Iepriekšējos rakstos par šo RAID sērija jūs no nulles kļuvāt par RAID varoni. Mēs pārskatījām vairākas programmatūras RAID konfigurācijas un izskaidrojām katras būtiskās lietas, kā arī iemeslus, kādēļ atkarībā no konkrētā scenārija jūs noliektos uz vienu vai otru.

Šajā rokasgrāmatā mēs apspriedīsim, kā atjaunot programmatūras RAID masīvu, nezaudējot datus diska atteices gadījumā. Īsuma labad mēs ņemsim vērā tikai a RAID 1 iestatīšana, taču jēdzieni un komandas attiecas uz visiem gadījumiem.
Pirms turpināt, lūdzu, pārliecinieties, vai esat iestatījis a RAID 1 masīvs, ievērojot šīs sērijas 3. daļā sniegtos norādījumus: Kā iestatīt RAID 1 (spogulis) operētājsistēmā Linux.
Vienīgās variācijas šajā gadījumā būs šādas:
1) cita CentOS versija (v7) nekā tajā, kas izmantota šajā rakstā (v6.5), un
2) dažādiem diska izmēriem /dev/sdb un /dev/sdc (Katrs 8 GB).
Turklāt, ja SELinux ir iespējots izpildes režīmā, jums būs jāpievieno atbilstošās etiķetes direktorijai, kurā tiks uzstādīta RAID ierīce. Pretējā gadījumā jūs mēģināsit uzstādīt šo brīdinājuma ziņojumu:
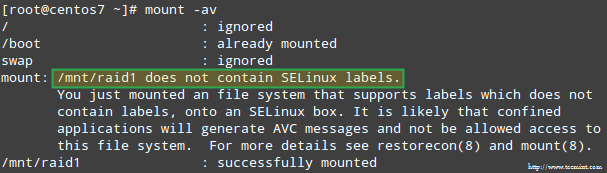
To var labot, palaižot:
# restorecon -R /mnt /raid1.
Ir vairāki iemesli, kāpēc atmiņas ierīce var neizdoties (SSD tomēr ir ievērojami samazinājuši tā izredzes), taču neatkarīgi no iemesla jūs varat būt pārliecināti, ka problēmas var rasties jebkurā laikā, un jums jābūt gatavam nomainīt neveiksmīgo daļu un nodrošināt savas ierīces pieejamību un integritāti dati.
Vispirms padoms. Pat tad, kad jūs varat pārbaudīt /proc/mdstat lai pārbaudītu RAID statusu, ir labāka un laiku taupošāka metode, kas sastāv no palaišanas mdadm monitora + skenēšanas režīmā, kas nosūtīs brīdinājumus pa e -pastu iepriekš definētam adresātam.
Lai to iestatītu, pievienojiet šādu rindu /etc/mdadm.conf:
MAILADDR [e -pasts aizsargāts]
Manā gadījumā:
MAILADDR [e -pasts aizsargāts]

Skriet mdadm monitora + skenēšanas režīmā pievienojiet šādu crontab ierakstu kā sakni:
@reboot /sbin /mdadm --monitor --scan --oneshot.
Pēc noklusējuma, mdadm pārbaudīs RAID masīvus ik pēc 60 sekundēm un nosūtīs brīdinājumu, ja konstatēs problēmu. Šo uzvedību var mainīt, pievienojot -kavēšanās opciju crontab ierakstam kopā ar sekunžu skaitu (piemēram, -kavēšanās 1800 nozīmē 30 minūtes).
Visbeidzot, pārliecinieties, vai jums ir a Pasta lietotāja aģents (MUA), piemēram, mutt vai mailx. Pretējā gadījumā jūs nesaņemsit brīdinājumus.
