Deși Linux este foarte fiabil, administratorii de sistem înțelepți ar trebui să găsească o modalitate de a urmări în permanență comportamentul și utilizarea sistemului. Asigurarea unui timp de funcționare cât mai aproape de 100% cât mai mult posibil și disponibilitatea resurselor sunt nevoi critice în multe medii. Examinarea statutului trecut și actual al sistemului ne va permite să prevedem și, cel mai probabil, să prevenim posibile probleme.

Vă prezentăm programul de certificare Linux Foundation
În acest articol vom prezenta o listă cu câteva instrumente disponibile în majoritatea distribuțiilor din amonte pentru a verifica starea sistemului, a analiza întreruperile și a depana problemele în curs. Mai exact, din nenumăratele date disponibile, ne vom concentra asupra procesorului, spațiului de stocare și utilizarea memoriei, gestionarea de bază a proceselor și analiza jurnalelor.
Există 2 comenzi bine-cunoscute în Linux care sunt utilizate pentru a inspecta utilizarea spațiului de stocare: df și du.
Primul, df (care înseamnă disc liber), este de obicei folosit pentru a raporta utilizarea generală a spațiului pe disc de către sistemul de fișiere.
Fără opțiuni, df raportează utilizarea spațiului pe disc în octeți. Cu -h semnalizați va afișa aceleași informații folosind MB sau GB. Rețineți că acest raport include, de asemenea, dimensiunea totală a fiecărui sistem de fișiere (în blocuri 1-K), spațiile libere și disponibile și punctul de montare al fiecărui dispozitiv de stocare.
# df. # df -h.

Cu siguranță este frumos - dar există o altă limitare care poate face un sistem de fișiere inutilizabil și care rămâne fără inoduri. Toate fișierele dintr-un sistem de fișiere sunt mapate la un inod care conține metadatele sale.
# df -hTi.
puteți vedea cantitatea de inode utilizate și disponibile:
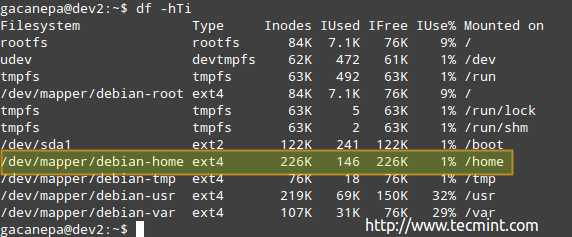
Conform imaginii de mai sus, există 146 inoduri utilizate (1%) în / home, ceea ce înseamnă că puteți crea în continuare 226K fișiere în acel sistem de fișiere.
Rețineți că puteți rămâne fără spațiu de stocare cu mult înainte de a rămâne fără inoduri și invers. Din acest motiv, trebuie să monitorizați nu numai utilizarea spațiului de stocare, ci și numărul de inoduri utilizate de sistemul de fișiere.
Utilizați următoarele comenzi pentru a găsi fișiere sau directoare goale (care ocupă 0B) care utilizează inoduri fără un motiv:
# find / home -type f-vid. # find / home -type d-vid.
De asemenea, puteți adăuga fișierul -șterge semnalizați la sfârșitul fiecărei comenzi dacă doriți și să ștergeți acele fișiere și directoare goale:
# find / home -type f -empty --delete. # find / home -type f-vid.
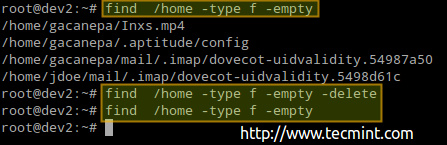
Procedura anterioară a șters 4 fișiere. Să verificăm din nou numărul de noduri utilizate / disponibile din nou în / acasă:
# df -hTi | grep acasă.

