Di recente, la Linux Foundation ha lanciato il LFCS (Amministratore di sistema certificato Linux Foundation), una brillante possibilità per gli amministratori di sistema di tutto il mondo di dimostrare, attraverso un esame basato sulle prestazioni, di essere in grado di svolgere supporto operativo generale sui sistemi Linux: supporto di sistema, diagnosi e monitoraggio di primo livello, oltre a escalation dei problemi, quando richiesto, ad altro supporto squadre.

Il seguente video fornisce un'introduzione al programma di certificazione The Linux Foundation.
Questo post è la parte 6 di una serie di 10 tutorial, qui in questa parte spiegheremo come assemblare Partizioni come dispositivi RAID: creazione e gestione dei backup di sistema, necessari per LFCS esame di certificazione.
La tecnologia nota come Array ridondante di dischi indipendenti (RAID) è una soluzione di archiviazione che combina più dischi rigidi in un'unica unità logica per fornire ridondanza dei dati e/o migliorare le prestazioni nelle operazioni di lettura/scrittura su disco.
Tuttavia, l'effettiva tolleranza agli errori e le prestazioni di I/O del disco dipendono dalla configurazione dei dischi rigidi per formare l'array di dischi. A seconda dei dispositivi disponibili e delle esigenze di tolleranza agli errori/prestazioni, vengono definiti diversi livelli RAID. È possibile fare riferimento alla serie RAID qui in Tecmint.com per una spiegazione più dettagliata su ciascun livello RAID.
Guida RAID: Che cos'è il RAID, spiegazione dei concetti di RAID e dei livelli RAID?
Il nostro strumento preferito per creare, assemblare, gestire e monitorare i nostri software RAID si chiama mdadm (abbreviazione di amministratore di più dischi).
Debian e derivati # aptitude update && aptitude install mdadm
Sistemi basati su Red Hat e CentOS # yum update && yum install mdadm.
Su openSUSE # zypper refresh && zypper install mdadm #
Il processo di assemblaggio delle partizioni esistenti come dispositivi RAID consiste nei seguenti passaggi.
Se una delle partizioni è stata formattata in precedenza o ha fatto parte di un altro array RAID in precedenza, verrà richiesto di confermare la creazione del nuovo array. Supponendo che tu abbia preso le precauzioni necessarie per evitare di perdere dati importanti che potrebbero aver risieduto in essi, puoi tranquillamente digitare sì e premi accedere.
# mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 /dev/sdb1 /dev/sdc1.

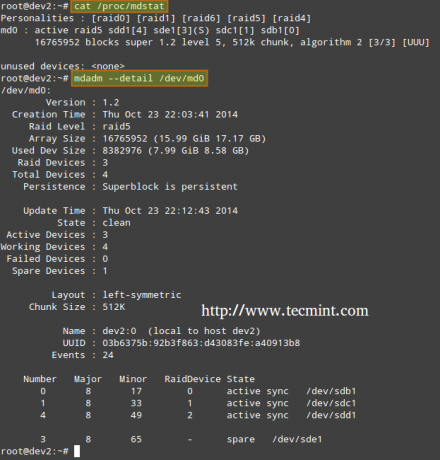
Per controllare lo stato di creazione dell'array, utilizzerai i seguenti comandi, indipendentemente dal tipo di RAID. Questi sono validi tanto quanto quando creiamo un RAID0 (come mostrato sopra), o quando stai configurando un RAID5, come mostrato nell'immagine qui sotto.
# cat /proc/mdstat. o # mdadm --detail /dev/md0 [Riepilogo più dettagliato]
Formatta il dispositivo con un filesystem secondo le tue esigenze / requisiti, come spiegato in Parte 4 di questa serie.
