Apache Hadoop este o construcție de cadru Open Source pentru stocarea Big Data distribuită și procesarea datelor în clustere de computere. Proiectul se bazează pe următoarele componente:

Acest articol vă va ghida cu privire la modul în care puteți instala Apache Hadoop pe un singur cluster de nod în CentOS 7 (funcționează și pentru RHEL 7 și Fedora 23+ versiuni). Acest tip de configurație este, de asemenea, menționat ca Modul Pseudo-Distribuit Hadoop.
1. Înainte de a continua instalarea Java, mai întâi conectați-vă cu un utilizator root sau cu un utilizator cu privilegii de root, configurați numele gazdei mașinii cu următoarea comandă.
# hostnamectl set-master hostname.
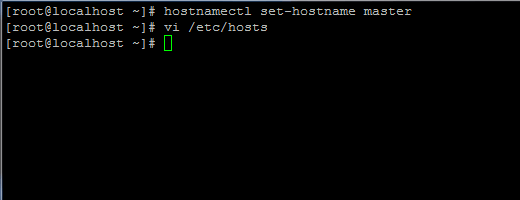
De asemenea, adăugați o nouă înregistrare în fișierul hosts cu propriul FQDN al mașinii pentru a indica adresa IP a sistemului.
# vi / etc / hosts.
Adăugați rândul de mai jos:
192.168.1.41 master.hadoop.lan.

Înlocuiți numele de gazdă de mai sus și înregistrările FQDN cu setările dvs.
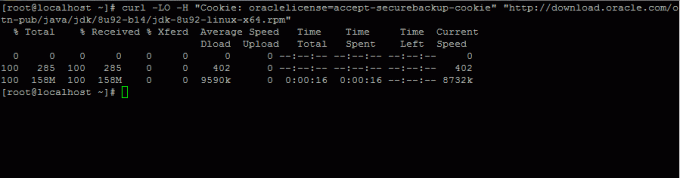
2. Apoi, du-te la Descărcare Oracle Java pagină și apucați cea mai recentă versiune de Trusa de dezvoltare Java SE 8 pe sistemul dvs. cu ajutorul răsuci comanda:
# curl -LO -H "Cookie: oraclelicense = accept-securebackup-cookie" " http://download.oracle.com/otn-pub/java/jdk/8u92-b14/jdk-8u92-linux-x64.rpm”
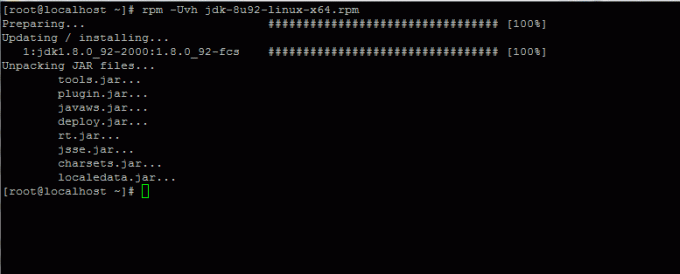
3. După terminarea descărcării binare Java, instalați pachetul prin executarea comenzii de mai jos:
# rpm -Uvh jdk-8u92-linux-x64.rpm.
4. Apoi, creați un cont de utilizator nou pe sistemul dvs. fără puteri de root, pe care îl vom folosi pentru calea de instalare Hadoop și mediul de lucru. Noul director principal al contului va locui în /opt/hadoop director.
# useradd -d / opt / hadoop hadoop. # passwd hadoop.
5. La pasul următor vizitați Apache Hadoop pentru a obține linkul pentru cea mai recentă versiune stabilă și a descărca arhiva de pe sistemul dvs.
# curl -O http://apache.javapipe.com/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz

