Hadoop to platforma programistyczna typu open source opracowana przez apache do przetwarzania dużych zbiorów danych. To używa HDFS (Rozproszony system plików Hadoop) do przechowywania danych we wszystkich węzłach danych w klastrze w sposób dystrybucyjny i mapreduce model do przetwarzania danych.

Nazwanode (NN) to główny demon, który kontroluje HDFS oraz Jobtracker (JT) jest głównym demonem silnika mapreduce.
W tym samouczku używam dwóch CentOS 6,3 Maszyny wirtualnegospodarz' oraz 'węzełmianowicie. (master i node to moje nazwy hostów). „Nadrzędny” adres IP to 172.21.17.175 a IP węzła to „172.21.17.188‘. Poniższe instrukcje również działają na RHEL/CentOS 6.x wersje.
[[e-mail chroniony] ~]# nazwa hosta gospodarz
[[e-mail chroniony] ~]# ifconfig|grep 'inet addr'|head -1 inet addr:172.21.17.175 Obsada: 172.21.19.255 Maska: 255.255.252.0
[[e-mail chroniony] ~]# nazwa hosta węzeł
[[e-mail chroniony] ~]# ifconfig|grep 'inet addr'|head -1 inet addr:172.21.17.188 Obsada: 172.21.19.255 Maska: 255.255.252.0
Najpierw upewnij się, że wszystkie hosty klastra są tam w „/itp/hosty‘ plik (na każdym węźle), jeśli nie masz skonfigurowanego DNS.
[[e-mail chroniony] ~]# cat /etc/hosts 172.21.17.175 master. 172.21.17.188 węzeł
[[e-mail chroniony] ~]# kot /etc/hosts 172.21.17.197 qabox. 172.21.17.176 ansibl-ziemia
Używamy oficjalnych CDH repozytorium do zainstalowania CDH4 na wszystkich hostach (głównym i węźle) w klastrze.
Przejdź do oficjalnego Pobierz CDH stronę i weź CDH4 (tj. 4.6) wersja lub możesz użyć następujących wget polecenie, aby pobrać repozytorium i zainstalować je.
# wget http://archive.cloudera.com/cdh4/one-click-install/redhat/6/i386/cloudera-cdh-4-0.i386.rpm. # mniam --nogpgcheck localinstall cloudera-cdh-4-0.i386.rpm
# wget http://archive.cloudera.com/cdh4/one-click-install/redhat/6/x86_64/cloudera-cdh-4-0.x86_64.rpm. # mniam --nogpgcheck localinstall cloudera-cdh-4-0.x86_64.rpm
Przed zainstalowaniem Hadoop Multinode Cluster dodaj publiczny klucz GPG Cloudera do swojego repozytorium, uruchamiając jedno z następujących poleceń zgodnie z architekturą systemu.
## w systemie 32-bitowym ## # rpm --import http://archive.cloudera.com/cdh4/redhat/6/i386/cdh/RPM-GPG-KEY-cloudera
## w systemie 64-bitowym ## # rpm --import http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
Następnie uruchom następujące polecenie, aby zainstalować i skonfigurować JobTracker i NameNode na serwerze głównym.
[[e-mail chroniony] ~]# mniam wyczyść wszystko [[e-mail chroniony] ~]# mniam zainstaluj hadoop-0.20-mapreduce-jobtracker
[[e-mail chroniony] ~]# mniam wyczyść wszystko. [[e-mail chroniony] ~]# mniam zainstaluj hadoop-hdfs-namenode
Ponownie uruchom następujące polecenia na serwerze głównym, aby skonfigurować dodatkowy węzeł nazwy.
[[e-mail chroniony] ~]# mniam wyczyść wszystko [[e-mail chroniony] ~]# mniam zainstaluj hadoop-hdfs-secondarynam
Następnie skonfiguruj narzędzie do śledzenia zadań i datanode na wszystkich hostach klastra (Node) z wyjątkiem hostów JobTracker, NameNode i Secondary (lub Standby) NameNode (w tym przypadku na węźle).
[[e-mail chroniony] ~]# mniam wyczyść wszystko. [[e-mail chroniony] ~]# mniam zainstaluj hadoop-0.20-mapreduce-tasktracker hadoop-hdfs-datanode
Możesz zainstalować klienta Hadoop na osobnym komputerze (w tym przypadku zainstalowałem go na węźle danych, możesz zainstalować go na dowolnym komputerze).
[[e-mail chroniony] ~]# mniam zainstaluj klienta hadoop
Teraz, jeśli skończyliśmy z powyższymi krokami, przejdźmy do wdrożenia hdfs (do zrobienia na wszystkich węzłach).
Skopiuj domyślną konfigurację do /etc/hadoop katalog ( na każdym węźle w klastrze ).