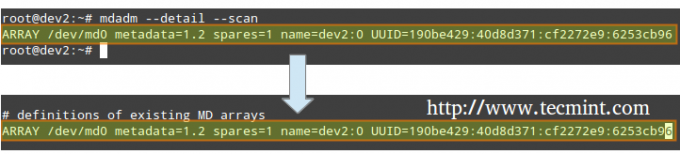
Indicare al servizio di monitoraggio di "tenere d'occhio" l'array. Aggiungi l'output di mdadm –detail –scan a /etc/mdadm/mdadm.conf (Debian e derivati) o /etc/mdadm.conf (CentOS / openSUSE), così.
# mdadm --detail --scan.
# mdadm --assemble --scan [Assembla l'array]
Per garantire che il servizio si avvii all'avvio del sistema, eseguire i seguenti comandi come root.
Debian e derivati, anche se dovrebbe iniziare a funzionare all'avvio per impostazione predefinita.
# default update-rc.d mdadm.
Modifica il /etc/default/mdadm file e aggiungere la seguente riga.
AUTOSTART=vero.
# systemctl avvia mdmonitor. # systemctl abilita mdmonitor.
# avvio di mdmonitor del servizio. # chkconfig mdmonitor acceso.
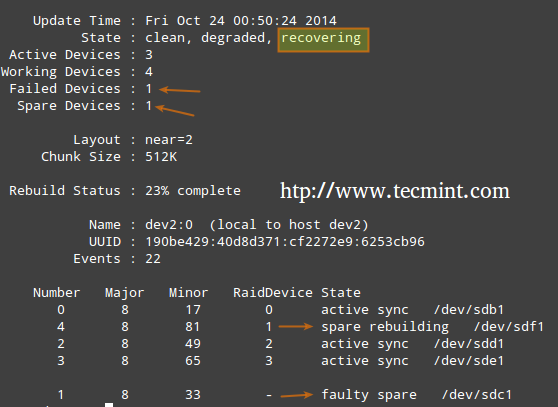
Nei livelli RAID che supportano la ridondanza, sostituire le unità guaste quando necessario. Quando un dispositivo nell'array di dischi si guasta, viene avviata automaticamente una ricostruzione solo se è stato aggiunto un dispositivo di riserva quando abbiamo creato l'array per la prima volta.
Altrimenti, dobbiamo collegare manualmente un'unità fisica extra al nostro sistema ed eseguire.
# mdadm /dev/md0 --add /dev/sdX1.
In cui si /dev/md0 è l'array che ha riscontrato il problema e /dev/sdX1 è il nuovo dispositivo.
Potrebbe essere necessario farlo se è necessario creare un nuovo array utilizzando i dispositivi – (Passaggio opzionale).
# mdadm --stop /dev/md0 # Arresta l'array. # mdadm --remove /dev/md0 # Rimuove il dispositivo RAID. # mdadm --zero-superblock /dev/sdX1 # Sovrascrive il superblocco md esistente con zeri.
Puoi configurare un indirizzo email valido o un account di sistema a cui inviare avvisi (assicurati di avere questa riga in mdadm.conf). – (Passaggio opzionale)
MAILADDR root.
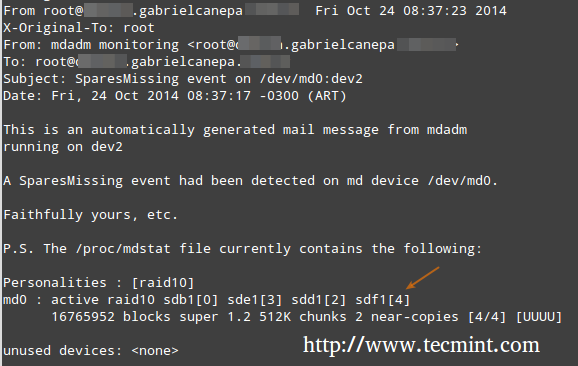
In questo caso, tutti gli avvisi raccolti dal demone di monitoraggio RAID verranno inviati alla casella di posta dell'account root locale. Uno di questi avvisi è simile al seguente.
Nota: Questo evento è correlato all'esempio in FASE 5, dove un dispositivo è stato contrassegnato come difettoso e il dispositivo di riserva è stato automaticamente integrato nell'array da mdadm. Così, noi"finito” di dispositivi di scorta sani e abbiamo ricevuto l'avviso.
