
Hadoop este un cadru de programare open source dezvoltat de apache pentru a procesa date mari. Folosește HDFS (Sistem de fișiere distribuite Hadoop) pentru a stoca datele în toate nodurile de date din cluster într-o manieră distributivă și mapreduce modelul pentru a procesa datele.

Namenode (NN) este un daemon master care controlează HDFS și Jobtracker (JT) este daemon master pentru motorul mapreduce.
În acest tutorial folosesc două CentOS 6.3 VM-uri „maestru' și 'nodul‘Anume. (master și nod sunt numele gazdei mele). IP-ul „master” este 172.21.17.175 iar IP-ul nodului este „172.21.17.188‘. Următoarele instrucțiuni funcționează și pe RHEL/CentOS 6.x versiuni.
[[e-mail protejat] ~] # nume de gazdă maestru
[[e-mail protejat] ~] # ifconfig | grep 'inet addr' | head -1 inet addr:172.21.17.175 Bcast: 172.21.19.255 Mască: 255.255.252.0
[[e-mail protejat] ~] # nume de gazdă nodul
[[e-mail protejat] ~] # ifconfig | grep 'inet addr' | head -1 inet addr:172.21.17.188 Bcast: 172.21.19.255 Mască: 255.255.252.0
Mai întâi asigurați-vă că toate gazdele cluster sunt acolo ‘/ Etc / hosts‘Fișier (pe fiecare nod), dacă nu aveți configurat DNS.
[[e-mail protejat] ~] # cat / etc / hosts 172.21.17.175 master. 172.21.17.188 nod
[[e-mail protejat] ~] # cat / etc / hosts 172.21.17.197 qabox. 172.21.17.176 ansible-ground
Folosim oficial CDH depozit de instalat CDH4 pe toate gazdele (Master și Node) dintr-un cluster.
Du-te la oficial Descărcare CDH pagină și apucați CDH4 (adică 4.6) sau puteți utiliza următoarele wget comanda pentru a descărca depozitul și a-l instala.
# wget http://archive.cloudera.com/cdh4/one-click-install/redhat/6/i386/cloudera-cdh-4-0.i386.rpm. # yum --nogpgcheck localinstall cloudera-cdh-4-0.i386.rpm
# wget http://archive.cloudera.com/cdh4/one-click-install/redhat/6/x86_64/cloudera-cdh-4-0.x86_64.rpm. # yum --nogpgcheck localinstall cloudera-cdh-4-0.x86_64.rpm
Înainte de a instala Hadoop Multinode Cluster, adăugați cheia publică Cloudera GPG în depozitul dvs. executând una dintre următoarele comenzi în conformitate cu arhitectura sistemului.
## pe sistem pe 32 de biți ## # rpm --import http://archive.cloudera.com/cdh4/redhat/6/i386/cdh/RPM-GPG-KEY-cloudera
## pe sistemul pe 64 de biți ## # rpm --import http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
Apoi, executați următoarea comandă pentru a instala și configura JobTracker și NameNode pe serverul principal.
[[e-mail protejat] ~] # yum clean all [[e-mail protejat] ~] # yum install hadoop-0.20-mapreduce-jobtracker
[[e-mail protejat] ~] # yum curăță toate. [[e-mail protejat] ~] # yum install hadoop-hdfs-namenode
Din nou, rulați următoarele comenzi pe serverul principal pentru a configura nodul de nume secundar.
[[e-mail protejat] ~] # yum clean all [[e-mail protejat] ~] # yum install hadoop-hdfs-secondarynam
Apoi, configurați tasktracker și datanode pe toate gazdele clusterului (Node), cu excepția JobTracker, NameNode și gazdele secundare (sau Standby) NameNode (pe nod în acest caz).