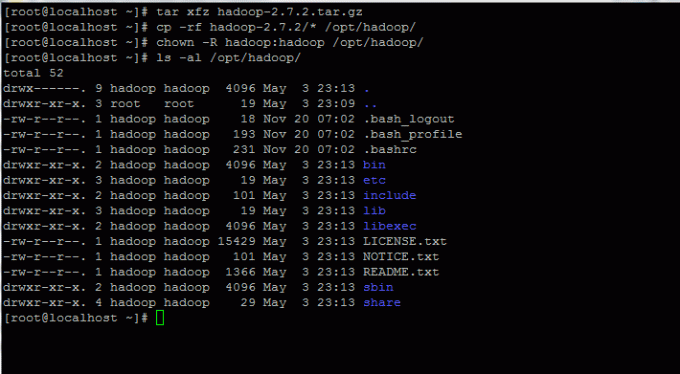
6. Extrageți arhiva și copiați conținutul directorului în calea principală a contului hadoop. De asemenea, asigurați-vă că modificați permisiunile fișierelor copiate în consecință.
# tar xfz hadoop-2.7.2.tar.gz. # cp -rf hadoop-2.7.2 / * / opt / hadoop / # chown -R hadoop: hadoop / opt / hadoop /
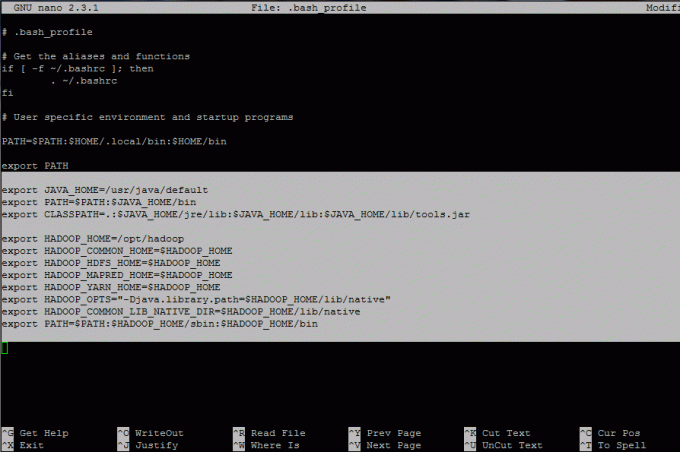
7. Apoi, conectați-vă cu hadoop utilizator și configurați Hadoop și Variabile de mediu Java pe sistemul dvs. prin editarea fișierului .bash_profile fişier.
# su - hadoop. $ vi .bash_profile.
Adăugați următoarele rânduri la sfârșitul fișierului:
## Variabile JAVA env export JAVA_HOME = / usr / java / implicit. export PATH = $ PATH: $ JAVA_HOME / bin. export CLASSPATH =.: $ JAVA_HOME / jre / lib: $ JAVA_HOME / lib: $ JAVA_HOME / lib / tools.jar ## HADOOP variabile envexport HADOOP_HOME = / opt / hadoop. export HADOOP_COMMON_HOME = $ HADOOP_HOME. export HADOOP_HDFS_HOME = $ HADOOP_HOME. export HADOOP_MAPRED_HOME = $ HADOOP_HOME. export HADOOP_YARN_HOME = $ HADOOP_HOME. export HADOOP_OPTS = "- Djava.library.path = $ HADOOP_HOME / lib / native" export HADOOP_COMMON_LIB_NATIVE_DIR = $ HADOOP_HOME / lib / native. export PATH = $ PATH: $ HADOOP_HOME / sbin: $ HADOOP_HOME / bin.
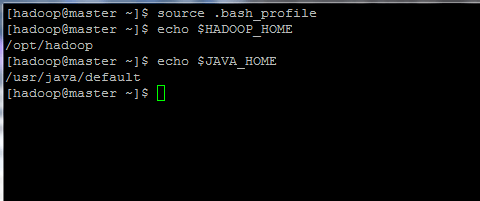
8. Acum, inițializați variabilele de mediu și verificați starea acestora prin emiterea comenzilor de mai jos:
$ source .bash_profile. $ echo $ HADOOP_HOME. $ echo $ JAVA_HOME.
9. În cele din urmă, configurați autentificarea bazată pe cheia ssh pentru hadoop executând comenzile de mai jos (înlocuiți numele gazdei sau FQDN impotriva ssh-copy-id comandă în consecință).
De asemenea, lăsați expresie de acces depus necompletat pentru a vă autentifica automat prin ssh.
$ ssh-keygen -t rsa. $ ssh-copy-id master.hadoop.lan.