La dimensione totale dell'array è n volte la dimensione della partizione più piccola, dove n è il numero di dischi indipendenti nell'array (sono necessarie almeno due unità). Esegui il seguente comando per assemblare a RAID 0 array usando le partizioni /dev/sdb1 e /dev/sdc1.
# mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=2 /dev/sdb1 /dev/sdc1.
Usi comuni: configurazioni che supportano applicazioni in tempo reale in cui le prestazioni sono più importanti della tolleranza agli errori.
La dimensione totale dell'array è uguale alla dimensione della partizione più piccola (sono necessarie almeno due unità). Esegui il seguente comando per assemblare a RAID 1 array usando le partizioni /dev/sdb1 e /dev/sdc1.
# mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdb1 /dev/sdc1.
Usi comuni: installazione del sistema operativo o di importanti sottodirectory, come /home.
La dimensione totale dell'array sarà (n – 1) volte la dimensione della partizione più piccola. Il "perso” spazio in (n-1) viene utilizzato per il calcolo della parità (ridondanza) (sono necessarie almeno tre unità).
Si noti che è possibile specificare un dispositivo di riserva (/dev/sde1 in questo caso) per sostituire una parte difettosa quando si verifica un problema. Esegui il seguente comando per assemblare a RAID 5 array usando le partizioni /dev/sdb1, /dev/sdc1, /dev/sdd1, e /dev/sde1 come ricambio.
# mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1 --spare-devices=1 /dev/sde1.
Usi comuni: Web e file server.
La dimensione totale dell'array sarà (n*s)-2*s, dove n è il numero di dischi indipendenti nell'array e S è la dimensione del disco più piccolo. Si noti che è possibile specificare un dispositivo di riserva (/dev/sdf1 in questo caso) per sostituire una parte difettosa quando si verifica un problema.
Esegui il seguente comando per assemblare a RAID 6 array usando le partizioni /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, e /dev/sdf1 come ricambio.
# mdadm --create --verbose /dev/md0 --level=6 --raid-devices=4 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde --spare-devices=1 /dev/ sdf1.
Usi comuni: File e server di backup con requisiti di grande capacità e alta disponibilità.
La dimensione totale dell'array viene calcolata in base alle formule per RAID 0 e RAID 1, da RAID 1+0 è una combinazione di entrambi. Per prima cosa, calcola la dimensione di ogni specchio e poi la dimensione della striscia.
Si noti che è possibile specificare un dispositivo di riserva (/dev/sdf1 in questo caso) per sostituire una parte difettosa quando si verifica un problema. Esegui il seguente comando per assemblare a RAID 1+0 array usando le partizioni /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, e /dev/sdf1 come ricambio.
# mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sd[b-e]1 --spare-devices=1 /dev/sdf1
Usi comuni: Database e server applicazioni che richiedono operazioni di I/O veloci.
Non fa mai male ricordare quel RAID con tutte le sue taglie NON È UN SOSTITUZIONE PER I BACKUP! Se necessario, scrivilo 1000 volte alla lavagna, ma assicurati di tenere sempre a mente quell'idea. Prima di iniziare, dobbiamo notare che non c'è taglia unica soluzione per i backup di sistema, ma qui ci sono alcune cose che è necessario tenere in considerazione durante la pianificazione di una strategia di backup.
Metodo 1: Backup di intere unità con dd comando. È possibile eseguire il backup di un intero disco rigido o di una partizione creando un'immagine esatta in qualsiasi momento. Tieni presente che funziona meglio quando il dispositivo è offline, il che significa che non è montato e non ci sono processi che vi accedono per operazioni di I/O.