[[e-mail protejat] ~] # yum curăță toate. [[e-mail protejat] ~] # yum install hadoop-0.20-mapreduce-tasktracker hadoop-hdfs-datanode
Puteți instala clientul Hadoop pe o mașină separată (în acest caz l-am instalat pe datanode îl puteți instala pe orice mașină).
[[e-mail protejat] ~] # yum instalați hadoop-client
Acum, dacă am terminat cu pașii de mai sus, să mergem mai departe pentru a implementa hdfs (care se va face pe toate nodurile).
Copiați configurația implicită în /etc/hadoop director (pe fiecare nod din cluster).
[[e-mail protejat] ~] # cp -r /etc/hadoop/conf.dist /etc/hadoop/conf.my_cluster
[[e-mail protejat] ~] # cp -r /etc/hadoop/conf.dist /etc/hadoop/conf.my_cluster
Utilizare alternative comanda pentru a seta directorul personalizat, după cum urmează (pe fiecare nod din cluster).
[[e-mail protejat] ~] # alternatives --verbose --install / etc / hadoop / conf hadoop-conf /etc/hadoop/conf.my_cluster 50. citire / var / lib / alternatives / hadoop-conf [[e-mail protejat] ~] # alternatives --set hadoop-conf /etc/hadoop/conf.my_cluster
[[e-mail protejat] ~] # alternatives --verbose --install / etc / hadoop / conf hadoop-conf /etc/hadoop/conf.my_cluster 50. citire / var / lib / alternatives / hadoop-conf [[e-mail protejat] ~] # alternatives --set hadoop-conf /etc/hadoop/conf.my_cluster
Acum deschis 'core-site.xml‘Fișier și actualizare“fs.defaultFS”Pe fiecare nod din cluster.
[[e-mail protejat] conf] # cat /etc/hadoop/conf/core-site.xml
1.0 text / xslconfiguration.xsl fs.defaultFS hdfs: // master /
[[e-mail protejat] conf] # cat /etc/hadoop/conf/core-site.xml
1.0 text / xslconfiguration.xsl fs.defaultFS hdfs: // master /
Următoarea actualizare „dfs.permissions.superusergroup”În hdfs-site.xml pe fiecare nod din cluster.
[[e-mail protejat] conf] # cat /etc/hadoop/conf/hdfs-site.xml
1.0 text / xslconfiguration.xsl dfs.name.dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/name dfs.permissions.superusergroup hadoop
[[e-mail protejat] conf] # cat /etc/hadoop/conf/hdfs-site.xml
1.0 text / xslconfiguration.xsl dfs.name.dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/name dfs.permissions.superusergroup hadoop
Notă: Vă rugăm să vă asigurați că, configurația de mai sus este prezentă pe toate nodurile (efectuați pe un singur nod și rulați scp de copiat pe restul nodurilor).
Actualizați „dfs.name.dir sau dfs.namenode.name.dir” în ‘hdfs-site.xml’ pe NameNode (pe Master și Node). Vă rugăm să modificați valoarea așa cum este evidențiată.
[[e-mail protejat] conf] # cat /etc/hadoop/conf/hdfs-site.xml
dfs.namenode.name.dir fișier: /// data / 1 / dfs / nn, / nfsmount / dfs / nn
[[e-mail protejat] conf] # cat /etc/hadoop/conf/hdfs-site.xml
dfs.datanode.data.dir fișier: /// data / 1 / dfs / dn, / data / 2 / dfs / dn, / data / 3 / dfs / dn
Executați comenzile de mai jos pentru a crea structura directorului și pentru a gestiona permisiunile utilizatorilor pe mașina Namenode (Master) și Datanode (Node).
[[e-mail protejat]] # mkdir -p / data / 1 / dfs / nn / nfsmount / dfs / nn. [[e-mail protejat]] # chmod 700 / data / 1 / dfs / nn / nfsmount / dfs / nn
[[e-mail protejat]] # mkdir -p / data / 1 / dfs / dn / data / 2 / dfs / dn / data / 3 / dfs / dn / data / 4 / dfs / dn. [[e-mail protejat]] # chown -R hdfs: hdfs / data / 1 / dfs / nn / nfsmount / dfs / nn / data / 1 / dfs / dn / data / 2 / dfs / dn / data / 3 / dfs / dn / data / 4 / dfs / dn
Formatați Namenode (pe Master), emițând următoarea comandă.
