
Hadoop is een open source programmeerraamwerk ontwikkeld door apache om big data te verwerken. Het gebruikt HDFS (Hadoop gedistribueerd bestandssysteem) om de gegevens op alle datanodes in het cluster op een distributieve manier op te slaan en een mapreduce-model om de gegevens te verwerken.

naamknooppunt (NN) is een master-daemon die controleert HDFS en Jobtracker (JT) is master daemon voor mapreduce engine.
In deze tutorial gebruik ik twee CentOS 6.3 VM's 'meester' en 'knooppunt' nl. (master en node zijn mijn hostnamen). Het 'master'-IP is 172.21.17.175 en node-IP is '172.21.17.188‘. De volgende instructies werken ook op: RHEL/CentOS 6.x versies.
[[e-mail beveiligd] ~]# hostnaam meester
[[e-mail beveiligd] ~]# ifconfig|grep 'inet addr'|head -1 inet addr:172.21.17.175 Bcast: 172.21.19.255 Masker: 255.255.252.0
[[e-mail beveiligd] ~]# hostnaam knooppunt
[[e-mail beveiligd] ~]# ifconfig|grep 'inet addr'|head -1 inet addr:172.21.17.188 Bcast: 172.21.19.255 Masker: 255.255.252.0
Zorg er eerst voor dat alle clusterhosts aanwezig zijn ‘/etc/hosts' bestand (op elk knooppunt), als u geen DNS hebt ingesteld.
[[e-mail beveiligd] ~]# cat /etc/hosts 172.21.17.175 master. 172.21.17.188 knooppunt
[[e-mail beveiligd] ~]# cat /etc/hosts 172.21.17.197 qabox. 172.21.17.176 weerbare grond
We gebruiken officiële CDH opslagplaats om te installeren CDH4 op alle hosts (Master en Node) in een cluster.
Ga naar officieel CDH-download pagina en pak de CDH4 (d.w.z. 4.6) versie of u kunt het volgende gebruiken: wget commando om de repository te downloaden en te installeren.
# wget http://archive.cloudera.com/cdh4/one-click-install/redhat/6/i386/cloudera-cdh-4-0.i386.rpm. # yum --nogpgcheck localinstall cloudera-cdh-4-0.i386.rpm
# wget http://archive.cloudera.com/cdh4/one-click-install/redhat/6/x86_64/cloudera-cdh-4-0.x86_64.rpm. # yum --nogpgcheck localinstall cloudera-cdh-4-0.x86_64.rpm
Voordat u Hadoop Multinode Cluster installeert, voegt u de Cloudera Public GPG Key toe aan uw repository door een van de volgende opdrachten uit te voeren volgens uw systeemarchitectuur.
## op 32-bits systeem ## # rpm --import http://archive.cloudera.com/cdh4/redhat/6/i386/cdh/RPM-GPG-KEY-cloudera
## op 64-bits systeem ## # rpm --import http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
Voer vervolgens de volgende opdracht uit om JobTracker en NameNode op de hoofdserver te installeren en in te stellen.
[[e-mail beveiligd] ~]# lekker alles schoonmaken [[e-mail beveiligd] ~]# yum installeer hadoop-0.20-mapreduce-jobtracker
[[e-mail beveiligd] ~]# lekker alles opruimen. [[e-mail beveiligd] ~]# yum installeer hadoop-hdfs-namenode
Voer nogmaals de volgende opdrachten uit op de hoofdserver om het secundaire naamknooppunt in te stellen.
[[e-mail beveiligd] ~]# lekker alles schoonmaken [[e-mail beveiligd] ~]# yum install hadoop-hdfs-secondarynam
Stel vervolgens tasktracker & datanode in op alle clusterhosts (Node) behalve de JobTracker, NameNode en Secondary (of Standby) NameNode-hosts (in dit geval op het knooppunt).
[[e-mail beveiligd] ~]# lekker alles opruimen. [[e-mail beveiligd] ~]# yum installeer hadoop-0.20-mapreduce-tasktracker hadoop-hdfs-datanode
Je kunt de Hadoop-client op een aparte machine installeren (in dit geval heb ik het op datanode geïnstalleerd, je kunt het op elke machine installeren).
[[e-mail beveiligd] ~]# yum installeer hadoop-client
Als we nu klaar zijn met bovenstaande stappen, gaan we verder met het implementeren van hdfs (dit moet op alle knooppunten worden gedaan).
Kopieer de standaardconfiguratie naar /etc/hadoop directory ( op elk knooppunt in cluster ).
[[e-mail beveiligd] ~]# cp -r /etc/hadoop/conf.dist /etc/hadoop/conf.my_cluster
[[e-mail beveiligd] ~]# cp -r /etc/hadoop/conf.dist /etc/hadoop/conf.my_cluster
Gebruik maken van alternatieven commando om uw aangepaste map als volgt in te stellen ( op elk knooppunt in cluster ).