După cum puteți vedea, există 142 utilizate inoduri acum (cu 4 mai puțin decât înainte).
Dacă utilizarea unui anumit sistem de fișiere depășește un procent predefinit, puteți utiliza du (prescurtare pentru utilizarea discului) pentru a afla care sunt fișierele care ocupă cel mai mult spațiu.
Exemplul este dat pentru /var, care, după cum puteți vedea în prima imagine de mai sus, este utilizat la 67%.
# du -sch / var / *
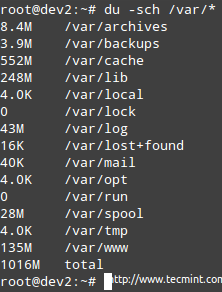
Notă: Că puteți trece la oricare dintre subdirectoarele de mai sus pentru a afla exact ce conține și cât de mult ocupă fiecare articol. Apoi puteți utiliza aceste informații pentru a șterge unele fișiere dacă nu sunt necesare sau pentru a extinde dimensiunea volumului logic, dacă este necesar.
Citește și
Instrumentul clasic din Linux care este utilizat pentru a efectua o verificare generală a utilizării procesorului / memoriei și a gestionării proceselor este comanda de sus. În plus, partea de sus afișează o vizualizare în timp real a unui sistem care rulează. Există și alte instrumente care ar putea fi utilizate în același scop, cum ar fi htop, dar m-am mulțumit pentru top deoarece este instalat imediat din orice distribuție Linux.
Pentru a începe de sus, pur și simplu tastați următoarea comandă în linia de comandă și apăsați Enter.
# sus.
Să examinăm o ieșire de top tipică:
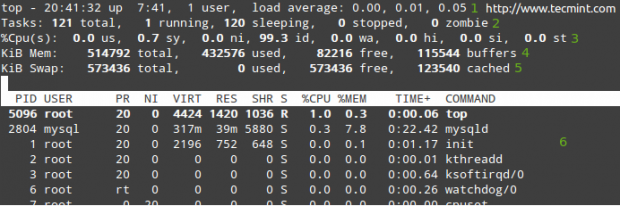
În rândurile de la 1 la 5 sunt afișate următoarele informații:
1. Ora curentă (8:41:32 pm) și timpul de funcționare (7 ore și 41 minute). Un singur utilizator este conectat la sistem și media de încărcare în ultimele 1, 5 și, respectiv, 15 minute. 0,00, 0,01 și 0,05 indică faptul că, în aceste intervale de timp, sistemul a fost inactiv timp de 0% din timp (0,00: nu au existat procese în așteptarea procesorului), acesta a fost apoi supraîncărcat cu 1% (0,01: o medie de 0,01 procese așteptau procesorul) și 5% (0.05). Dacă este mai mic decât 0 și cu cât este mai mic numărul (0,65, de exemplu), sistemul a fost inactiv timp de 35% în ultimele 1, 5 sau 15 minute, în funcție de locul în care apare 0,65.
2. În prezent, există 121 de procese care rulează (puteți vedea lista completă în 6). Doar 1 dintre ele rulează (partea de sus în acest caz, așa cum puteți vedea în coloana% CPU), iar restul de 120 așteaptă în fundal, dar „dorm” și vor rămâne în starea respectivă până când le sunăm. Cum? Puteți verifica acest lucru deschizând un prompt mysql și executați câteva interogări. Veți observa cum crește numărul proceselor care rulează.
Alternativ, puteți deschide un browser web și naviga la orice pagină dată care este servită de Apache și veți obține același rezultat. Desigur, aceste exemple presupun că ambele servicii sunt instalate pe serverul dvs.
3. noi (timpul rulează procesele utilizatorului cu prioritate nemodificată), sy (timpul rulează procesele kernel), ni (timpul rulează procesele utilizatorului cu prioritate modificată), wa (timpul de așteptare pentru I / O finalizare), hi (timpul petrecut pentru întreținerea întreruperilor hardware), si (timpul petrecut pentru întreținerea întreruperilor software-ului), st (timpul furat din vm-ul curent de către hipervizor - numai în virtualizat medii).
4. Utilizarea memoriei fizice.
5. Schimbați utilizarea spațiului.
Pentru a inspecta utilizarea memoriei RAM și a swap-ului, puteți utiliza, de asemenea gratuit comanda.
# gratuit.

Desigur, puteți utiliza și -m (MB) sau -g (GB) comută pentru a afișa aceleași informații în formă lizibilă de către om:
# liber -m.

