Linux fonds paziņoja LFCS (Linux Foundation sertificēts sistēmas administrators) sertifikācija, jauna programma, kuras mērķis ir palīdzēt indivīdiem visā pasaulē iegūt sertifikātu pamata un starpposma sistēmas administrēšanas uzdevumos Linux sistēmām. Tas ietver darbības sistēmu un pakalpojumu atbalstu, kā arī tiešu problēmu novēršanu un analīzi, kā arī gudru lēmumu pieņemšanu, lai problēmas pārnestu uz inženieru komandām.

Lūdzu, noskatieties šo videoklipu, kas parāda par Linux fonda sertifikācijas programmu.
Sērijas nosaukums būs Gatavošanās LFCS (Linux Foundation sertificēts sistēmas administrators) Daļas 1 cauri 10 un aptver šādas tēmas Ubuntu, CentOS un openSUSE:
1. daļa: Kā izmantot komandu GNU “sed”, lai izveidotu, rediģētu un manipulētu ar failiem Linux
Svarīgs: Sakarā ar izmaiņām LFCS sertifikācijas prasībās spēkā Februāris 2, 2016šeit iekļautajām LFCS sērijām mēs iekļaujam šādas nepieciešamās tēmas. Lai sagatavotos šim eksāmenam, jūs ļoti iesakām izmantot LFCE sērija arī.
Šī ziņa ir daļa 1 no a 20 pamācību sērija, kas aptvers nepieciešamos domēnus un kompetences, kas nepieciešamas LFCS sertifikācijas eksāmens. To sakot, aktivizējiet savu termināli un sāksim.
Linux uztver programmu ievadi un izvadi kā rakstzīmju straumes (vai secības). Lai sāktu izprast novirzīšanu un caurules, mums vispirms ir jāsaprot trīs vissvarīgākie I/O (ieejas un izejas) plūsmu veidi, kas patiesībā ir īpaši faili (pēc vienošanās UNIX un Linux datu plūsmas un perifērijas ierīces vai ierīces faili tiek uzskatīti arī par parastajiem failiem).
Atšķirība starp > (pāradresācijas operators) un | (cauruļvada operators) ir tas, ka, lai gan pirmais savieno komandu ar failu, pēdējais savieno komandas izvadi ar citu komandu.
# komanda> fails. # komanda1 | komanda2.
Tā kā novirzīšanas operators klusi izveido vai pārraksta failus, mums tas ir jāizmanto ļoti piesardzīgi un nekad nedrīkst sajaukt ar cauruļvadu. Viena caurulīšu priekšrocība Linux un UNIX sistēmās ir tāda, ka ar to nav saistīts starpposma fails caurule - pirmās komandas stdout netiek ierakstīts failā un pēc tam tiek nolasīts otrajā komandu.
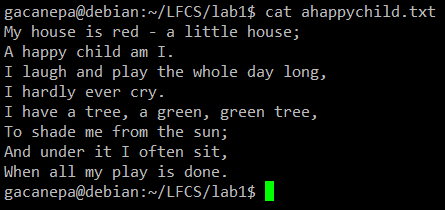
Turpmākajos vingrinājumos mēs izmantosim dzejoli “Laimīgs bērns”(Anonīms autors).
Vārds sed ir saīsinājums no straumes redaktora. Tiem, kas nav pazīstami ar šo terminu, plūsmas redaktoru izmanto, lai ievades straumē (failā vai ievadē no cauruļvada) veiktu pamata teksta pārveidošanu.
Visvienkāršākais (un populārākais) sed lietojums ir rakstzīmju aizstāšana. Mēs sāksim, mainot katru mazo burtu gadījumu g uz lielo burtu Y un novirzīt izvadi uz ahappychild2.txt. g karodziņš norāda, ka sed vajadzētu aizstāt visus termina gadījumus katrā faila rindā. Ja šis karogs tiek izlaists, sed aizstās tikai pirmo termina parādīšanos katrā rindā.
# sed 's/term/aizstāšana/karogs' fails.
# sed ‘s/y/Y/g’ ahappychild.txt> ahappychild2.txt.

Ja vēlaties meklēt vai aizstāt īpašu rakstzīmi (piemēram, /, \, &) jums ir jābēg terminā vai aizvietošanas virknēs ar slīpsvītru.