[[e-mail protejat] conf] # sudo -u hdfs hdfs namenode -format
Adăugați următoarea proprietate la hdfs-site.xml fișier și înlocuiți valoarea așa cum se arată pe Master.
dfs.namenode.http-address 172.21.17.175:50070 Adresa și portul pe care va asculta interfața de utilizare NameNode.
Notă: În cazul nostru, valoarea ar trebui să fie adresa IP a mașinii virtuale master.
Acum să implementăm MRv1 (versiunea 1 de reducere a hărții). Deschis 'mapred-site.xml„Fișierul urmând valorile așa cum se arată.
[[e-mail protejat] conf] # cp hdfs-site.xml mapred-site.xml. [[e-mail protejat] conf] # vi mapred-site.xml. [[e-mail protejat] conf] # cat mapred-site.xml
1.0 text / xslconfiguration.xsl mapred.job.tracker maestru: 8021
Apoi, copiați „mapred-site.xml‘Fișier la nodul mașinii folosind următoarea comandă scp.
[[e-mail protejat]conf] # scp /etc/hadoop/conf/mapred-site.xml nod: / etc / hadoop / conf / mapred-site.xml 100% 200 0,2 KB / s 00:00
Acum configurați directoarele de stocare locală pentru a fi utilizate de MRv1 Daemons. Deschide din nou „mapred-site.xml„Înregistrați și efectuați modificările așa cum se arată mai jos pentru fiecare TaskTracker.
 mapred.local.dir Â/data/1/mapred/local,/data/2/mapred/local,/data/3/mapred/local
După specificarea acestor directoare înmapred-site.xml„Fișier, trebuie să creați directoarele și să le atribuiți permisiunile de fișiere corecte pe fiecare nod din clusterul dvs.
mkdir -p / data / 1 / mapred / local / data / 2 / mapred / local / data / 3 / mapred / local / data / 4 / mapred / local. chown -R mapred: hadoop / data / 1 / mapred / local / data / 2 / mapred / local / data / 3 / mapred / local / data / 4 / mapred / local
Acum executați următoarea comandă pentru a porni HDFS pe fiecare nod din cluster.
[[e-mail protejat] conf] # pentru x în `cd /etc/init.d; Ls hadoop-hdfs- * `; faceți sudo service $ x start; Terminat
[[e-mail protejat] conf] # pentru x în `cd /etc/init.d; Ls hadoop-hdfs- * `; faceți sudo service $ x start; Terminat
Este necesar să creați /tmp cu permisiuni adecvate exact așa cum se menționează mai jos.
[[e-mail protejat] conf] # sudo -u hdfs hadoop fs -mkdir / tmp. [[e-mail protejat] conf] # sudo -u hdfs hadoop fs -chmod -R 1777 / tmp
[[e-mail protejat] conf] # sudo -u hdfs hadoop fs -mkdir -p / var / lib / hadoop-hdfs / cache / mapred / mapred / staging. [[e-mail protejat] conf] # sudo -u hdfs hadoop fs -chmod 1777 / var / lib / hadoop-hdfs / cache / mapred / mapred / staging. [[e-mail protejat] conf] # sudo -u hdfs hadoop fs -chown -R mapred / var / lib / hadoop-hdfs / cache / mapred
Acum verificați structura fișierului HDFS.