Oricum ar fi, trebuie să fii conștient de faptul că nucleul rezervă cât mai multă memorie posibil și îl pune la dispoziția proceselor atunci când o solicită. În special, „- / + buffere / cache”Linia arată valorile reale după ce această memorie cache I / O este luată în considerare.
Cu alte cuvinte, cantitatea de memorie utilizată de procese și cantitatea disponibilă pentru alte procese (în acest caz, 232 MB folosit și 270 MB disponibile, respectiv). Când procesele au nevoie de această memorie, nucleul va reduce automat dimensiunea cache-ului I / O.
Citește și: 10 Comandă utilă „gratuită” pentru a verifica utilizarea memoriei Linux
În orice moment, există multe procese care rulează pe sistemul nostru Linux. Există două instrumente pe care le vom utiliza pentru a monitoriza îndeaproape procesele: ps și pstree.
Folosind -e și -f opțiuni combinate într-o singură (-ef) puteți lista toate procesele care rulează în prezent pe sistemul dvs. Puteți conecta această ieșire la alte instrumente, cum ar fi grep (așa cum se explică în Partea 1 a seriei LFCS) pentru a restrânge rezultatul la procesele dorite:
# ps -ef | grep -i squid | grep -v grep.
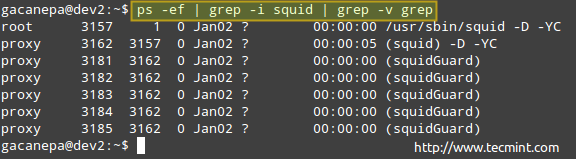
Lista proceselor de mai sus prezintă următoarele informații:
proprietarul procesului, PID, PID părinte (procesul părinte), utilizarea procesorului, ora la care a început comanda, tty (the? indică faptul că este un daemon), timpul cumulat al procesorului și comanda asociată procesului.
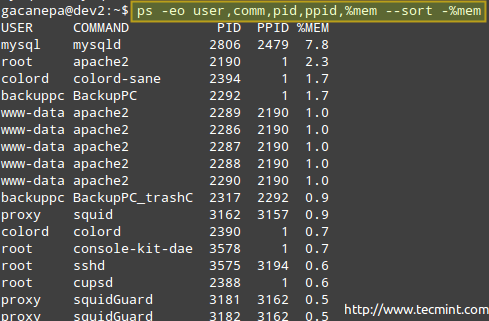
Cu toate acestea, poate că nu aveți nevoie de toate aceste informații și doriți să arătați proprietarului procesului, comanda care a început-o, PID și PPID, și procentul de memorie pe care îl folosește în prezent - în această ordine și sortați după utilizarea memoriei în ordine descrescătoare (rețineți că ps în mod implicit este sortat după PID).
# ps -eo user, comm, pid, ppid,% mem --sort -% mem.
Unde semnul minus din fața% mem indică sortarea în ordine descrescătoare.
Dacă, dintr-un anumit motiv, un proces începe să ia prea multe resurse de sistem și este posibil să pună în pericol ansamblul funcționalitatea sistemului, veți dori să opriți sau să întrerupeți executarea acestuia trecând unul dintre următoarele semnale folosind ucide programează-l. Alte motive pentru care ați lua în considerare acest lucru este atunci când ați început un proces în prim plan, dar doriți să îl întrerupeți și să îl reluați în fundal.
| Numele semnalului | Numărul semnalului | Descriere |
| SIGTERM | 15 | Omoară procesul cu grație. |
| SIGINT | 2 | Acesta este semnalul care este trimis când apăsăm Ctrl + C. Acesta își propune să întrerupă procesul, dar procesul îl poate ignora. |
| SIGKILL | 9 | De asemenea, acest semnal întrerupe procesul, dar o face necondiționat (utilizați cu grijă!), Deoarece un proces nu îl poate ignora. |
| LUMEA | 1 | Pe scurt pentru „Hang UP”, acest semnal instruiește demonii să recitească fișierul de configurare fără a opri procesul. |
| SIGTSTP | 20 | Întrerupeți executarea și așteptați să continuați. Acesta este semnalul care este trimis atunci când tastăm combinația de taste Ctrl + Z. |
| SIGSTOP | 19 | Procesul este întrerupt și nu mai atrage atenția din ciclurile CPU până când nu este repornit. |
| SIGCONT | 18 | Acest semnal indică procesului să reia executarea după ce a primit fie SIGTSTP, fie SIGSTOP. Acesta este semnalul trimis de shell atunci când folosim comenzile fg sau bg. |
Când execuția normală a unui anumit proces implică faptul că nu va fi trimisă nicio ieșire pe ecran în timp ce acesta este rularea, poate doriți să o porniți în fundal (adăugând un semn comercial la sfârșitul fișierului comanda).
numele procesului &
sau,
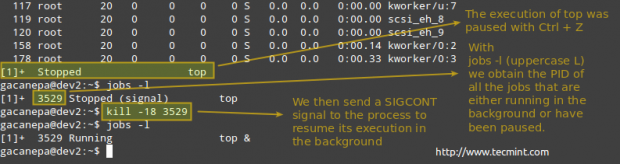
Odată ce a început să ruleze în prim-plan, întrerupeți-l și trimiteți-l în fundal cu
Ctrl + Z.
# ucide -18 PID.
Vă rugăm să rețineți că fiecare distribuție oferă instrumente pentru a opri / porni / reporni / reîncărca cu grație servicii comune, cum ar fi serviciu în sistemele bazate pe SysV sau systemctl în sisteme bazate pe sistem.
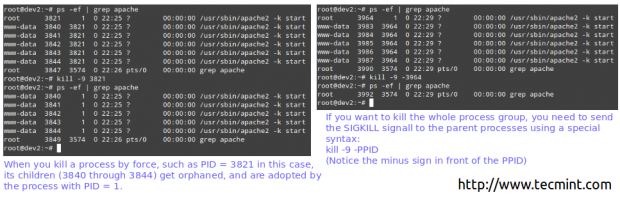
Dacă un proces nu răspunde acestor utilități, îl puteți ucide cu forța trimițându-i semnalul SIGKILL.
# ps -ef | grep apache. # ucide -9 3821.
Atunci când a existat orice fel de întrerupere în sistem (fie că este vorba de o întrerupere a curentului electric, o defecțiune hardware, o întrerupere planificată sau neplanificată a unui proces sau orice anomalie deloc), /var/log sunteți cei mai buni prieteni pentru a determina ce s-a întâmplat sau ce ar putea cauza problemele cu care vă confruntați.
# cd / var / log.