Piemēram, mēs aizstāsim vārdu un ar zīmi. Tajā pašā laikā mēs aizstāsim vārdu Es ar Jūs kad pirmais tiek atrasts rindas sākumā.
# sed 's/un/\ &/g; s/^Es/Tu/g 'ahappychild.txt.
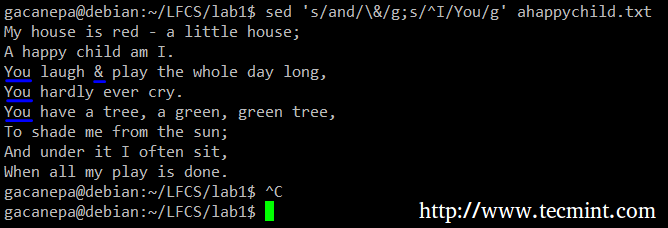
Iepriekš minētajā komandā a ^ (caret zīme) ir plaši pazīstama regulāra izteiksme, ko izmanto, lai attēlotu rindas sākumu.
Kā redzat, mēs varam apvienot divas vai vairākas aizstāšanas komandas (un tajās izmantot regulāras izteiksmes), atdalot tās ar semikolu un iekļaujot kopu atsevišķos pēdiņās.
Vēl viens sed lietojums ir izvēlētās faila daļas rādīšana (vai dzēšana). Nākamajā piemērā mēs parādīsim pirmās 5 rindas /var/log/messages no 8. jūnija.
# sed -n '/^8. jūnijs/p'/var/log/messages | sed -n 1,5p.
Ņemiet vērā, ka pēc noklusējuma sed izdrukā katru rindu. Mēs varam ignorēt šo uzvedību ar -n opciju un tad sakiet sed drukāt (apzīmēts ar lpp) tikai tā faila daļa (vai caurule), kas atbilst paraugam (8. jūnijs rindas sākumā pirmajā gadījumā un 1. līdz 5. rindiņa ieskaitot otrajā gadījumā).
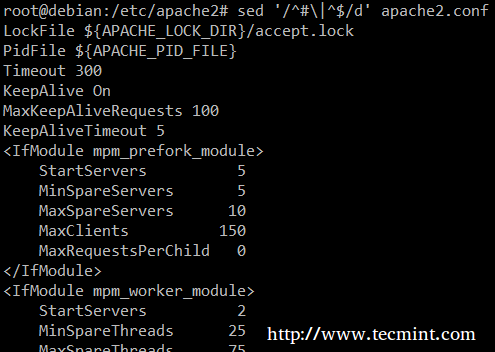
Visbeidzot, skriptu vai konfigurācijas failu pārbaudes laikā var būt noderīgi pārbaudīt pašu kodu un atstāt komentārus. Tiek dzēsti šādi vienas rindas laineri (d) tukšas rindas vai tās, kas sākas ar # ( | rakstzīme norāda Būla VAI starp divām regulārajām izteiksmēm).
# sed '/^# \ |^$/d' apache2.conf.
unikāls komanda ļauj mums ziņot vai noņemt dublētas rindas failā, pēc noklusējuma rakstot uz stdout. Mums tas jāatzīmē unikāls neatklāj atkārtotas līnijas, ja vien tās nav blakus. Tādējādi, unikāls parasti tiek lietots kopā ar iepriekšējo kārtot (ko izmanto, lai kārtotu teksta failu rindas). Pēc noklusējuma, kārtot ņem pirmo lauku (atdalīts ar atstarpēm) kā galveno lauku. Lai norādītu citu atslēgas lauku, mums jāizmanto -k iespēja.