[[e-mail beveiligd] ~]# alternatieven --verbose --install /etc/hadoop/conf hadoop-conf /etc/hadoop/conf.my_cluster 50. lezen /var/lib/alternatives/hadoop-conf [[e-mail beveiligd] ~]# alternatieven --set hadoop-conf /etc/hadoop/conf.my_cluster
[[e-mail beveiligd] ~]# alternatieven --verbose --install /etc/hadoop/conf hadoop-conf /etc/hadoop/conf.my_cluster 50. lezen /var/lib/alternatives/hadoop-conf [[e-mail beveiligd] ~]# alternatieven --set hadoop-conf /etc/hadoop/conf.my_cluster
Nu open 'core-site.xml' bestand en update "fs.defaultFS" op elk knooppunt in cluster.
[[e-mail beveiligd] conf]# cat /etc/hadoop/conf/core-site.xml
1.0 tekst/xslconfiguratie.xsl fs.defaultFS hdfs://master/
[[e-mail beveiligd] conf]# cat /etc/hadoop/conf/core-site.xml
1.0 tekst/xslconfiguratie.xsl fs.defaultFS hdfs://master/
Volgende update “dfs.permissions.superusergroup" in hdfs-site.xml op elk knooppunt in cluster.
[[e-mail beveiligd] conf]# cat /etc/hadoop/conf/hdfs-site.xml
1.0 tekst/xslconfiguratie.xsl dfs.name.dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/name dfs.permissions.superusergroup hadoop
[[e-mail beveiligd] conf]# cat /etc/hadoop/conf/hdfs-site.xml
1.0 tekst/xslconfiguratie.xsl dfs.name.dir /var/lib/hadoop-hdfs/cache/hdfs/dfs/name dfs.permissions.superusergroup hadoop
Opmerking: Zorg ervoor dat de bovenstaande configuratie aanwezig is op alle knooppunten (doe op één knooppunt en voer uit) scp om op de rest van de knooppunten te kopiëren).
Update “dfs.name.dir of dfs.namenode.name.dir” in ‘hdfs-site.xml’ op de NameNode (op Master en Node). Wijzig de waarde zoals gemarkeerd.
[[e-mail beveiligd] conf]# cat /etc/hadoop/conf/hdfs-site.xml
dfs.namenode.name.dir file:///data/1/dfs/nn,/nfsmount/dfs/nn
[[e-mail beveiligd] conf]# cat /etc/hadoop/conf/hdfs-site.xml
dfs.datanode.data.dir bestand:///data/1/dfs/dn,/data/2/dfs/dn,/data/3/dfs/dn
Voer onderstaande opdrachten uit om de directorystructuur te maken en gebruikersrechten te beheren op de Namenode (Master) en Datanode (Node) machine.
[[e-mail beveiligd]]# mkdir -p /data/1/dfs/nn /nfsmount/dfs/nn. [[e-mail beveiligd]]# chmod 700 /data/1/dfs/nn /nfsmount/dfs/nn
[[e-mail beveiligd]]# mkdir -p /data/1/dfs/dn /data/2/dfs/dn /data/3/dfs/dn /data/4/dfs/dn. [[e-mail beveiligd]]# chown -R hdfs: hdfs /data/1/dfs/nn /nfsmount/dfs/nn /data/1/dfs/dn /data/2/dfs/dn /data/3/dfs/dn /data/4 /dfs/dn
Formatteer de Namenode (op Master), door het volgende commando uit te voeren.
[[e-mail beveiligd] conf]# sudo -u hdfs hdfs namenode -format
Voeg de volgende eigenschap toe aan de hdfs-site.xml bestand en vervang de waarde zoals getoond op Master.
dfs.namenode.http-adres 172.21.17.175:50070 Het adres en de poort waarop de NameNode UI zal luisteren.
Opmerking: In ons geval moet de waarde het ip-adres van de master-VM zijn.
Laten we nu MRv1 (Map-reduce versie 1) implementeren. Open 'mapred-site.xml' bestand volgende waarden zoals weergegeven.
[[e-mail beveiligd] conf]# cp hdfs-site.xml mapred-site.xml. [[e-mail beveiligd] conf]# vi mapred-site.xml. [[e-mail beveiligd] conf]# cat mapred-site.xml
1.0 tekst/xslconfiguratie.xsl mapred.job.tracker meester: 8021
Kopieer vervolgens ‘mapred-site.xml' bestand naar node machine met behulp van de volgende scp-opdracht.