Unele dintre articolele din /var/log sunt fișiere text obișnuite, altele sunt directoare și altele sunt fișiere comprimate de jurnale (istorice) rotite. Veți dori să le verificați pe cele cu cuvântul eroare în numele lor, dar și inspecția celorlalți poate fi utilă.
Imaginați-vă acest scenariu. Clienții dvs. LAN nu pot imprima pe imprimante de rețea. Primul pas pentru a depana această situație va fi /var/log/cups director și vedeți ce este acolo.
Puteți utiliza coadă pentru a afișa ultimele 10 linii ale fișierului error_log sau tail -f error_log pentru o vizualizare în timp real a jurnalului.
# cd / var / log / cups. # ls. # cod eroare_log.
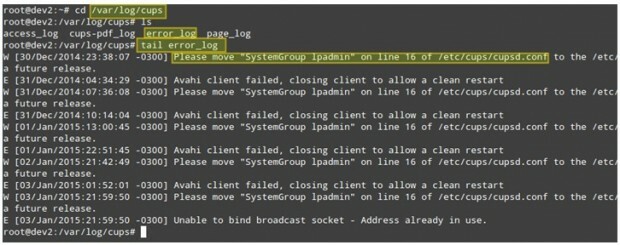
Captura de ecran de mai sus oferă câteva informații utile pentru a înțelege ce ar putea cauza problema. Rețineți că urmarea pașilor sau corectarea funcționării defectuoase a procesului poate să nu rezolve problema generală, dar dacă sunteți obișnuit chiar de la început pentru a verifica jurnalele de fiecare dată când apare o problemă (fie ea locală sau de rețea), veți fi cu siguranță pe dreapta urmări.
Deși eșecurile hardware pot fi dificil de depanat, ar trebui să verificați dmesg și jurnale de mesaje și grep pentru cuvinte conexe la o parte hardware presupusă defectă.
Imaginea de mai jos este preluată din /var/log/messages după ce căutați cuvântul eroare folosind următoarea comandă:
# mai puțin / var / log / messages | grep grep -i.
Putem vedea că avem o problemă cu două dispozitive de stocare: /dev/sdb și /dev/sdc, care la rândul său provoacă o problemă cu matricea RAID.

În acest articol am explorat câteva dintre instrumentele care vă pot ajuta să fiți mereu la curent cu starea generală a sistemului dvs. În plus, trebuie să vă asigurați că sistemul de operare și pachetele instalate sunt actualizate la cele mai recente versiuni stabile. Și niciodată, niciodată, nu uitați să verificați jurnalele! Apoi veți fi îndreptat în direcția corectă pentru a găsi soluția definitivă la orice problemă.
Nu ezitați să lăsați comentariile, sugestiile sau întrebările dvs. - dacă aveți vreunul - folosind formularul de mai jos.
