
La Linux Foundation ha annunciato il LFCS (Amministratore di sistema certificato Linux Foundation), un nuovo programma che mira ad aiutare le persone di tutto il mondo a ottenere la certificazione nelle attività di amministrazione di sistema di base e intermedie per i sistemi Linux. Ciò include il supporto di sistemi e servizi in esecuzione, insieme alla risoluzione dei problemi e all'analisi di prima mano e al processo decisionale intelligente per inoltrare i problemi ai team di progettazione.

Si prega di guardare il seguente video che dimostra il programma di certificazione Linux Foundation.
La serie si intitolerà Preparazione per il LFCS (Amministratore di sistema certificato Linux Foundation) Parti 1 attraverso 10 e tratta i seguenti argomenti per Ubuntu, CentOS e openSUSE:
Parte 1: Come usare il comando GNU 'sed' per creare, modificare e manipolare file in Linux
Importante: A causa di cambiamenti nei requisiti di certificazione LFCS in vigore febbraio 2, 2016, stiamo includendo i seguenti argomenti necessari alla serie LFCS pubblicata qui. Per prepararti a questo esame, ti consigliamo vivamente di utilizzare il Serie LFCE anche.
Questo post è parte 1 di una 20 serie di tutorial, che riguarderà i domini e le competenze necessari per il LFCS esame di certificazione. Detto questo, accendi il tuo terminale e iniziamo.
Linux tratta l'input e l'output dei programmi come flussi (o sequenze) di caratteri. Per iniziare a comprendere il reindirizzamento e le pipe, dobbiamo prima comprendere i tre tipi più importanti di flussi di I/O (Input e Output), che sono infatti file speciali (per convenzione in UNIX e Linux, anche i flussi di dati e le periferiche, o file di dispositivo, sono trattati come file ordinari).
La differenza tra > (operatore di reindirizzamento) e | (operatore pipeline) è che mentre il primo collega un comando con un file, il secondo collega l'output di un comando con un altro comando.
# comando > file. # comando1 | comando2.
Poiché l'operatore di reindirizzamento crea o sovrascrive i file silenziosamente, dobbiamo usarlo con estrema cautela e non confonderlo mai con una pipeline. Un vantaggio delle pipe su sistemi Linux e UNIX è che non sono coinvolti file intermedi una pipe – lo stdout del primo comando non viene scritto su un file e quindi letto dal secondo comando.
Per i seguenti esercizi utilizzeremo la poesia “Un bambino felice” (autore anonimo).
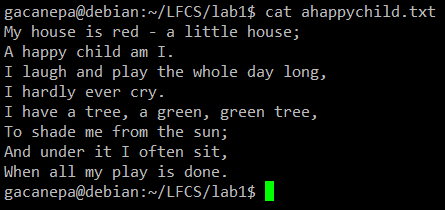
Il nome sed è l'abbreviazione di editor di flussi. Per chi non ha familiarità con il termine, viene utilizzato un editor di flussi per eseguire trasformazioni di testo di base su un flusso di input (un file o un input da una pipeline).
L'uso più elementare (e popolare) di sed è la sostituzione dei caratteri. Inizieremo modificando ogni occorrenza del minuscolo sì in MAIUSCOLO sì e reindirizzando l'output a ahappychild2.txt. Il G flag indica che sed deve eseguire la sostituzione per tutte le istanze di term su ogni riga del file. Se questo flag viene omesso, sed sostituirà solo la prima occorrenza di term su ogni riga.
# sed file "s/term/replacement/flag".
# sed 's/y/Y/g' ahappychild.txt > ahappychild2.txt.

Se vuoi cercare o sostituire un carattere speciale (come /, \, &) è necessario eseguirne l'escape, nel termine o nelle stringhe di sostituzione, con una barra rovesciata.
Ad esempio, sostituiremo la parola e con una e commerciale. Allo stesso tempo, sostituiremo la parola io insieme a Voi quando il primo si trova all'inizio di una riga.
# sed 's/and/\&/g; s/^io/tu/g' ahappychild.txt.
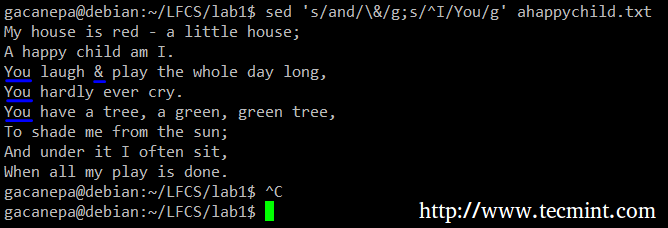
Nel comando sopra, a ^ (accento circonflesso) è un'espressione regolare ben nota che viene utilizzata per rappresentare l'inizio di una riga.
Come puoi vedere, possiamo combinare due o più comandi di sostituzione (e usare le espressioni regolari al loro interno) separandoli con un punto e virgola e racchiudendo l'insieme tra virgolette singole.
