
במאמרים הקודמים של זה סדרת RAID עברת מאפס לגיבור RAID. סקרנו מספר תצורות RAID של תוכנות והסברנו את המהותיות של כל אחת מהן, יחד עם הסיבות מדוע היית נוטה לכיוון זה או אחר בהתאם לתרחיש הספציפי שלך.

במדריך זה נדון כיצד לבנות מחדש מערך RAID תוכנה ללא אובדן נתונים במקרה של תקלה בדיסק. בקיצור, נשקול רק א RAID 1 setup - אך המושגים והפקודות חלים על כל המקרים כאחד.
לפני שתמשיך הלאה, ודא שהגדרת א RAID 1 מערך בהתאם להוראות המפורטות בחלק 3 בסדרה זו: כיצד להגדיר RAID 1 (Mirror) בלינוקס.
הווריאציות היחידות במקרה הנוכחי שלנו יהיו:
1) גירסה שונה של CentOS (v7) מזו ששימשה אותו מאמר (v6.5), ו-
2) גדלי דיסק שונים עבור /dev/sdb ו /dev/sdc (8 GB כל אחד).
בנוסף, אם SELinux מופעל במצב אכיפה, יהיה עליך להוסיף את התוויות המתאימות לספרייה שבה תטען את התקן RAID. אחרת, תיתקל בהודעת אזהרה זו בעת ניסיון להעלות אותה:
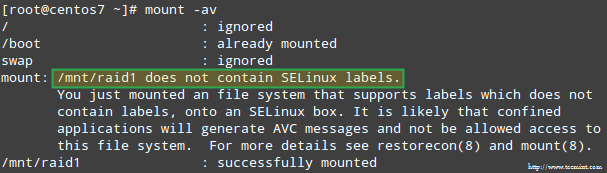
אתה יכול לתקן זאת על ידי הפעלה:
# שחזור -R /mnt /raid1.
ישנן מגוון סיבות לכך שמכשיר אחסון עלול להיכשל (כונני SSD הפחיתו מאוד את הסיכויים שזה יקרה), אך ללא קשר לסיבה אתה יכול להיות בטוח כי בעיות יכולות להתרחש בכל עת ואתה צריך להיות מוכן להחליף את החלק הכושל ולהבטיח את הזמינות והתקינות של נתונים.
מילה אחת לייעוץ קודם כל. גם כשאתה יכול לבדוק /proc/mdstat על מנת לבדוק את הסטטוס של RAIDs שלך, יש שיטה טובה וחוסכת זמן שמורכבת מריצה mdadm במצב צג + סריקה, אשר ישלח התראות באמצעות דואר אלקטרוני לנמען מוגדר מראש.
כדי להגדיר זאת, הוסף את השורה הבאה /etc/mdadm.conf:
MAILADDR [מוגן בדוא"ל]
במקרה שלי:
MAILADDR [מוגן בדוא"ל]

לרוץ mdadm במצב צג + סריקה, הוסף את ערך crontab הבא כשורש:
@reboot /sbin /mdadm --monitor --scan --oneshot.
כברירת מחדל, mdadm יבדוק את מערכי RAID כל 60 שניות וישלח התראה אם תמצא בעיה. אתה יכול לשנות התנהגות זו על ידי הוספת ה- --לְעַכֵּב אפשרות לערך crontab למעלה יחד עם כמות השניות (לדוגמה, --לְעַכֵּב 1800 פירושו 30 דקות).
לבסוף, ודא שיש לך סוכן משתמש בדואר (MUA) מותקן, כגון mutt או mailx. אחרת, לא תקבל התראות.
תוך דקה נראה איזו התראה נשלחה mdadm נראה כמו.
