A Linux Alapítvány bejelentette LFCS (Linux Foundation Certified Sysadmin) tanúsítás, egy új program, amelynek célja, hogy segítse az egyéneket a világ minden tájáról, hogy tanúsítványt szerezzenek a Linux rendszerek alapvető és köztes rendszergazdai feladatairól. Ez magában foglalja a futó rendszerek és szolgáltatások támogatását, első kézből származó hibaelhárítást és elemzést, valamint az intelligens döntéshozatalt, hogy a problémákat mérnöki csapatokhoz terjesszék.

Nézze meg a következő videót, amely bemutatja a Linux Foundation Certification Programot.
A sorozat címe Felkészülés a LFCS (Linux Foundation Certified Sysadmin) Alkatrészek 1 keresztül 10 és fedezze fel az Ubuntu, a CentOS és az openSUSE következő témáit:
1. rész: Hogyan használjuk a GNU 'sed' parancsot fájlok létrehozásához, szerkesztéséhez és manipulálásához Linux alatt
Fontos: Az LFCS tanúsítási követelmények változásai miatt hatályos február 2, 2016, az alábbi szükséges témákat is belefoglaljuk az itt közzétett LFCS sorozatba. A vizsgára való felkészüléshez erősen ajánlott a LFCE sorozat is.
Ez a bejegyzés része 1 a 20 oktató sorozat, amely lefedi a szükséges területeket és kompetenciákat, amelyek szükségesek a LFCS tanúsító vizsga. Ennek ellenére gyújtsa fel a terminált, és kezdjük.
A Linux a programok bemenetét és kimenetét karakterfolyamként (vagy sorozatként) kezeli. Ahhoz, hogy megértsük az átirányítást és a csöveket, először meg kell értenünk az I/O (bemeneti és kimeneti) adatfolyamok három legfontosabb típusát, amelyek valójában speciális fájlok (a UNIX és a Linux megegyezés szerint az adatfolyamokat és a perifériákat, vagy az eszközfájlokat szintén közönséges fájlokként kezelik).
A különbség > (átirányítási operátor) és | (pipeline operator) az, hogy míg az első egy parancsot egy fájlhoz kapcsol, addig az utóbbi a parancs kimenetét egy másik paranccsal köti össze.
# parancs> fájl. # parancs1 | parancs2.
Mivel az átirányítási operátor csendben hozza létre vagy írja felül a fájlokat, rendkívül óvatosan kell használnunk, és soha ne tévesszük össze egy folyamatgal. A csövek egyik előnye Linux és UNIX rendszereken az, hogy nincs köztes fájl cső - az első parancs stdout -ját nem írják fájlba, majd a második olvassa el parancs.
A következő gyakorlatokhoz a „Boldog gyermek”(Névtelen szerző).
A név sed a stream szerkesztő rövidítése. Azok számára, akik nem ismerik ezt a kifejezést, egy adatfolyam -szerkesztőt használnak az alapvető szövegátalakítások végrehajtására egy bemeneti adatfolyamon (fájl vagy folyamatból származó bemenet).
A sed legalapvetőbb (és legnépszerűbb) használata a karakterek helyettesítése. Kezdjük a kisbetűk minden előfordulásának megváltoztatásával y nagybetűsre Y és átirányítja a kimenetet erre ahappychild2.txt. Az g zászló azt jelzi, hogy a sednek a kifejezés minden példányát helyettesítenie kell a fájl minden sorában. Ha ezt a jelzőt kihagyja, akkor a sed csak az első sor előfordulását fogja helyettesíteni minden sorban.
# sed ’s/term/csere/zászló fájl.
# sed ’s/y/Y/g’ ahappychild.txt> ahappychild2.txt.

Ha speciális karaktert szeretne keresni vagy cserélni (pl /, \, &) menekülnie kell, a kifejezésben vagy a karakterláncokban, visszafelé fordítva.
