
아파치 스파크 더 빠른 계산 결과를 제공하기 위해 만들어진 오픈 소스 분산 계산 프레임워크입니다. 메모리 내 계산 엔진으로 데이터가 메모리에서 처리됩니다.
불꽃 스트리밍, 그래프 처리, SQL, MLLib 등 다양한 API를 지원합니다. 또한 Java, Python, Scala 및 R을 기본 언어로 지원합니다. Spark는 주로 다음 위치에 설치됩니다. 하둡 클러스터 그러나 독립 실행형 모드에서 spark를 설치하고 구성할 수도 있습니다.
이 기사에서는 설치 방법을 볼 것입니다. 아파치 스파크 입력 데비안 그리고 우분투기반 배포.
설치하기 위해서 아파치 스파크 우분투에서는 다음이 필요합니다. 자바 그리고 스칼라 컴퓨터에 설치됩니다. 대부분의 최신 배포판에는 기본적으로 Java가 설치되어 있으며 다음 명령을 사용하여 확인할 수 있습니다.
$ 자바 -버전.

출력이 없으면 다음 기사를 사용하여 Java를 설치할 수 있습니다. Ubuntu에 Java를 설치하는 방법 또는 단순히 다음 명령을 실행하여 Ubuntu 및 Debian 기반 배포에 Java를 설치합니다.
$ sudo apt 업데이트. $ sudo apt install default-jre. $ 자바 -버전.

다음으로 설치할 수 있습니다. 스칼라 다음 명령을 실행하여 apt 저장소에서 scala를 검색하고 설치합니다.
$ sudo apt search scala ⇒ 패키지를 검색합니다. $ sudo apt install scala ⇒ 패키지를 설치합니다.
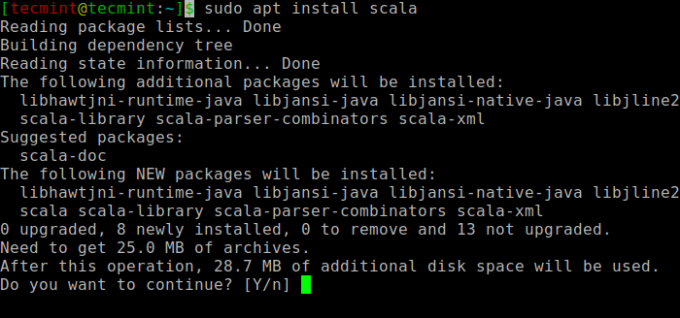
의 설치를 확인하려면 스칼라, 다음 명령을 실행합니다.
$ 스칼라 버전 Scala 코드 러너 버전 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
이제 공식으로 이동 Apache Spark 다운로드 페이지 이 기사를 작성하는 시점에 최신 버전(즉, 3.1.1)을 가져옵니다. 또는 다음을 사용할 수 있습니다. wget 명령 터미널에서 직접 파일을 다운로드합니다.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz.
이제 터미널을 열고 다운로드한 파일이 있는 위치로 전환하고 다음 명령을 실행하여 Apache Spark tar 파일의 압축을 풉니다.
$ tar -xvzf spark-3.1.1-bin-hadoop2.7.tgz.
마지막으로 추출한 것을 이동합니다. 불꽃 디렉토리 /opt 예배 규칙서.
$ sudo mv spark-3.1.1-bin-hadoop2.7 /opt/spark.
이제 몇 가지 환경 변수를 설정해야 합니다. .프로필 스파크를 시작하기 전에 파일.
$ echo "내보내기 SPARK_HOME=/opt/spark" >> ~/.profile. $ echo "내보내기 PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile. $ echo "PYSPARK_PYTHON=/usr/bin/python3 내보내기" >> ~/.profile.
이러한 새로운 환경 변수가 셸 내에서 접근 가능하고 Apache Spark에서 사용 가능한지 확인하려면 다음 명령을 실행하여 최근 변경 사항을 적용해야 합니다.
$ 소스 ~/.프로필.
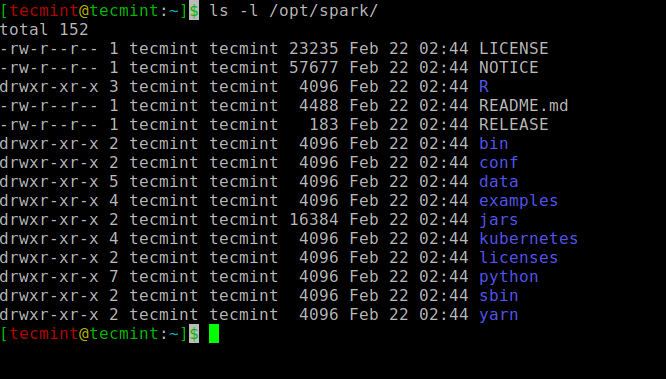
서비스를 시작하고 중지하는 모든 스파크 관련 바이너리는 sbin 폴더.
$ ls -l /opt/spark.
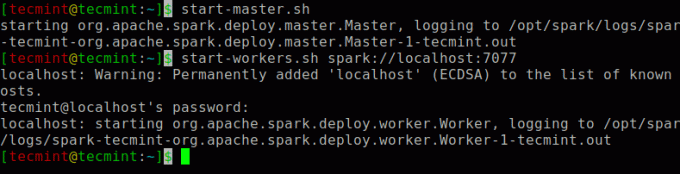
다음 명령을 실행하여 불꽃 마스터 서비스와 슬레이브 서비스.
$ start-master.sh. $ start-workers.sh spark://localhost: 7077.
서비스가 시작되면 브라우저로 이동하여 다음 URL 액세스 스파크 페이지를 입력합니다. 페이지에서 내 마스터 및 슬레이브 서비스가 시작된 것을 볼 수 있습니다.
http://localhost: 8080/ 또는. http://127.0.0.1:8080.

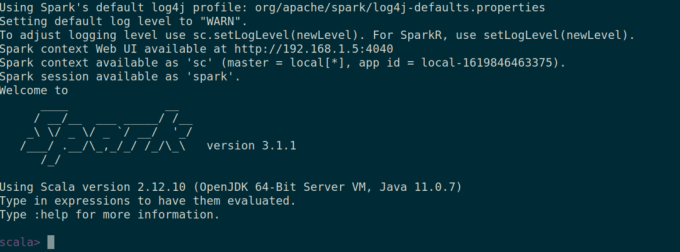
여부도 확인할 수 있습니다. 불꽃 껍질 시작하여 잘 작동합니다. 불꽃 껍질 명령.
$ 스파크 쉘.
그것이 이 글의 내용입니다. 곧 또 다른 흥미로운 기사로 찾아 뵙겠습니다.