Linux è un sistema operativo (OS) molto popolare tra i programmatori e gli utenti regolari. Uno dei motivi principali della sua popolarità è l'eccezionale supporto della riga di comando. Siamo in grado di gestire l'intero sistema operativo Linux solo tramite interfaccia a riga di comando (CLI). Questo ci consente di eseguire compiti complessi con pochi comandi.
In questa guida, discuteremo alcuni comandi di uso comune che sono utili per amministratori di sistema esperti o principianti. Dopo aver seguito questa guida, gli utenti saranno in grado di utilizzare con sicurezza il sistema Linux.
Per una migliore organizzazione, questi comandi sono raggruppati in tre sezioni: sistema di file, rete, E informazioni di sistema.
In questa sezione, discuteremo alcuni dei comandi utili relativi a file e directory in Linux.
IL comando gatto è utilizzato principalmente per visualizzare il contenuto del file. Legge il contenuto del file e lo visualizza sullo standard output (stdout).
La sintassi comune di gatto comando è:
$ cat [OPZIONI] [FILE1] [FILE2]...
Visualizziamo il contenuto del /etc/os-release file utilizzando il gatto comando:
$ cat /etc/os-release.

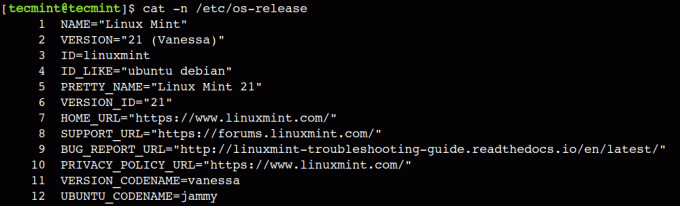
Inoltre, possiamo anche usare il -N opzione del comando per visualizzare il contenuto con il numero di riga:
$ cat -n /etc/os-release.
IL comando cp è utile per copiare file, gruppi di file e directory.
La sintassi comune di cp comando è:
$ cp [OPZIONI]
Qui, le parentesi quadre ([]) rappresentano gli argomenti facoltativi mentre le parentesi angolari (<>) rappresentano gli argomenti essenziali.
Copiamo il /etc/os-release file al /tmp rubrica:
$ cp /etc/os-release /tmp/nuovo-file.txt.
Ora, visualizziamo il contenuto del file per verificare che il file sia stato copiato:
$ cat /tmp/nuovo-file.txt.

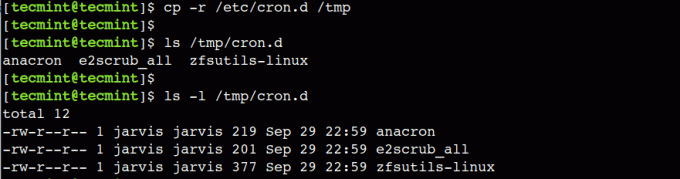
Allo stesso modo, possiamo copiare la directory usando il file cp comando. Copiamo il /etc/cron.d directory all'interno del /tmp rubrica:
$ cp -r /etc/cron.d /tmp.
Abbiamo usato il -R opzione con il comando cp, che rappresenta l'operazione ricorsiva. Copia la directory in modo ricorsivo che include i suoi file e sottodirectory.
Nel prossimo esempio vedremo come verificare che la directory sia stata copiata correttamente.
$ ls /tmp/cron.d. $ ls -l /tmp/cron.d.
IL comando ls viene utilizzato per elencare il contenuto della directory e ordinare i file in base alla dimensione e all'ora dell'ultima modifica in ordine decrescente.
La sintassi comune di ls comando è:
$ ls [OPZIONI] [FILE1] [FILE2]...
Se non forniamo alcun argomento al ls comando quindi elenca il contenuto della directory corrente.
$ l.

Nell'esempio precedente, abbiamo copiato il file /etc/cron.d directory al /tmp directory. Verifichiamo che sia presente e contenga i file richiesti:
$ ls /tmp/cron.d.
Possiamo usare il -l opzione con il ls comando per visualizzare informazioni più dettagliate come: autorizzazioni file, proprietario, timestamp, dimensioni, ecc.
Scopriamo maggiori dettagli sui file presenti nei file /tmp/cron.d rubrica:
$ ls -l /tmp/cron.d.