Például helyettesítjük a szót és az ampersand -ot. Ugyanakkor lecseréljük a szót én val vel Ön amikor az első a sor elején található.
# sed 's/és/\ &/g; s/^Én/Te/g 'ahappychild.txt.
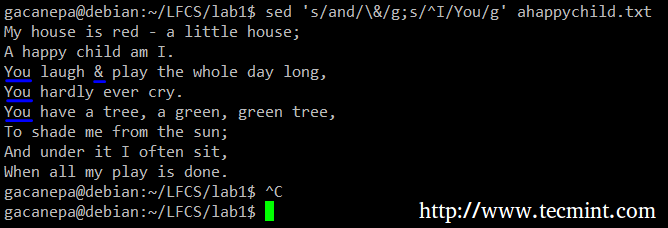
A fenti parancsban a ^ (caret jel) egy jól ismert szabályos kifejezés, amelyet egy sor elejének ábrázolására használnak.
Amint láthatja, két vagy több helyettesítő parancsot kombinálhatunk (és használhatunk bennük reguláris kifejezéseket), pontosvesszővel elválasztva és a halmazt idézőjelek közé zárva.
A sed másik felhasználása a fájl kiválasztott részének megjelenítése (vagy törlése). A következő példában az első 5 sort jelenítjük meg /var/log/messages június 8 -tól.
# sed -n '/^június 8./p'/var/log/messages | sed -n 1,5p.
Vegye figyelembe, hogy alapértelmezés szerint a sed minden sort kinyomtat. Ezt a viselkedést felülírhatjuk a -n opciót, majd mondja meg a sednek, hogy nyomtassa ki (jelzi o) csak a fájlnak az a része (vagy a cső), amely megfelel a mintának (június 8. a sor elején az első esetben, és az 1-5. sorok a második esetben).
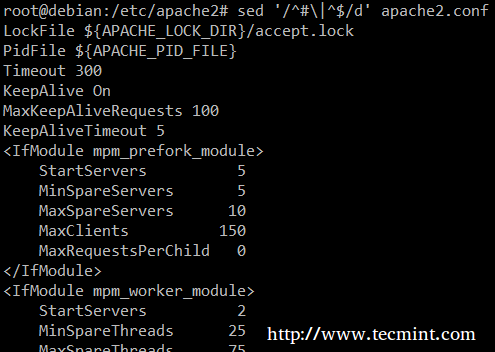
Végül, a szkriptek vagy konfigurációs fájlok ellenőrzése során hasznos lehet a kód ellenőrzése és a megjegyzések elhagyása. A következő sed egysoros törli (d) üres sorok vagy a velük kezdődő sorok # (az | karakter logikai VAGY -ot jelez a két reguláris kifejezés között).
# sed '/^# \ |^$/d' apache2.conf.
Az uniq parancs lehetővé teszi számunkra, hogy jelentsük vagy távolítsuk el a fájlban lévő ismétlődő sorokat, alapértelmezés szerint az stdout -hoz írva. Meg kell jegyeznünk, hogy uniq nem észleli az ismétlődő vonalakat, hacsak nem szomszédosak. Így, uniq általában az előzővel együtt használják fajta (amely a szöveges fájlok sorainak rendezésére szolgál). Alapértelmezés szerint, fajta az első mezőt (szóközökkel elválasztva) kulcsmezőnek veszi. Egy másik kulcsmező megadásához a -k választási lehetőség.
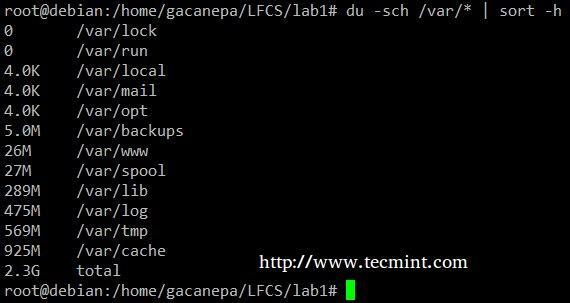
Az du –sch/path/to/directory/* parancs visszaadja a lemezterület-felhasználást a megadott könyvtárban lévő alkönyvtárak és fájlok szerint, ember által olvashatóan formátumban (könyvtáranként összesen is megjelenik), és nem a méret szerint rendezi a kimenetet, hanem alkönyvtár és fájlnév szerint. A következő paranccsal méret szerint rendezhetjük.