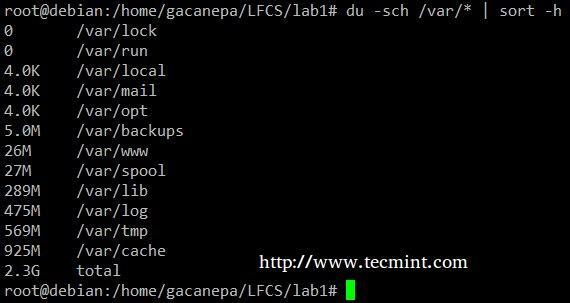
du –sch/path/to/directory/* komanda atgriež diska vietas izmantošanu katrai apakšdirektorijai un failiem norādītajā direktorijā cilvēkam lasāmā veidā formātā (parāda arī katras direktorijas kopsummu) un izvadi nesakārto pēc lieluma, bet pēc apakšdirektorija un faila nosaukuma. Mēs varam izmantot šo komandu, lai kārtotu pēc lieluma.
# du -sch /var /* | kārtot - h.
Jūs varat saskaitīt notikumu skaitu žurnālā pēc datuma, sakot unikāls lai veiktu salīdzināšanu, izmantojot katras rindas (kur ir norādīts datums) pirmās 6 rakstzīmes (-w 6) un katras izvades rindas prefiksu nosaka pēc notikumu skaita (-c) ar šādu komandu.
# kaķis /var/log/mail.log | uniq -c -w 6.

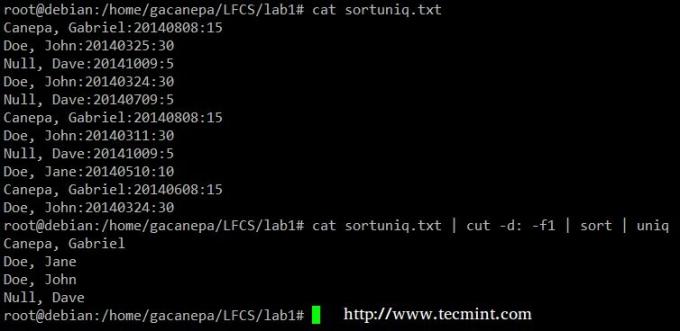
Visbeidzot, jūs varat apvienot kārtot un unikāls (kā parasti). Apsveriet šo failu ar ziedotāju sarakstu, ziedošanas datumu un summu. Pieņemsim, ka mēs vēlamies zināt, cik daudz ir unikālu donoru. Mēs izmantosim šādu komandu, lai izgrieztu pirmo lauku (lauki ir norobežoti ar kolu), kārtotu pēc nosaukuma un noņemtu atkārtotas rindas.
# kaķis sortuniq.txt | griezums -d: -f1 | kārtot | unikāls
Lasīt arī: 13 komandu “kaķis” piemēri
grep meklē teksta failus vai (komandu izvadi), vai notiek noteikta regulāra izteiksme, un izvada jebkuru rindu, kas satur atbilstību standarta izvadam.
Parādiet informāciju no /etc/passwd lietotājam gacanepa, ignorējot gadījumus.
# grep -i gacanepa /etc /passwd.

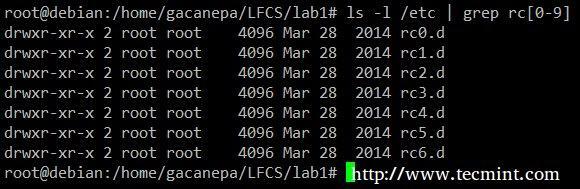
Rādīt visu saturu /etc kura vārds sākas ar rc kam seko jebkurš atsevišķs numurs.
# ls -l /utt | grep rc [0-9]
Lasīt arī: 12 komandu “grep” piemēri
tr komandu var izmantot, lai tulkotu (mainītu) vai dzēstu rakstzīmes no stdin un ierakstītu rezultātu stdout.
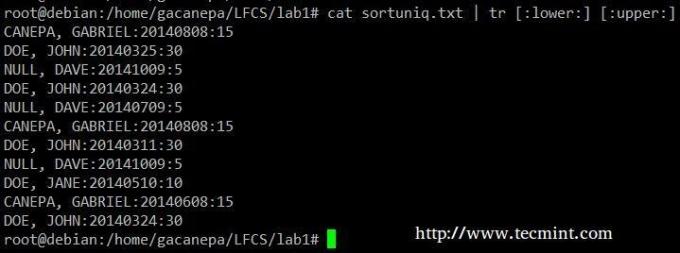
Mainiet visus mazos burtus uz lielajiem burtiem failā sortuniq.txt.