Spesso creiamo una struttura di directory per organizzare i contenuti. In Linux, possiamo usare il mkdir comando per creare una o più directory e impostare le autorizzazioni corrette per le directory.
La sintassi comune di mkdir comando è:
$ mkdir [OPZIONI]...
Creiamo una directory con il nome dir-1 nel /tmp rubrica:
$ mkdir /tmp/dir-1.
Ora, verifichiamo che la directory sia stata creata:
$ ls /tmp/dir-1.
Qui, possiamo vedere che il ls Il comando non riporta alcun errore, il che significa che la directory è presente lì.
A volte, abbiamo bisogno di creare una struttura di directory nidificata per una migliore organizzazione dei dati. In questi casi, possiamo usare il -P opzione del comando per creare alcune directory nidificate sotto il file /tmp/dir-1 rubrica:
$ mkdir -p /tmp/dir-1/dir-2/dir-3/dir-4/dir-5.
Nell'esempio precedente, abbiamo creato 4 livelli di directory nidificate. Confermiamolo usando il ls comando:
$ ls -R /tmp/dir-1.
Qui, abbiamo usato il -R opzione con il comando per visualizzare il contenuto della directory in modo ricorsivo.

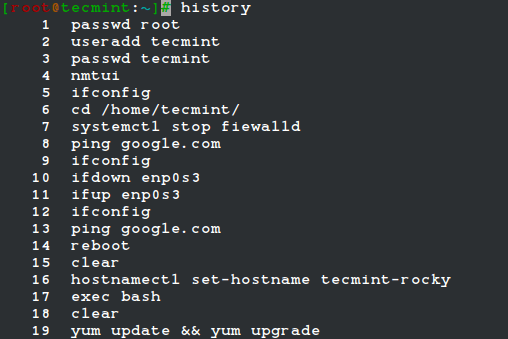
Per controllare gli ultimi comandi eseguiti, puoi usare il file comando storia, che visualizza l'elenco degli ultimi comandi eseguiti in una sessione di terminale.
$ storia.
Per visualizzare la cronologia dei comandi con un timestamp, è necessario impostare il timestamp nella cronologia di bash, eseguire:
$ HISTTIMEFORMAT="%d/%m/%y %T " #Imposta temporaneamente il timestamp della cronologia. $ export HISTTIMEFORMAT="%d/%m/%y %T " #Imposta in modo permanente il timestamp della cronologia. $ storia.

Come controllerai i primi 10 file che consumano spazio su disco? Un semplice script di una riga realizzato dal file du comando, utilizzato principalmente per l'utilizzo dello spazio file.
$ du -hsx * | ordina -rh | testa -10.

Spiegazione delle opzioni e delle opzioni del comando du sopra.
(-H) Formato leggibile dall'uomo, (-S) Sintesi Output, (-X) Un formato di file, salta le directory su altri formati di file.(-R) Invertire il risultato del confronto, (-H) per confrontare il formato leggibile dall'uomo.IL comando stat viene utilizzato per ottenere informazioni sulla dimensione del file, il permesso di accesso, il tempo di accesso e l'ID utente e l'ID gruppo del file.
$ stat anaconda-ks.cfg.

In questa sezione, discuteremo alcuni dei comandi di rete che i principianti possono utilizzare per risolvere i problemi relativi alla rete.
Una delle operazioni molto comuni eseguite in qualsiasi rete è verificare se un determinato host è raggiungibile o meno. Possiamo usare il comando ping per verificare la connettività con l'altro host.
La sintassi generale del ping comando è:
$ ping [OPZIONI]
Qui, la destinazione può essere un indirizzo IP o un nome di dominio completo (FQDN) come google.com. Verifichiamo che il sistema attuale possa comunicare con google:
$ ping -c 4 google.com.

Nell'esempio precedente, il comando mostra le statistiche sulla comunicazione di rete, che mostra che la risposta è stata ricevuta per tutte e quattro le richieste di rete (pacchetti). È importante notare che abbiamo utilizzato il file -C opzione con il comando per limitare il numero di richieste da inviare al particolare host.
Vediamo l'esempio quando la comunicazione tra i due host è interrotta.
Per simulare questo scenario, proveremo a raggiungere un indirizzo IP non raggiungibile. In questo caso lo è 192.168.10.100:
$ping -c4 192.168.10.100.