# du -sch /var /* | rend - h.
Az események számát a naplóban dátum szerint számolhatja, ha elmondja uniq az összehasonlítás elvégzése minden sor első 6 karakterével (-w 6) (ahol a dátum van megadva), és minden kimeneti sor előtagja az előfordulás számával (-c) a következő paranccsal.
# macska /var/log/mail.log | uniq -c -w 6.

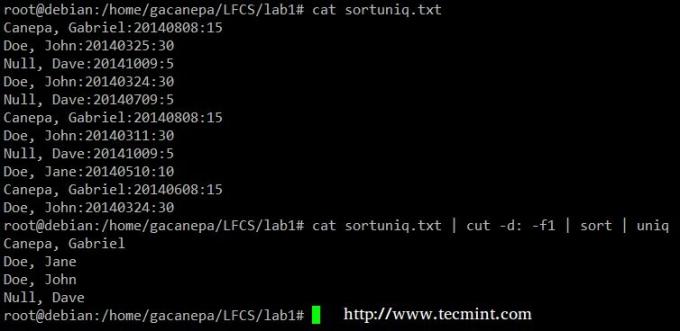
Végül kombinálhatod fajta és uniq (mint általában). Tekintse meg a következő fájlt az adományozók listájával, az adományozás dátumával és összegével. Tegyük fel, hogy tudni akarjuk, hány egyedi donor van. A következő paranccsal vágjuk le az első mezőt (a mezőket kettőspont határozza meg), név szerint rendezzük és eltávolítjuk az ismétlődő sorokat.
# macska sortuniq.txt | vágott -d: -f1 | rendezés | uniq.
Olvassa el: 13 példa „macska” parancsokra
grep szövegfájlokban vagy (parancskimenetben) keresi a megadott reguláris kifejezés előfordulását, és minden olyan sort kiad, amely megfelel a standard kimenetnek.
Jelenítse meg a (z) /etc/passwd a gacanepa felhasználó számára, figyelmen kívül hagyva a kis- és nagybetűket.
# grep -i gacanepa /etc /passwd.

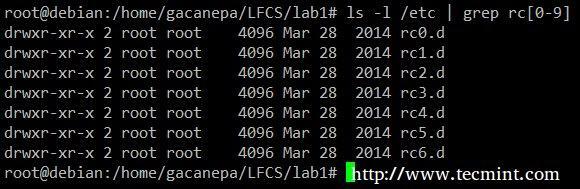
A tartalom megjelenítése /etc akinek a neve azzal kezdődik rc amelyet egyetlen szám követ.
# ls -l /etc | grep rc [0-9]
Olvassa el: 12 „grep” parancs példa
Az tr parancs használható karakterek fordítására (módosítására) vagy törlésére az stdin -ből, és az eredmény írására az stdout -ba.
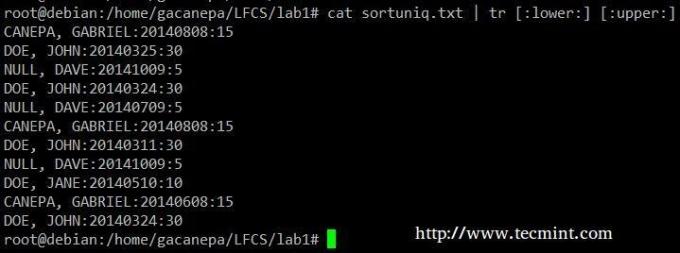
Módosítsa az összes kisbetűt nagybetűre a sortuniq.txt fájlban.
