
Hadoop-cluster bouwen is een stapsgewijs proces waarbij het proces begint bij de aanschaf van de benodigde servers, montage in het rack, bekabeling, etc. en plaatsen in Datacenter. Dan moeten we het besturingssysteem installeren, dit kan worden gedaan met behulp van kickstart in de realtime omgeving als de clustergrootte groot is. Nadat het besturingssysteem is geïnstalleerd, moeten we de server voorbereiden voor Hadoop-installatie en moeten we de servers voorbereiden volgens het beveiligingsbeleid van de organisatie.
In dit artikel zullen we de vereisten op OS-niveau doornemen die worden aanbevolen door Cloudera. We hebben ook enkele belangrijke tips voor het verharden van beveiliging uitgelicht volgens de: CIS-benchmark voor productieservers. Deze veiligheidsverharding kan verschillen naargelang de vereisten.
Hier bespreken we de vereisten op het besturingssysteem die worden aanbevolen door: Cloudera.
Standaard, Transparante grote pagina (THP) is ingeschakeld op Linux-machines die slecht communiceren met Hadoop workloads en het verslechtert de algehele prestaties van Cluster. We moeten dit dus uitschakelen om optimale prestaties te bereiken met behulp van het volgende: echo commando.
# echo never > /sys/kernel/mm/transparent_hugepage/enabled # echo never > /sys/kernel/mm/transparent_hugepage/defrag

Standaard is de vm.swappiness waarde is 30 of 60 voor de meeste Linux-machines.
# sysctl vm.swappiness.

Een hogere waarde hebben van wisselvalligheid wordt niet aanbevolen voor Hadoop servers, omdat dit kan leiden tot lange pauzes voor het ophalen van afval. En met de hogere swappiness-waarde kunnen gegevens in de cache worden opgeslagen om geheugen uit te wisselen, zelfs als we voldoende geheugen hebben. Door de swappiness-waarde te verlagen, kan het fysieke geheugen meer geheugenpagina's bevatten.
# sysctl vm.swappiness=1.
Of u kunt het bestand openen /etc/sysctl.conf en voeg toe "vm.swappiness=1" op het eind.
vm.swappiness=1.
Elke Hadoop-server heeft zijn eigen verantwoordelijkheid met meerdere services (daemons) daarop draaien. Alle servers zullen frequent met elkaar communiceren voor verschillende doeleinden.
Bijvoorbeeld, datanode zal elke 3 seconden een hartslag naar Namenode sturen, zodat: naamknooppunt zal ervoor zorgen dat de datanode is levend.
Als alle communicatie tussen de daemons over verschillende servers via de Firewall verloopt, is dat een extra belasting voor Hadoop. Het is dus het beste om de firewall in de afzonderlijke servers in Cluster uit te schakelen.
# iptables-save > ~/firewall.rules. # systemctl stop firewalld. # systemctl firewall uitschakelen.

Als we de SELinux ingeschakeld, zal dit problemen veroorzaken tijdens de installatie Hadoop. Zoals Hadoop is een clustercomputing, Cloudera-manager zal alle servers in het cluster bereiken om Hadoop en zijn services te installeren en waar nodig de nodige servicedirectory's maken.
Als SELinux is ingeschakeld, kan Cloudera Manager de installatie niet regelen zoals het wil. Het inschakelen van SELinux zal dus een obstakel zijn voor Hadoop en het zal prestatieproblemen veroorzaken.
U kunt de status van SELinux door het onderstaande commando te gebruiken.
# sestatus.

Open nu de /etc/selinux/config bestand en uitschakelen SELINUX zoals getoond.
SELinux=uitgeschakeld.

Na het uitschakelen van SELinux, moet je het systeem opnieuw opstarten om het actief te maken.
# opnieuw opstarten.
In Hadoop-cluster, alle servers zouden moeten zijn Tijd gesynchroniseerd om klokoffsetfouten te voorkomen. De RHEL/CentOS 7 heeft chronyd ingebouwd voor netwerkklok/tijdsynchronisatie, maar Cloudera raadt aan om te gebruiken NTP.
We moeten installeren NTP en configureer het. Eenmaal geïnstalleerd, stop 'chronyd' en uitschakelen. Omdat, als een server beide heeft ntpd en chronyd actief is, zal Cloudera Manager overwegen: chronyd voor tijdsynchronisatie, dan zal het een fout geven, zelfs als we de tijd hebben gesynchroniseerd via ntp.
# yum -y installeer ntp. # systemctl start ntpd. # systemctl schakel ntpd in. # systemctl-status ntpd.

Zoals we hierboven vermeldden, hebben we het niet nodig chronyd actief zoals we gebruiken ntpd. Controleer de status van chronyd, als het actief is, stop en schakel uit. Standaard, chronyd wordt gestopt, tenzij we het starten na de installatie van het besturingssysteem, we moeten het alleen uitschakelen voor een veiligere kant.
# systemctl status chronyd. # systemctl schakel chronyd uit.