[[e-mail protejat] conf] # sudo -u hdfs hadoop fs -ls -R / drwxrwxrwt - hdfs hadoop 0 2014-05-29 09:58 / tmp. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 / var. drwxr-xr-x - hdfs hadoop 0 29-05-2014 09:59 / var / lib. drwxr-xr-x - hdfs hadoop 0 29-05-2014 09:59 / var / lib / hadoop-hdfs. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 / var / lib / hadoop-hdfs / cache. drwxr-xr-x - mapred hadoop 0 29-05-2014 09:59 / var / lib / hadoop-hdfs / cache / mapred. drwxr-xr-x - mapred hadoop 0 2014-05-29 09:59 / var / lib / hadoop-hdfs / cache / mapred / mapred. drwxrwxrwt - mapred hadoop 0 29-05-2014 09:59 / var / lib / hadoop-hdfs / cache / mapred / mapred / staging
După ce porniți HDFS și creați „/tmp‘, Dar înainte de a porni JobTracker vă rugăm să creați directorul HDFS specificat de parametrul‘ mapred.system.dir ’(în mod implicit $ {hadoop.tmp.dir} / mapred / system și schimbați proprietarul în mapred.
[[e-mail protejat] conf] # sudo -u hdfs hadoop fs -mkdir / tmp / mapred / system. [[e-mail protejat] conf] # sudo -u hdfs hadoop fs -chown mapred: hadoop / tmp / mapred / system
Pentru a porni MapReduce: vă rugăm să porniți serviciile TT și JT.
[[e-mail protejat]conf] # service hadoop-0.20-mapreduce-tasktracker start Pornește Tasktracker: [OK] pornirea tasktracker-ului, conectarea la /var/log/hadoop-0.20-mapreduce/hadoop-hadoop-tasktracker-node.out
[[e-mail protejat] conf] # service hadoop-0.20-mapreduce-jobtracker start Pornirea Jobtracker: [OK] pornirea jobtracker, conectarea la /var/log/hadoop-0.20-mapreduce/hadoop-hadoop-jobtracker-master.out
Apoi, creați un director de start pentru fiecare utilizator hadoop. este recomandat să faceți acest lucru pe NameNode; de exemplu.
[[e-mail protejat] conf] # sudo -u hdfs hadoop fs -mkdir / user /[[e-mail protejat] conf] # sudo -u hdfs hadoop fs -chown /user/
Notă: unde este numele de utilizator Linux al fiecărui utilizator.
Alternativ, puteți să creați directorul de acasă după cum urmează.
[[e-mail protejat] conf] # sudo -u hdfs hadoop fs -mkdir / user / $ USER. [[e-mail protejat] conf] # sudo -u hdfs hadoop fs -chown $ USER / user / $ USER
Deschideți browserul și tastați adresa URL ca http://ip_address_of_namenode: 50070 pentru a accesa Namenode.

Deschideți o altă filă în browser și tastați adresa URL cahttp://ip_address_of_jobtracker: 50030 pentru a accesa JobTracker.
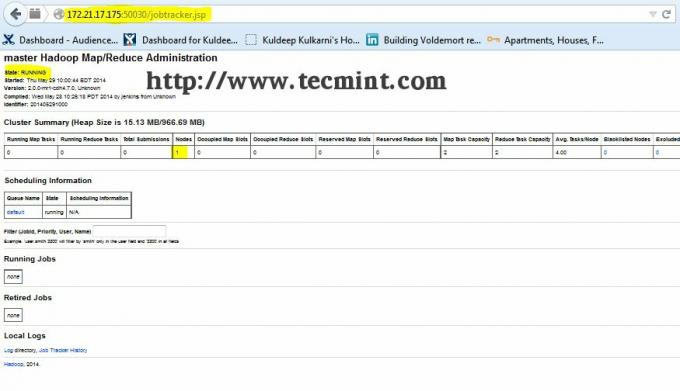
Această procedură a fost testată cu succes pe RHEL / CentOS 5.X / 6.X. Vă rugăm să comentați mai jos dacă aveți probleme cu instalarea, vă voi ajuta cu soluțiile.