# macska sortuniq.txt | tr [: alsó:] [: felső:]
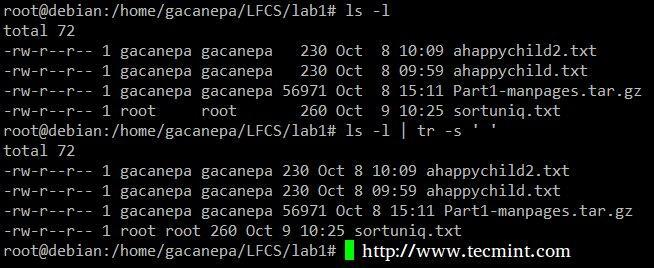
Nyomja össze az elválasztót a kimenetében ls –l csak egy térre.
# ls -l | tr -s "
Az vágott parancs kivonja a bemeneti sorok egy részét (az stdinből vagy a fájlokból), és megjeleníti az eredményt a standard kimeneten, a bájtok száma alapján (-b opció), karakterek (-c), vagy mezők (-f). Ebben az utolsó esetben (a mezők alapján) az alapértelmezett mezőelválasztó lap, de más elválasztó megadható a -d választási lehetőség.
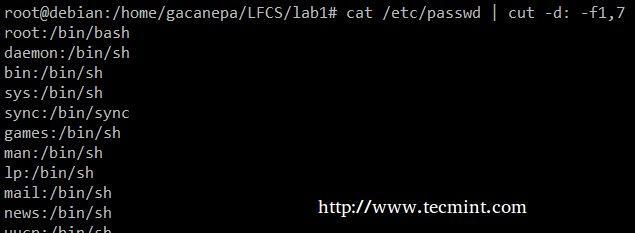
Bontsa ki a felhasználói fiókokat és a hozzájuk rendelt alapértelmezett héjakat /etc/passwd (az –D opció lehetővé teszi a mező határoló megadását, és a –F kapcsoló jelzi, hogy melyik mező (k) kerülnek kitermelésre.
# cat /etc /passwd | vágott -d: -f1,7.
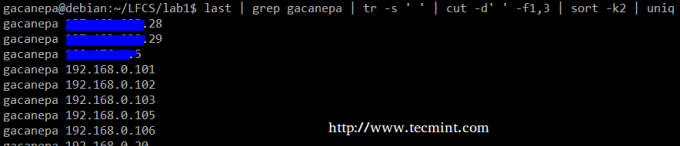
Összefoglalva létrehozunk egy szöveges adatfolyamot, amely a kimenet első és harmadik nem üres fájljából áll utolsó parancs. Használni fogjuk grep első szűrőként a felhasználói munkamenetek ellenőrzésére gacanepa, majd nyomja le az elválasztókat csak egy szóközre (tr -s ‘ ‘). Ezután kivonjuk az első és a harmadik mezőt vágott, és végül rendezze a második mező (ebben az esetben IP -címek) alapján.
# utolsó | grep gacanepa | tr -s '' | vágott -d '' -f1,3 | rendezés -k2 | uniq.
A fenti parancs bemutatja, hogyan lehet több parancsot és csövet kombinálni, hogy a vágyainknak megfelelően szűrt adatokat kapjunk. Nyugodtan futtassa azt is alkatrészenként, hogy lássa az egyik parancsról a másikra felvitt kimenetet (ez egyébként nagyszerű tanulási élmény lehet!).
Bár ez a példa (az oktatóanyag többi példájával együtt) első pillantásra nem tűnik túl hasznosnak, mégis jó kiindulópont a Linux parancsból fájlok létrehozására, szerkesztésére és manipulálására használt parancsokkal való kísérletezés megkezdésére vonal. Bátran hagyja kérdéseit és megjegyzéseit az alábbiakban - nagyra értékeljük!