[[e-mail chroniony] ~]# cp -r /etc/hadoop/conf.dist /etc/hadoop/conf.my_cluster
[[e-mail chroniony] ~]# cp -r /etc/hadoop/conf.dist /etc/hadoop/conf.my_cluster
Posługiwać się alternatywy polecenie, aby ustawić katalog niestandardowy w następujący sposób (na każdym węźle w klastrze).
[[e-mail chroniony] ~]# alternatywy --verbose --install /etc/hadoop/conf hadoop-conf /etc/hadoop/conf.my_cluster 50. czytanie /var/lib/alternatives/hadoop-conf [[e-mail chroniony] ~]# alternatywy --set hadoop-conf /etc/hadoop/conf.my_cluster
[[e-mail chroniony] ~]# alternatywy --verbose --install /etc/hadoop/conf hadoop-conf /etc/hadoop/conf.my_cluster 50. czytanie /var/lib/alternatives/hadoop-conf [[e-mail chroniony] ~]# alternatywy --set hadoop-conf /etc/hadoop/conf.my_cluster
Teraz otwarte 'core-site.xml„ złóż i zaktualizuj”fs.defaultFS” na każdym węźle w klastrze.
[[e-mail chroniony] conf]# kot /etc/hadoop/conf/core-site.xml
1.0 tekst/xslkonfiguracja.xsl fs.defaultFS hdfs://główny/
[[e-mail chroniony] conf]# kot /etc/hadoop/conf/core-site.xml
1.0 tekst/xslkonfiguracja.xsl fs.defaultFS hdfs://główny/
Następna aktualizacja”dfs.permissions.superusergroup" w hdfs-site.xml na każdym węźle w klastrze.
[[e-mail chroniony] conf]# kot /etc/hadoop/conf/hdfs-site.xml
1.0 tekst/xslkonfiguracja.xsl dfs.nazwa.katalog /var/lib/hadoop-hdfs/cache/hdfs/dfs/name dfs.permissions.superusergroup hadoop
[[e-mail chroniony] conf]# kot /etc/hadoop/conf/hdfs-site.xml
1.0 tekst/xslkonfiguracja.xsl dfs.nazwa.katalog /var/lib/hadoop-hdfs/cache/hdfs/dfs/name dfs.permissions.superusergroup hadoop
Notatka: Upewnij się, że powyższa konfiguracja jest obecna na wszystkich węzłach (zrób na jednym węźle i uruchom scp skopiować na pozostałe węzły ).
Zaktualizuj „dfs.name.dir lub dfs.namenode.name.dir” w „hdfs-site.xml” na NameNode (na Master i Node). Zmień podświetloną wartość.
[[e-mail chroniony] conf]# kot /etc/hadoop/conf/hdfs-site.xml
dfs.namenode.name.dir file:///data/1/dfs/nn,/nfsmount/dfs/nn
[[e-mail chroniony] conf]# kot /etc/hadoop/conf/hdfs-site.xml
dfs.datanode.data.dir plik:///data/1/dfs/dn,/data/2/dfs/dn,/data/3/dfs/dn
Wykonaj poniższe polecenia, aby utworzyć strukturę katalogów i zarządzać uprawnieniami użytkowników na maszynie Namenode (Master) i Datanode (Node).
[[e-mail chroniony]]# mkdir -p /data/1/dfs/nn /nfsmount/dfs/nn. [[e-mail chroniony]]# chmod 700 /data/1/dfs/nn /nfsmount/dfs/nn
[[e-mail chroniony]]# mkdir -p /data/1/dfs/dn /data/2/dfs/dn /data/3/dfs/dn /data/4/dfs/dn. [[e-mail chroniony]]# chown -R hdfs: hdfs /data/1/dfs/nn /nfsmount/dfs/nn /data/1/dfs/dn /data/2/dfs/dn /data/3/dfs/dn /data/4 /dfs/dn
Sformatuj Namenode (na Master), wydając następujące polecenie.
[[e-mail chroniony] conf]# sudo -u hdfs hdfs nazwanode -format
Dodaj następującą właściwość do hdfs-site.xml plik i zamień wartość, jak pokazano na Master.
dfs.namenode.http-adres 172.21.17.175:50070 Adres i port, na którym będzie nasłuchiwać interfejs użytkownika NameNode.
Notatka: W naszym przypadku wartością powinien być adres ip głównej maszyny wirtualnej.
Teraz wdróżmy MRv1 (Map-reduce version 1 ). Otwarty 'mapred-site.xml‘ plik z następującymi wartościami, jak pokazano.
[[e-mail chroniony] conf]# cp hdfs-site.xml mapred-site.xml. [[e-mail chroniony] conf]# vi mapred-site.xml. [[e-mail chroniony] conf]# cat mapred-site.xml
1.0 tekst/xslkonfiguracja.xsl mapred.job.tracker mistrz: 8021
Następnie skopiuj „mapred-site.xml‘ plik do maszyny węzła za pomocą następującego polecenia scp.