[[e-mail beveiligd]conf]# scp /etc/hadoop/conf/mapred-site.xml node:/etc/hadoop/conf/ mapred-site.xml 100% 200 0.2KB/s 00:00
Configureer nu lokale opslagmappen voor gebruik door MRv1-daemons. Weer geopend’mapred-site.xml' bestand en breng wijzigingen aan zoals hieronder getoond voor elke TaskTracker.
 mapred.local.dir Â/data/1/mapred/local,/data/2/mapred/local,/data/3/mapred/local
Na het specificeren van deze mappen in de ‘mapred-site.xml' bestand, moet u de mappen maken en de juiste bestandsmachtigingen eraan toewijzen op elk knooppunt in uw cluster.
mkdir -p /data/1/mapred/local /data/2/mapred/local /data/3/mapred/local /data/4/mapred/local. chown -R mapred: hadoop /data/1/mapred/local /data/2/mapred/local /data/3/mapred/local /data/4/mapred/local
Voer nu de volgende opdracht uit om HDFS op elk knooppunt in het cluster te starten.
[[e-mail beveiligd] conf]# voor x in `cd /etc/init.d; ls hadoop-hdfs-*`; start sudo-service $x; klaar
[[e-mail beveiligd] conf]# voor x in `cd /etc/init.d; ls hadoop-hdfs-*`; start sudo-service $x; klaar
Het is vereist om te creëren /tmp met de juiste machtigingen precies zoals hieronder vermeld.
[[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -mkdir /tmp. [[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
[[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -mkdir -p /var/lib/hadoop-hdfs/cache/mapred/mapred/staging. [[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -chmod 1777 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging. [[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -chown -R mapred /var/lib/hadoop-hdfs/cache/mapred
Controleer nu de HDFS-bestandsstructuur.
[[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -ls -R / drwxrwxrwt - hdfs hadoop 0 2014-05-29 09:58 /tmp. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var/lib. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs. drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache. drwxr-xr-x - mapred hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred. drwxr-xr-x - mapred hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred. drwxrwxrwt - mapred hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging
Nadat u HDFS hebt gestart en '/tmp', maar voordat u de JobTracker start, maakt u de HDFS-directory aan die is gespecificeerd door de parameter 'mapred.system.dir' (standaard ${hadoop.tmp.dir}/mapred/system en wijzigt u de eigenaar in mapred.
[[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -mkdir /tmp/mapred/system. [[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -chown mapred: hadoop /tmp/mapred/system
Om MapReduce te starten: start de TT- en JT-services.
[[e-mail beveiligd]conf]# service hadoop-0.20-mapreduce-tasktracker start Tasktracker starten: [ OK ] tasktracker starten, inloggen op /var/log/hadoop-0.20-mapreduce/hadoop-hadoop-tasktracker-node.out
[[e-mail beveiligd] conf]# service hadoop-0.20-mapreduce-jobtracker start Jobtracker starten: [ OK ] jobtracker starten, inloggen op /var/log/hadoop-0.20-mapreduce/hadoop-hadoop-jobtracker-master.out
Maak vervolgens een thuismap voor elke hadoop-gebruiker. het wordt aanbevolen om dit op NameNode te doen; bijvoorbeeld.
[[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -mkdir /user/[[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -chown /user/
Opmerking: waar is de Linux-gebruikersnaam van elke gebruiker.
Als alternatief kunt u de homedirectory als volgt maken.
[[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -mkdir /user/$USER. [[e-mail beveiligd] conf]# sudo -u hdfs hadoop fs -chown $USER /user/$USER
Open uw browser en typ de url als http://ip_address_of_namenode: 50070 om toegang te krijgen tot Namenode.

Open een ander tabblad in uw browser en typ de url alshttp://ip_address_of_jobtracker: 50030 om toegang te krijgen tot JobTracker.
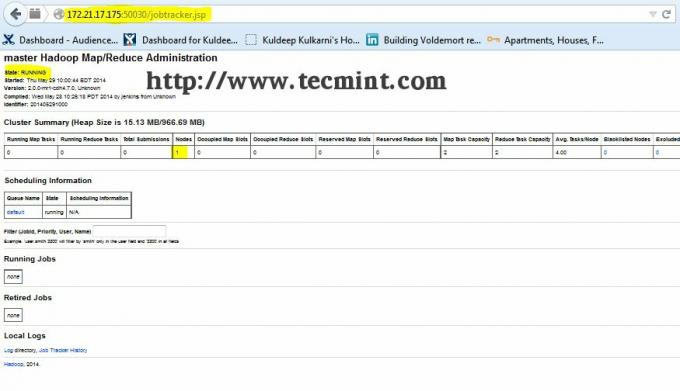
Deze procedure is met succes getest op: RHEL/CentOS 5.X/6.X. Reageer hieronder als u problemen ondervindt met de installatie, ik zal u helpen met de oplossingen.