Qui, possiamo vedere che non abbiamo ricevuto una risposta per nessuna richiesta di rete. Quindi il comando segnala l'errore - Host di destinazione non raggiungibile.
A volte, dobbiamo trovare l'indirizzo IP di un particolare dominio. Per raggiungere questo obiettivo, possiamo utilizzare il ospite comando, che esegue una ricerca DNS e traduce FQDN in indirizzo IP e viceversa.
La sintassi generale del ospite comando è:
$ host [OPZIONI]
Qui la destinazione può essere un indirizzo IP o FQDN.
Scopriamo l'indirizzo IP di Google.com utilizzando il ospite comando:
$ host google.com.

Tutti i dettagli sui domini registrati sono memorizzati nel database centralizzato e possono essere interrogati utilizzando il comando whois, che mostra i dettagli sul dominio specifico.
La sintassi generale del chi è comando è:
$ whois [OPZIONI]
Scopriamo i dettagli del google.com:
$ whois google.com.
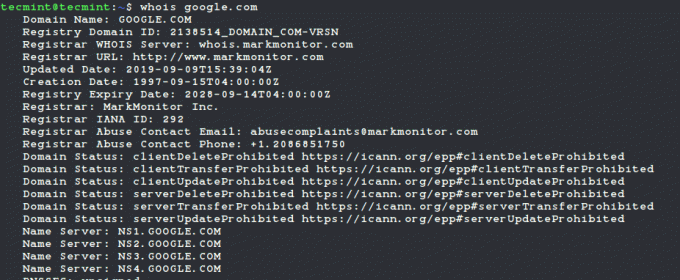
Qui possiamo vedere informazioni molto dettagliate come: data di registrazione/rinnovo/scadenza del dominio, provider del dominio e così via.
È importante notare che, il chi è Il comando non è disponibile per impostazione predefinita su tutti i sistemi. Tuttavia, possiamo installarlo utilizzando il gestore pacchetti. Ad esempio, su Distribuzioni basate su Debian possiamo installarlo usando il gestore di pacchetti apt:
$ sudo apt install whois.
SU Basato su RHEL e altre distribuzioni, puoi installarlo come mostrato.
$ sudo yum installa whois [On RHEL/CentOS/Fedora E Rocky Linux/AlmaLinux] $ sudo emerge -a net-misc/whois [OnGentooLinux] $ sudo apk add whois [OnLinux alpino] $ sudo pacman -S whois [OnArcoLinux] $ sudo zypper install whois [OnOpenSUSE]
In questa sezione, discuteremo alcuni dei comandi che possono fornire dettagli sul sistema corrente.
È un requisito molto comune trovare quando il sistema è stato riavviato l'ultima volta utilizzando il file comando di tempo di attività, che indica da quanto tempo il sistema è in esecuzione.
Scopriamo il tempo di attività del sistema attuale:
$ tempo di attività -p 12:10:57 fino alle 2:00, 1 utente, carico medio: 0,48, 0,60, 0,45
In questo esempio, abbiamo utilizzato il -P opzione per mostrare l'output nella forma carina.
Gli utenti hanno spesso bisogno di trovare i dettagli sulla memoria installata, disponibile e utilizzata. Queste informazioni svolgono un ruolo importante durante la risoluzione dei problemi di prestazioni. Possiamo usare il comando gratuito per trovare i dettagli sulla memoria:
$ gratis -m.
Qui, abbiamo usato il -M opzione con il comando che mostra l'output in mebibyte.

In modo simile, possiamo il -G, -T, E -P opzioni per mostrare l'output rispettivamente in gibibyte, tebibyte e pebibyte.
I sistemi informatici memorizzano i dati su dispositivi a blocchi. Esempi di dispositivi a blocchi sono le unità disco rigido (HDD), le unità a stato solido (SSD) e così via. Possiamo usare il comando lsblk per visualizzare informazioni dettagliate sui dispositivi a blocchi:
$ lsblk.
In questo esempio, possiamo vedere che esiste un solo dispositivo a blocchi e il suo nome è /dev/sda. Ci sono tre partizioni create su quel dispositivo a blocchi.

In questo articolo, abbiamo discusso alcuni dei comandi utili per i principianti di Linux. Innanzitutto, abbiamo discusso i comandi del file system. Quindi abbiamo discusso dei comandi di rete. Infine, abbiamo discusso alcuni comandi che fornivano dettagli sul sistema attuale.