# kaķis sortuniq.txt | tr [: apakšējā:] [: augšējā:]
Saspiediet norobežotāju izejā ls – l tikai vienā telpā.
# ls -l | tr -s "
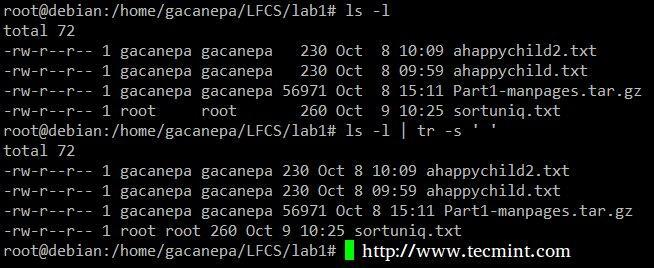
griezt komanda izvelk ievades rindu daļas (no stdin vai failiem) un parāda rezultātu standarta izvadē, pamatojoties uz baitu skaitu (-b opcija), rakstzīmes (-c) vai laukus (-f). Pēdējā gadījumā (pamatojoties uz laukiem) noklusējuma lauku atdalītājs ir cilne, bet citu norobežotāju var norādīt, izmantojot -d iespēja.
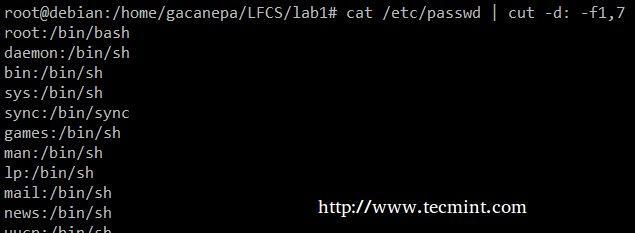
Izvelciet lietotāju kontus un tiem piešķirtos noklusējuma apvalkus /etc/passwd ( –D opcija ļauj norādīt lauka norobežotāju un - f slēdzis norāda, kurš (-i) lauks (-i) tiks iegūts.
# kaķis /etc /passwd | griezums -d: -f1,7.
Apkopojot, mēs izveidosim teksta plūsmu, kas sastāv no pirmā un trešā faila, kas nav tukšs Pēdējais komandu. Mēs izmantosim grep kā pirmais filtrs, lai pārbaudītu lietotāja sesijas gacanepa, pēc tam saspiediet norobežotājus tikai vienā atstarpē (tr -s ‘ ‘). Tālāk mēs iegūsim pirmo un trešo lauku ar griezt, un visbeidzot kārtojiet pēc otrā lauka (šajā gadījumā IP adreses), parādot unikālu.
# pēdējā | grep gacanepa | tr -s '' | sagriezts -d '' -f1,3 | kārtot -k2 | unikāls
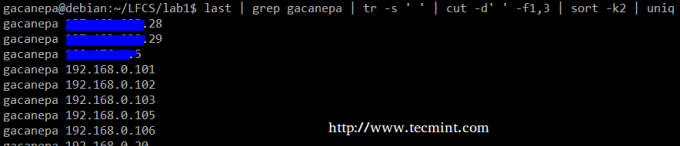
Iepriekš minētā komanda parāda, kā var apvienot vairākas komandas un caurules, lai iegūtu filtrētus datus atbilstoši mūsu vēlmēm. Jūtieties brīvi arī palaist to pa daļām, lai palīdzētu jums redzēt rezultātu, kas tiek pārsūtīts no vienas komandas uz otru (starp citu, tā var būt lieliska mācīšanās pieredze!).
Lai gan šis piemērs (kopā ar pārējiem piemēriem pašreizējā apmācībā) no pirmā acu uzmetiena nešķiet ļoti noderīgs, tie ir jauks sākumpunkts, lai sāktu eksperimentēt ar komandām, kuras tiek izmantotas, lai izveidotu, rediģētu un manipulētu ar failiem no Linux komandas līnija. Jūtieties brīvi atstāt savus jautājumus un komentārus zemāk - tie būs ļoti pateicīgi!