כדי לדמות בעיה באחד ממכשירי האחסון במערך RAID, נשתמש ב- --לנהל ו -סט-פגום אפשרויות כדלקמן:
# mdadm-ניהול-set-default /dev /md0 /dev /sdc1
זה יביא /dev/sdc1 מסומן כפגום, כפי שאנו יכולים לראות /proc/mdstat:
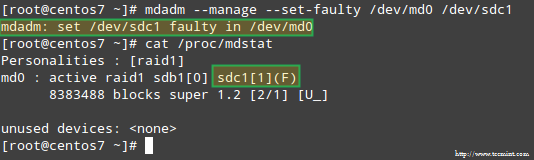
חשוב מכך, בואו לראות אם קיבלנו התראה בדוא"ל עם אותה אזהרה:
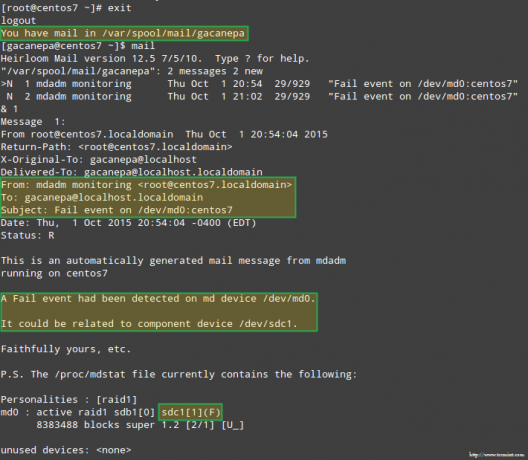
במקרה זה, יהיה עליך להסיר את המכשיר ממערך RAID של התוכנה:
# mdadm /dev /md0 -להסיר /dev /sdc1.
לאחר מכן תוכל להסיר אותו פיזית מהמכונה ולהחליף אותו בחלק חלקי (/dev/sdd, שבו מחיצה מסוג fd נוצר בעבר):
# mdadm --manage /dev /md0 --add /dev /sdd1.
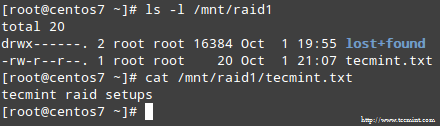
למזלנו, המערכת תתחיל לבנות מחדש את המערך באופן אוטומטי עם החלק שהוספנו זה עתה. אנו יכולים לבדוק זאת על ידי סימון /dev/sdb1 כפגום, הסרתו מהמערך וודא כי הקובץ tecmint.txt עדיין נגיש ב /mnt/raid1:
# mdadm --detail /dev /md0. # הר | grep raid 1. # ls -l /mnt /raid1 | grep tecmint. # cat /mnt/raid1/tecmint.txt.
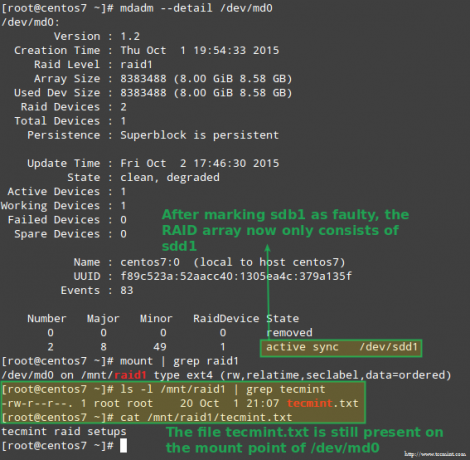
התמונה למעלה מראה בבירור זאת לאחר הוספה /dev/sdd1 למערך כתחליף ל- /dev/sdc1, בניית הנתונים מחדש בוצעה אוטומטית על ידי המערכת ללא התערבות מצידנו.