Un altro uso di sed è mostrare (o eliminare) una porzione scelta di un file. Nell'esempio seguente, mostreremo le prime 5 righe di /var/log/messages dall'8 giugno
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p.
Nota che per impostazione predefinita, sed stampa ogni riga. Possiamo ignorare questo comportamento con il -n opzione e poi dire a sed di stampare (indicato da P) solo la parte del file (o del tubo) che corrisponde al modello (8 giugno all'inizio della riga nel primo caso e le righe da 1 a 5 comprese nel secondo caso).
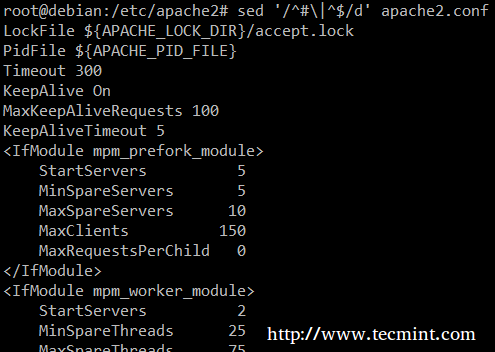
Infine, durante l'ispezione di script o file di configurazione può essere utile ispezionare il codice stesso e tralasciare commenti. Le seguenti eliminazioni di una riga di sed (D) righe vuote o che iniziano con # (il | carattere indica un OR booleano tra le due espressioni regolari).
# sed '/^#\|^$/d' apache2.conf.
Il unico Il comando ci consente di segnalare o rimuovere righe duplicate in un file, scrivendo su stdout per impostazione predefinita. Dobbiamo notare che unico non rileva linee ripetute a meno che non siano adiacenti. Così, unico è comunemente usato insieme a un precedente ordinare (utilizzato per ordinare le righe dei file di testo). Per impostazione predefinita, ordinare prende il primo campo (separato da spazi) come campo chiave. Per specificare un campo chiave diverso, dobbiamo usare il -K opzione.
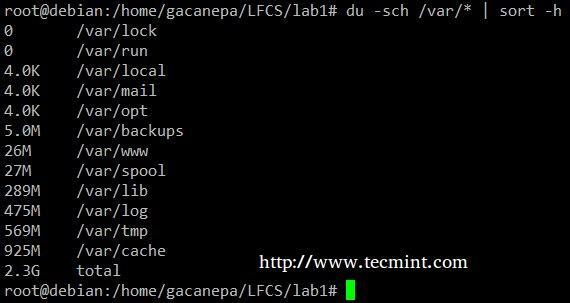
Il du –sch /percorso/alla/directory/* il comando restituisce l'utilizzo dello spazio su disco per sottodirectory e file all'interno della directory specificata in leggibile dall'uomo format (mostra anche un totale per directory) e non ordina l'output per dimensione, ma per sottodirectory e nome file. Possiamo usare il seguente comando per ordinare per dimensione.
# du -sch /var/* | sort –h.
Puoi contare il numero di eventi in un registro per data dicendo unico per eseguire il confronto utilizzando i primi 6 caratteri (-w 6) di ogni riga (dove è specificata la data) e anteponendo a ciascuna riga di output il numero di occorrenze (-C) con il seguente comando.
# cat /var/log/mail.log | uniq -c -w 6.

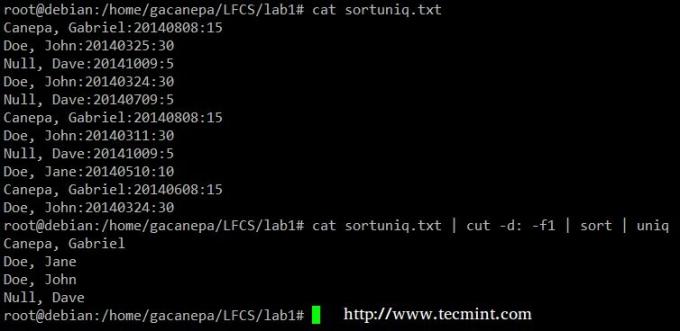
Finalmente puoi combinare ordinare e unico (come di solito sono). Considera il seguente file con un elenco di donatori, data di donazione e importo. Supponiamo di voler sapere quanti donatori unici ci sono. Useremo il seguente comando per tagliare il primo campo (i campi sono delimitati da due punti), ordinare per nome e rimuovere le righe duplicate.
# cat sortuniq.txt | cut -d: -f1 | ordina | unico
Leggi anche: 13 Esempi di comandi “cat”
grep ricerca file di testo o (output di comando) per l'occorrenza di un'espressione regolare specificata e restituisce qualsiasi riga contenente una corrispondenza con l'output standard.
Visualizza le informazioni da /etc/passwd per l'utente gacanepa, ignorando le maiuscole.