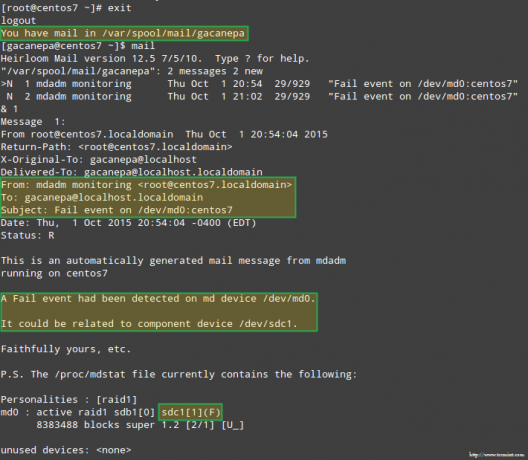
Pēc minūtes mēs redzēsim, kāds brīdinājums tika nosūtīts mdadm izskatās kā.
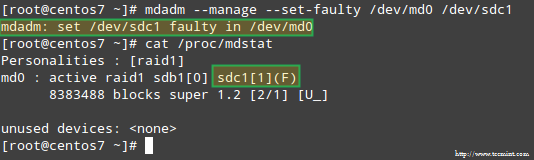
Lai modelētu problēmu ar kādu no RAID masīva atmiņas ierīcēm, mēs izmantosim -vadība un -komplekts kļūdains iespējas šādi:
# mdadm --manage-set-faulty /dev /md0 /dev /sdc1
Tā rezultātā /dev/sdc1 tiek atzīmēts kā kļūdains, kā redzams /proc/mdstat:
Vēl svarīgāk ir redzēt, vai esam saņēmuši e -pasta brīdinājumu ar tādu pašu brīdinājumu:
Šajā gadījumā jums būs jānoņem ierīce no programmatūras RAID masīva:
# mdadm /dev /md0 -noņemt /dev /sdc1.
Tad jūs varat to fiziski noņemt no iekārtas un aizstāt ar rezerves daļu (/dev/sdd, kur tipa nodalījums fd ir izveidots iepriekš):
# mdadm --manage /dev /md0 --add /dev /sdd1.
Par laimi, sistēma automātiski sāks masīva atjaunošanu ar daļu, kuru tikko pievienojām. Mēs to varam pārbaudīt, atzīmējot /dev/sdb1 kā kļūdainu, noņemot to no masīva un pārliecinoties, ka fails tecmint.txt joprojām ir pieejams vietnē /mnt/raid1:
# mdadm --detail /dev /md0. # stiprinājums | grep reids1. # ls -l /mnt /raid1 | grep tecmint. # kaķis /mnt/raid1/tecmint.txt.
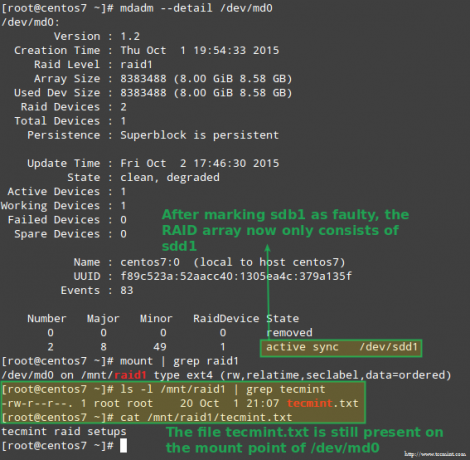
Iepriekš redzamais attēls to skaidri parāda pēc pievienošanas /dev/sdd1 masīvam kā aizstājēju /dev/sdc1, datu pārbūvi sistēma automātiski veica bez mūsu iejaukšanās.
Lai gan tas nav stingri nepieciešams, tā ir lieliska ideja, ja pa rokai ir rezerves ierīce, lai kļūdainas ierīces nomaiņu pret labu disku varētu veikt uzreiz. Lai to izdarītu, pievienosim vēlreiz /dev/sdb1 un /dev/sdc1:
# mdadm --manage /dev /md0 --add /dev /sdb1. # mdadm --manage /dev /md0 --add /dev /sdc1.
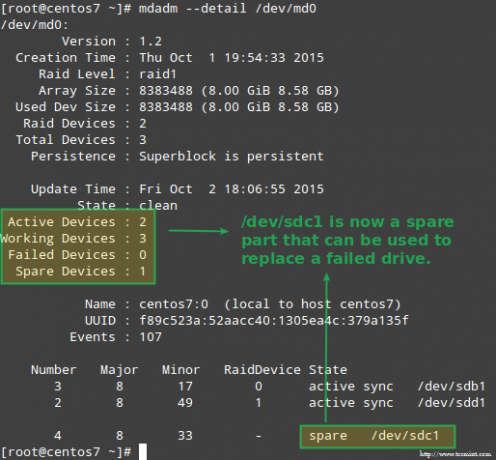
Kā paskaidrots iepriekš, mdadm automātiski atjaunos datus, ja viens disks neizdosies. Bet kas notiek, ja 2 diski masīvā neizdodas? Simulēsim šādu scenāriju, atzīmējot /dev/sdb1 un /dev/sdd1 kā kļūdains:
# umount /mnt /raid1. # mdadm --manage-set-faulty /dev /md0 /dev /sdb1. # mdadm -apstāties /dev /md0. # mdadm --manage-set-faulty /dev /md0 /dev /sdd1.
Mēģinājumi atkārtoti izveidot masīvu tādā pašā veidā, kādā tas tika izveidots šajā laikā (vai izmantojot -pieņemami tīrs iespēja) var izraisīt datu zudumu, tāpēc to vajadzētu atstāt kā pēdējo līdzekli.
Mēģināsim atgūt datus no /dev/sdb1piemēram, līdzīgā diska nodalījumā (/dev/sde1 - ņemiet vērā, ka tam ir jāizveido tipa nodalījums fd iekšā /dev/sde pirms turpināt), izmantojot ddrescue:
# ddrescue -r 2 /dev /sdb1 /dev /sde1.
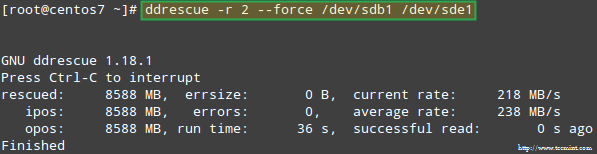
Lūdzu, ņemiet vērā, ka līdz šim brīdim mēs neesam pieskārušies /dev/sdb vai /dev/sdd, nodalījumi, kas bija daļa no RAID masīva.
Tagad atjaunosim masīvu, izmantojot /dev/sde1 un /dev/sdf1:
# mdadm --izveidot /dev /md0 --līmenis = spogulis --raid-ierīces = 2 /dev /sd [e-f] 1.
Lūdzu, ņemiet vērā, ka reālā situācijā parasti izmantosit tos pašus ierīču nosaukumus kā sākotnējā masīvā, tas ir, /dev/sdb1 un /dev/sdc1 pēc neveiksmīgo disku aizstāšanas ar jauniem.
Šajā rakstā esmu izvēlējies izmantot papildu ierīces, lai atkārtoti izveidotu masīvu ar pavisam jauniem diskiem un izvairītos no sajaukšanas ar sākotnējiem bojātajiem diskdziņiem.
Kad tiek jautāts, vai turpināt rakstīt masīvu, ierakstiet Y un nospiediet Ievadiet. Masīvs ir jāsāk, un jums vajadzētu būt iespējai skatīties tā progresu, izmantojot:
# skatīties -n 1 kaķis /proc /mdstat.
Kad process ir pabeigts, jums vajadzētu būt iespējai piekļūt sava RAID saturam:
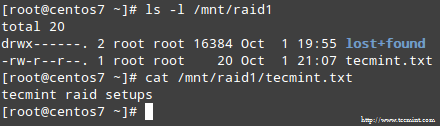
Šajā rakstā mēs esam apskatījuši, kā atgūties no RAID neveiksmes un atlaišanas zaudējumi. Tomēr jums jāatceras, ka šī tehnoloģija ir uzglabāšanas risinājums un NAV aizstāt dublējumkopijas.
Šajā rokasgrāmatā izskaidrotie principi attiecas uz visiem RAID iestatījumiem, kā arī uz jēdzieniem, kurus mēs apskatīsim nākamajā un pēdējā šīs sērijas rokasgrāmatā (RAID pārvaldība).
Ja jums ir kādi jautājumi par šo rakstu, lūdzu, atstājiet mums piezīmi, izmantojot zemāk esošo komentāru veidlapu. Mēs ceram uz jūsu ziņu!