We moeten de hostnaam met FQDN (Volledig gekwalificeerde domein naam). Elke server moet een unieke canonieke naam hebben. Om de hostnaam op te lossen, moeten we ofwel de DNS configureren of /etc/hosts. Hier gaan we configureren /etc/hosts.
IP-adres en FQDN van elke server moeten worden ingevoerd in /etc/hosts van alle servers. Dan alleen Cloudera-manager kan alle servers communiceren met zijn hostnaam.
# hostnamectl set-hostname master1.tecmint.com.
Configureer vervolgens /etc/hosts het dossier. Bijvoorbeeld: – Als we een cluster met 5 knooppunten hebben met 2 masters en 3 worker, kunnen we de. configureren /etc/hosts zoals hieronder.

Zoals Hadoop is gemaakt van Java, zouden alle hosts moeten hebben Java geïnstalleerd met de juiste versie. Hier gaan we hebben OpenJDK. Standaard, Cloudera-manager zal installeren OracleJDK maar Cloudera raadt aan om OpenJDK.
# yum -y installeer java-1.8.0-openjdk-devel. # java-versie.

In deze sectie gaan we naar Harden Hadoop-omgevingsbeveiliging ...
Automontage ‘autofs' maakt automatische montage van fysieke apparaten zoals USB, CD/DVD mogelijk. Gebruikers met fysieke toegang kunnen hun USB of een willekeurig opslagmedium aansluiten om toegang te krijgen tot invoeggegevens. Gebruik de onderstaande opdrachten om te controleren of het is uitgeschakeld of niet, zo niet, schakel het dan uit.
# systemctl schakel autofs uit. # systemctl is ingeschakeld autofs.

De eten configuratiebestand bevat essentiële informatie over opstartinstellingen en referenties om opstartopties te ontgrendelen. Het grub-configuratiebestand 'grub.cfg' gevestigd in /boot/grub2 en het is gelinkt als /etc/grub2.conf en zorg ervoor dat grub.cfg is eigendom van root gebruiker.
# cd /boot/grub2.

Gebruik de onderstaande opdracht om te controleren: Uid en Gid zijn beide 0/root en 'groep' of 'ander’ mag geen toestemming hebben.
# stat /boot/grub2/grub.cfg.
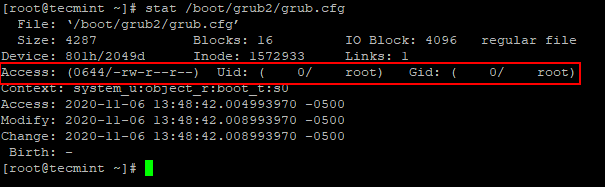
Gebruik de onderstaande opdracht om machtigingen van anderen en groepen te verwijderen.
# chmod og-rwx /boot/grub2/grub.cfg.

Deze instelling vermijdt ander ongeoorloofd herstarten van de server. dat wil zeggen, er is een wachtwoord nodig om de server opnieuw op te starten. Als het niet is ingesteld, kunnen onbevoegde gebruikers de server opstarten en wijzigingen aanbrengen in de opstartpartities.
Gebruik de onderstaande opdracht om het wachtwoord in te stellen.
# grub2-mkpasswd-pbkdf2.

Voeg het hierboven gemaakte wachtwoord toe aan: /etc/grub.d/01_users het dossier.

Genereer vervolgens het grub-configuratiebestand opnieuw.
# grub2-mkconfig > /boot/grub2/grub.cfg.

Prelink is een softwareprogramma dat de kwetsbaarheid in een server kan vergroten als kwaadwillende gebruikers gemeenschappelijke bibliotheken kunnen compromitteren zoals: libc.
Gebruik de onderstaande opdracht om het te verwijderen.
# yum verwijder prelink.
We moeten overwegen om sommige services/protocollen uit te schakelen om mogelijke aanvallen te voorkomen.
# systemctl uitschakelen
We hebben de servervoorbereiding doorlopen die bestaat uit: Cloudera Hadoop Vereisten en wat beveiligingsverharding. Vereisten op besturingssysteemniveau gedefinieerd door Cloudera zijn verplicht voor een soepele installatie van Hadoop. Gewoonlijk wordt een verhardingsscript opgesteld met behulp van de CIS-benchmark en gebruikt om niet-naleving in realtime te controleren en op te lossen.
In een minimale installatie van CentOS/RHEL 7, worden alleen basisfunctionaliteiten/software geïnstalleerd, dit voorkomt ongewenste risico's en kwetsbaarheden. Ook al is het een minimale installatie, meerdere iteraties van beveiligingsaudits zullen eerder worden uitgevoerd het installeren van Hadoop, zelfs na het bouwen van het cluster, voordat het cluster wordt verplaatst naar Bediening/productie.