# grep -i gacanepa /etc/passwd.

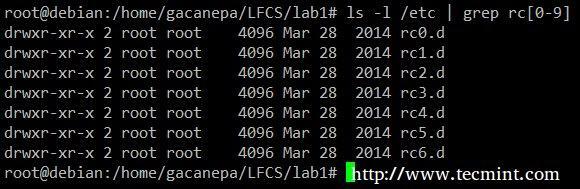
Mostra tutti i contenuti di /etc il cui nome inizia con rc seguito da un singolo numero.
# ls -l /etc | grep rc[0-9]
Leggi anche: 12 esempi di comandi "grep"
Il vero Il comando può essere utilizzato per tradurre (cambiare) o eliminare caratteri da stdin e scrivere il risultato su stdout.
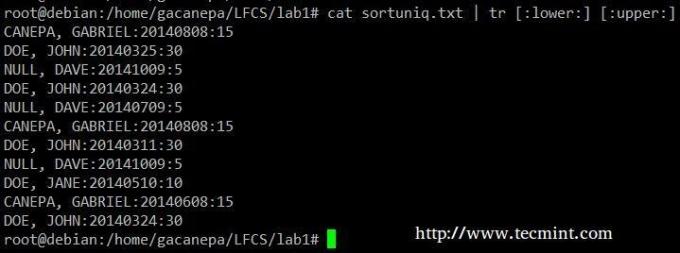
Cambia tutto da minuscolo a maiuscolo nel file sortuniq.txt.
# cat sortuniq.txt | tr [:inferiore:] [:superiore:]
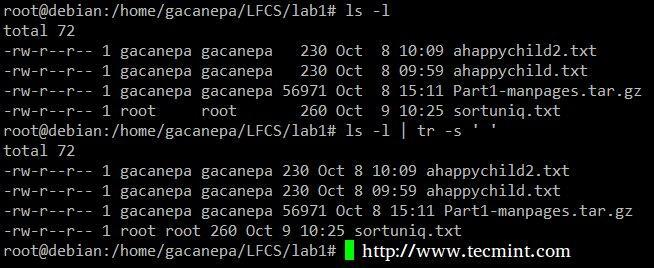
Spremere il delimitatore nell'output di ls –l a un solo spazio.
# ls -l | tr -s ' '
Il tagliare comando estrae porzioni di righe di input (da stdin o file) e visualizza il risultato sullo standard output, in base al numero di byte (-B opzione), caratteri (-C), o campi (-F). In quest'ultimo caso (basato sui campi), il separatore di campo predefinito è una tabulazione, ma è possibile specificare un delimitatore diverso utilizzando il -D opzione.
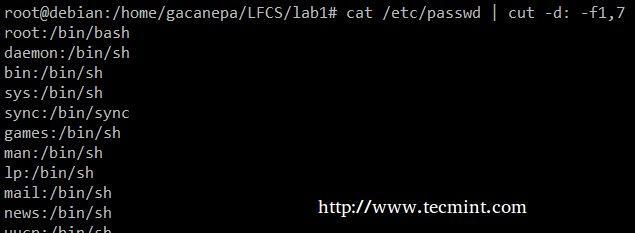
Estrai gli account utente e le shell predefinite a loro assegnate da /etc/passwd (il -D l'opzione ci consente di specificare il delimitatore di campo e il -F l'interruttore indica quale campo (i) verrà estratto.
# cat /etc/passwd | taglia -d: -f1,7.
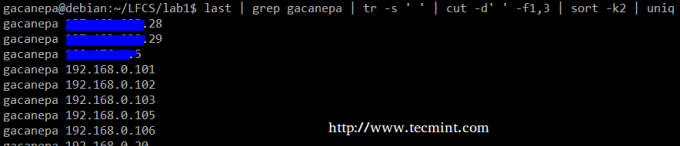
Riassumendo, creeremo un flusso di testo composto dal primo e dal terzo file non vuoto dell'output del ultimo comando. Noi useremo grep come primo filtro per verificare le sessioni dell'utente gacanepa, quindi stringi i delimitatori in un solo spazio (tr -s ‘ ‘). Successivamente, estrarremo il primo e il terzo campo con tagliare, e infine ordina in base al secondo campo (in questo caso indirizzi IP) che mostra univoco.
# ultimo | grep gacanepa | tr -s ' ' | cut -d' ' -f1,3 | sort -k2 | unico
Il comando sopra mostra come più comandi e pipe possono essere combinati in modo da ottenere dati filtrati secondo i nostri desideri. Sentiti libero di eseguirlo anche per parti, per aiutarti a vedere l'output che viene convogliato da un comando all'altro (questa può essere un'ottima esperienza di apprendimento, tra l'altro!).
Sebbene questo esempio (insieme al resto degli esempi nell'attuale tutorial) possa non sembrare molto utile a prima vista, sono un bel punto di partenza per iniziare a sperimentare con i comandi utilizzati per creare, modificare e manipolare file dal comando Linux linea. Sentiti libero di lasciare le tue domande e commenti qui sotto: saranno molto apprezzati!
