orice număr unic.
# ls -l / etc | grep rc [0-9]
Citește și: 12 Exemple de comenzi „grep”
tr comanda poate fi folosită pentru a traduce (schimba) sau șterge caractere din stdin și a scrie rezultatul în stdout.
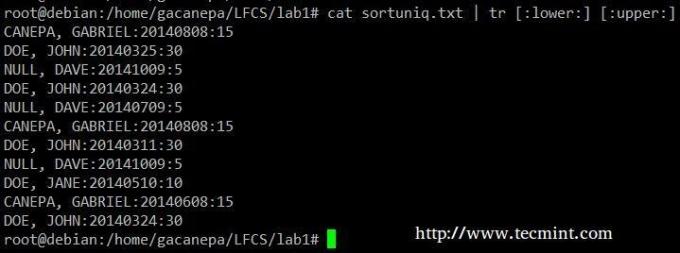
Schimbați toate minusculele cu majuscule în fișierul sortuniq.txt.
# cat sortuniq.txt | tr [: inferior:] [: superior:]
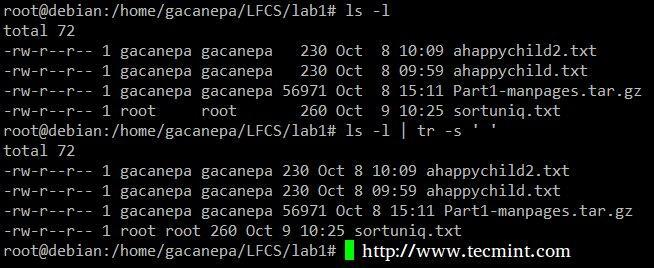
Strângeți delimitatorul în ieșirea din ls –l către un singur spațiu.
# ls -l | tr -s ''
a tăia comanda extrage porțiuni de linii de intrare (din stdin sau fișiere) și afișează rezultatul pe ieșirea standard, pe baza numărului de octeți (-b opțiune), caractere (-c) sau câmpuri (-f). În acest ultim caz (bazat pe câmpuri), separatorul de câmp implicit este o filă, dar se poate specifica un alt delimitator folosind -d opțiune.
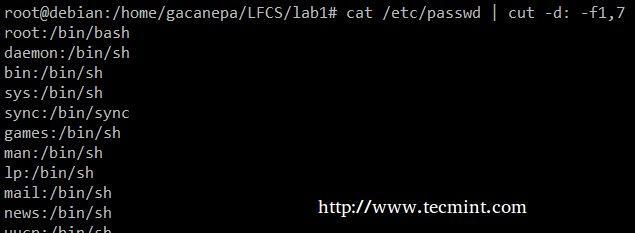
Extrageți conturile de utilizator și shell-urile implicite atribuite acestora /etc/passwd ( –D opțiunea ne permite să specificăm delimitatorul de câmp și –F comutatorul indică câmpurile care vor fi extrase.
# cat / etc / passwd | tăiat -d: -f1,7.
Rezumând, vom crea un flux de text format din primul și al treilea fișier ne-gol al rezultatului ultimul comanda. Noi vom folosi grep ca prim filtru pentru a verifica sesiunile utilizatorului gacanepa, apoi strângeți delimitatorii într-un singur spațiu (tr -s ‘ ‘). Apoi, vom extrage primul și al treilea câmp cu a tăiași, în cele din urmă, sortați după al doilea câmp (adrese IP în acest caz) care arată unic.
# ultimul | grep gacanepa | tr -s '' | cut -d '' -f1,3 | sortare -k2 | uniq.
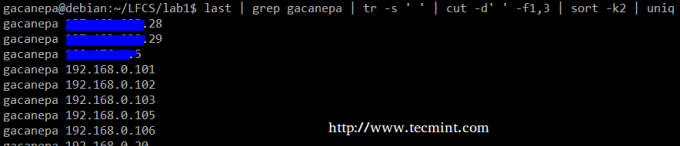
Comanda de mai sus arată cum pot fi combinate mai multe comenzi și conducte pentru a obține date filtrate în conformitate cu dorințele noastre. Simțiți-vă liber să îl rulați și pe piese, pentru a vă ajuta să vedeți rezultatul care este canalizat de la o comandă la alta (apropo, aceasta poate fi o experiență de învățare excelentă!).
Deși acest exemplu (împreună cu restul exemplelor din tutorialul curent) poate să nu pară foarte util la prima vedere, ele sunt un bun punct de plecare pentru a începe experimentarea cu comenzile care sunt folosite pentru a crea, edita și manipula fișiere din comanda Linux linia. Simțiți-vă liber să lăsați întrebările și comentariile dvs. mai jos - acestea vor fi mult apreciate!