Lo svantaggio di questo approccio di backup è che l'immagine avrà le stesse dimensioni del disco o della partizione, anche quando i dati effettivi ne occupano una piccola percentuale. Ad esempio, se si desidera creare l'immagine di una partizione di 20 GB che è solo 10% pieno, il file immagine sarà ancora 20 GB in misura. In altre parole, non vengono sottoposti a backup solo i dati effettivi, ma l'intera partizione stessa. Puoi prendere in considerazione l'utilizzo di questo metodo se hai bisogno di backup esatti dei tuoi dispositivi.
# dd if=/dev/sda of=/system_images/sda.img. O. In alternativa, puoi comprimere il file immagine # dd if=/dev/sda | gzip -c > /system_images/sda.img.gz
# dd if=/system_images/sda.img of=/dev/sda. OPPURE A seconda della scelta durante la creazione dell'immagine gzip -dc /system_images/sda.img.gz | dd di=/dev/sda
Metodo 2: Backup di determinati file / directory con catrame comando – già coperto in Parte 3 di questa serie. Puoi prendere in considerazione l'utilizzo di questo metodo se hai bisogno di conservare copie di file e directory specifici (file di configurazione, directory home degli utenti e così via).
Metodo 3: sincronizza i file con rsync comando. Rsync è un versatile strumento di copia di file remoto (e locale). Se hai bisogno di eseguire il backup e sincronizzare i tuoi file da/verso le unità di rete, rsync è una soluzione.
Sia che tu stia sincronizzando due directory locali o directory locali < — > remote montate sul filesystem locale, la sintassi di base è la stessa.
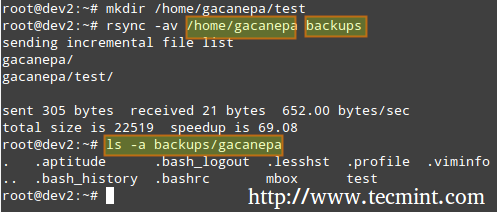
# rsync -av directory_origine directory di destinazione.
In cui si, -un ricorrono nelle sottodirectory (se esistono), conservano i collegamenti simbolici, i timestamp, i permessi e il proprietario/gruppo originale e -v verboso.
Inoltre, se desideri aumentare la sicurezza del trasferimento dei dati tramite filo, puoi utilizzare ssh terminato rsync.
# rsync -avzhe backup ssh [e-mail protetta]_host:/directory_remota/
Questo esempio sincronizzerà la directory dei backup sull'host locale con il contenuto di /root/remote_directory sull'host remoto.
Dove la -h l'opzione mostra le dimensioni dei file in un formato leggibile dall'uomo e l'opzione -e flag viene utilizzato per indicare una connessione ssh.
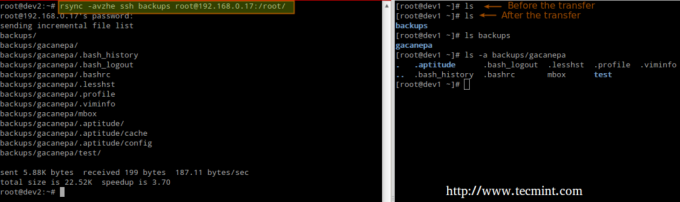
Sincronizzazione delle directory remote → locali su ssh.
In questo caso, scambiare le directory di origine e di destinazione dall'esempio precedente.
# rsync -avzhe ssh [e-mail protetta]_host:/directory_remota/ backup
Tieni presente che questi sono solo 3 esempi (casi più frequenti in cui potresti imbatterti) dell'uso di rsync. Per ulteriori esempi e utilizzi dei comandi rsync, consultare il seguente articolo.
Leggi anche: 10 comandi rsync per sincronizzare i file in Linux
In qualità di amministratore di sistema, devi assicurarti che i tuoi sistemi funzionino nel miglior modo possibile. Se sei ben preparato e se l'integrità dei tuoi dati è ben supportata da una tecnologia di archiviazione come RAID e backup regolari del sistema, sarai al sicuro.
Se hai domande, commenti o ulteriori idee su come migliorare questo articolo, sentiti libero di parlare qui sotto. Inoltre, considera di condividere questa serie attraverso i tuoi profili di social network.