[[e-mail chroniony]conf]# scp /etc/hadoop/conf/mapred-site.xml node:/etc/hadoop/conf/ mapred-site.xml 100% 200 0.2KB/s 00:00
Teraz skonfiguruj lokalne katalogi magazynu do użycia przez demony MRv1. Znowu otwarte ‘mapred-site.xmli wprowadź zmiany, jak pokazano poniżej dla każdego TaskTrackera.
 mapred.lokalny.dir Â/data/1/mapred/local,/data/2/mapred/local,/data/3/mapred/local
Po określeniu tych katalogów w „mapred-site.xml„, musisz utworzyć katalogi i przypisać im odpowiednie uprawnienia do plików w każdym węźle w klastrze.
mkdir -p /data/1/mapred/local /data/2/mapred/local /data/3/mapred/local /data/4/mapred/local. chown -R mapred: hadoop /data/1/mapred/local /data/2/mapred/local /data/3/mapred/local /data/4/mapred/local
Teraz uruchom następujące polecenie, aby uruchomić system HDFS na każdym węźle w klastrze.
[[e-mail chroniony] conf]# for x w `cd /etc/init.d; ls hadoop-hdfs-*`; czy usługa sudo $x start; zrobione
[[e-mail chroniony] conf]# for x w `cd /etc/init.d; ls hadoop-hdfs-*`; czy usługa sudo $x start; zrobione
Wymagane jest stworzenie /tmp z odpowiednimi uprawnieniami dokładnie tak, jak wspomniano poniżej.
[[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -mkdir /tmp. [[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
[[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -mkdir -p /var/lib/hadoop-hdfs/cache/mapred/mapred/staging. [[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -chmod 1777 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging. [[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -chown -R mapred /var/lib/hadoop-hdfs/cache/mapred
Teraz sprawdź strukturę plików HDFS.
[[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -ls -R / drwxrwxrwt - hdfs hadoop 0 2014-05-29 09:58 /tmp. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var/lib. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache. drwxr-xr-x - mapred hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred. drwxr-xr-x - mapred hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred. drwxrwxrwt - mapred hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging
Po uruchomieniu HDFS i utworzeniu ‘/tmp„, ale przed uruchomieniem JobTrackera utwórz katalog HDFS określony przez parametr „mapred.system.dir” (domyślnie ${hadoop.tmp.dir}/mapred/system i zmień właściciela na mapred).
[[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -mkdir /tmp/mapred/system. [[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -chown mapred: hadoop /tmp/mapred/system
Aby uruchomić MapReduce: uruchom usługi TT i JT.
[[e-mail chroniony]conf]# service hadoop-0.20-mapreduce-tasktracker start Uruchamianie Tasktrackera: [ OK ] uruchamianie Tasktrackera, logowanie do /var/log/hadoop-0.20-mapreduce/hadoop-hadoop-tasktracker-node.out
[[e-mail chroniony] conf]# service hadoop-0.20-mapreduce-jobtracker start Uruchamianie Jobtrackera: [ OK ] uruchamianie Jobtrackera, logowanie do /var/log/hadoop-0.20-mapreduce/hadoop-hadoop-jobtracker-master.out
Następnie utwórz katalog domowy dla każdego użytkownika hadoop. zalecane jest zrobienie tego na NameNode; na przykład.
[[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -mkdir /użytkownik/[[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -chown /user/
Notatka: gdzie jest nazwą użytkownika Linuksa każdego użytkownika.
Alternatywnie możesz utworzyć katalog domowy w następujący sposób.
[[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -mkdir /user/$USER. [[e-mail chroniony] conf]# sudo -u hdfs hadoop fs -chown $USER /user/$USER
Otwórz przeglądarkę i wpisz adres URL jako http://ip_address_of_namenode: 50070 aby uzyskać dostęp do Namenode.

Otwórz kolejną kartę w przeglądarce i wpisz adres URL jakohttp://ip_address_of_jobtracker: 50030 aby uzyskać dostęp do JobTrackera.
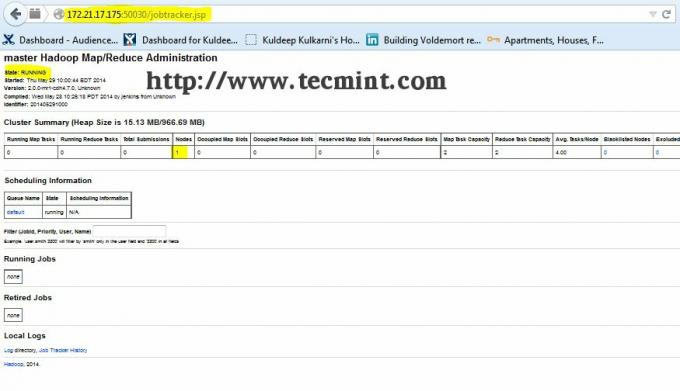
Ta procedura została pomyślnie przetestowana na RHEL/CentOS 5.X/6.X. Proszę o komentarz poniżej, jeśli napotkasz jakiekolwiek problemy z instalacją, pomogę Ci z rozwiązaniami.