למרות שזה לא נדרש בהחלט, כדאי להחזיק מכשיר חילוף בהישג יד כך שניתן יהיה לבצע את תהליך החלפת המכשיר הפגום בכונן טוב במהירות. לשם כך, הוסף שוב /dev/sdb1 ו /dev/sdc1:
# mdadm --manage /dev /md0 --add /dev /sdb1. # mdadm --manage /dev /md0 --add /dev /sdc1.
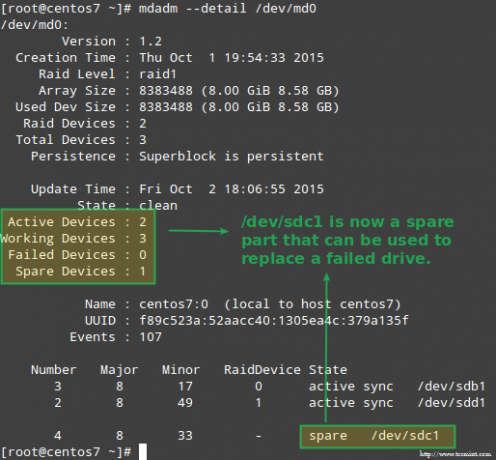
כפי שהוסבר קודם לכן, mdadm יבנה מחדש את הנתונים באופן אוטומטי כאשר דיסק אחד נכשל. אבל מה קורה אם 2 דיסקים במערך נכשלים? בואו לדמות תרחיש כזה על ידי סימון /dev/sdb1 ו /dev/sdd1 כפגום:
# umount /mnt /raid1. # mdadm-ניהול-set-default /dev /md0 /dev /sdb1. # mdadm -stop /dev /md0. # mdadm-ניהול-set-defekt /dev /md0 /dev /sdd1.
ניסיונות ליצור מחדש את המערך באותו אופן בו הוא נוצר בשלב זה (או באמצעות -נקי-כביסה option) עלול לגרום לאובדן נתונים, ולכן יש להשאיר זאת כמוצא אחרון.
ננסה לשחזר את הנתונים מ- /dev/sdb1, למשל, למחיצת דיסק דומה (/dev/sde1 - שים לב שזה דורש שתיצור מחיצה מסוג fd ב /dev/sde לפני שתמשיך) באמצעות ddrescue:
# ddrescue -r 2 /dev /sdb1 /dev /sde1.
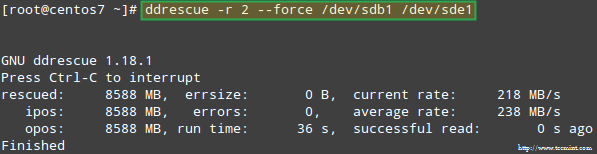
שים לב שעד לנקודה זו, לא נגענו /dev/sdb אוֹ /dev/sdd, המחיצות שהיו חלק ממערך ה- RAID.
כעת בואו נבנה מחדש את המערך באמצעות /dev/sde1 ו /dev/sdf1:
# mdadm --create /dev /md0 --level = mirror --raid-devices = 2 /dev /sd [e-f] 1.
שים לב שבמצב אמיתי, בדרך כלל תשתמש באותם שמות מכשירים כמו במערך המקורי, כלומר, /dev/sdb1 ו /dev/sdc1 לאחר שהדיסקים שנכשלו הוחלפו בדיסקים חדשים.
במאמר זה בחרתי להשתמש בהתקנים נוספים ליצירת המערך מחדש עם דיסקים חדשים ולמנוע בלבול עם הכוננים המקוריים שנכשלו.
כשנשאל אם להמשיך לכתוב מערך, הקלד י ולחץ להיכנס. יש להפעיל את המערך וכדי שתוכל לצפות בהתקדמותו באמצעות:
# watch -n 1 cat /proc /mdstat.
עם סיום התהליך, אתה אמור להיות מסוגל לגשת לתוכן ה- RAID שלך:
במאמר זה סקרנו כיצד להתאושש לִפְשׁוֹט כישלונות ואובדן יתירות. עם זאת, עליך לזכור כי טכנולוגיה זו היא פתרון אחסון ו לא להחליף גיבויים.
העקרונות המוסברים במדריך זה חלים על כל הגדרות RAID כאחד, כמו גם על המושגים עליהם נעסוק במדריך הבא והאחרון של סדרה זו (ניהול RAID).
אם יש לך שאלות בנוגע למאמר זה, אל תהסס לשלוח לנו הערה באמצעות טופס ההערה למטה. אנו מצפים לשמוע ממך!

