Ukratko: U ovom ćemo vodiču raspravljati o nekim praktičnim primjerima naredbe egrep. Nakon što slijede ovaj vodič, korisnici će moći učinkovitije pretraživati tekst u Linuxu.
Jeste li ikada bili frustrirani jer ne možete pronaći potrebne informacije u zapisima? Izdvajanje potrebnih informacija iz velikog skupa podataka složen je i dugotrajan zadatak.
Stvari postaju zaista izazovne ako operativni sustav ne nudi prave alate i tu dolazi Linux da vas spasi. Linux nudi razne alate za filtriranje teksta kao što su nezgodno, sed, izrezatiitd.
Međutim, egrep je jedan od najmoćnijih i najčešće korištenih uslužnih programa za obradu teksta u Linuxu, a mi ćemo raspravljati o nekim primjerima egrep naredba.
The egrep naredbu u Linuxu prepoznaje obitelj naredba grep, koji se koristi za pretraživanje i podudaranje određenog uzorka u datotekama. Djeluje slično kao grep -E (grep Extended regex), ali uglavnom pretražuje određenu datoteku ili čak retke do retka ili ispisuje redak u datoj datoteci.
Sintaksa egrep naredba je sljedeća:
$ egrep [OPCIJE] UZORACI [DATOTEKE]
Stvorimo oglednu tekstualnu datoteku sa sljedećim sadržajem kao primjer:
$ cat sample.txt.

Ovdje možemo vidjeti da je tekstualna datoteka spremna. Sada raspravimo nekoliko uobičajenih primjera koji se mogu koristiti svakodnevno.
Počnimo s jednostavnim primjerom podudaranja uzorka, gdje možemo koristiti naredbu u nastavku za traženje niza profesionalni u uzorak.txt datoteka:
$ egrep professionals sample.txt.

Ovdje možemo vidjeti da naredba ispisuje redak koji sadrži navedeni uzorak.
Ispis možemo učiniti informativnijim isticanjem odgovarajućeg uzorka. Da bismo to postigli, možemo koristiti --boja opcija od egrep naredba. Na primjer, donja naredba označit će tekst profesionalci u crvenoj boji:
$ egrep --color=auto professionals sample.txt.

Ovdje možemo vidjeti da je isti izlaz informativniji u usporedbi s prethodnim. Također, lako možemo identificirati tu riječ profesionalci ponavlja se dva puta.
Na većini Linux sustava gornja postavka omogućena je prema zadanim postavkama koristeći sljedeći alias:
$ alias egrep='egrep –color=auto'
The egrep naredba prihvaća više datoteka kao argument, što nam omogućuje traženje određenog uzorka u više datoteka. Shvatimo ovo na primjeru.
Najprije izradite kopiju uzorak.txt datoteka:
$ cp sample.txt sample-copy.txt.
Sada pretražite uzorak profesionalci u obje datoteke:
$ egrep professionals sample.txt sample-copy.txt
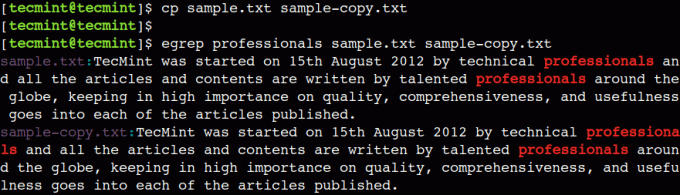
U gornjem primjeru, možemo vidjeti naziv datoteke u izlazu, koji predstavlja odgovarajući redak iz te datoteke.
Ponekad samo trebamo saznati postoji li uzorak u datoteci ili ne. Ako da, u koliko je redaka prisutan? U takvim slučajevima možemo koristiti -c opcija naredbe.
Na primjer, prikazat će se donja naredba 1 kao izlaz jer riječ profesionalci prisutan je samo u jednom redu.
$ egrep -c profesionalci sample.txt 1
U prethodnom primjeru vidjeli smo da je -c opcija ne broji broj pojavljivanja uzorka. Na primjer, riječ profesionalci pojavljuje se dva puta u istom retku, ali -c opcija tretira samo kao jedno podudaranje.
U takvim slučajevima možemo koristiti -o opcija naredbe za ispis samo odgovarajućeg uzorka. Na primjer, donja naredba prikazat će riječ profesionalci u dva odvojena retka:
$ egrep -o profesionalci sample.txt.
Sada prebrojimo retke pomoću wc naredba:
$ egrep -o profesionalci sample.txt | wc -l.

U gornjem primjeru upotrijebili smo kombinaciju egrep i zahod naredbe za brojanje broja pojavljivanja određenog uzorka.
Prema zadanim postavkama egrep izvodi podudaranje uzoraka na način koji razlikuje velika i mala slova. To znači riječi - mi, mi, mi i MI se tretiraju kao različite riječi. Međutim, možemo nametnuti pretraživanje koje ne razlikuje velika i mala slova pomoću -i opcija.
Na primjer, u donjoj naredbi uzorak podudaranja će uspjeti za tekst mi i Mi:
$ egrep -i we sample.txt
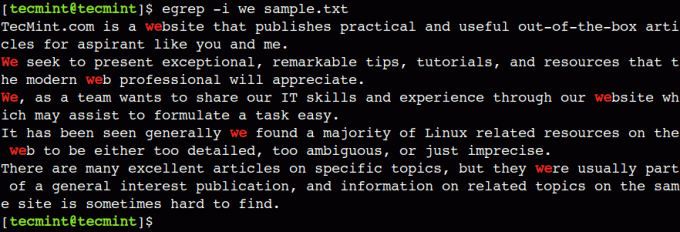
U prethodnom primjeru vidjeli smo da je egrep naredba izvodi djelomično podudaranje. Na primjer, kada smo tražili tekst mi tada je podudaranje uzoraka uspjelo i za druge tekstove. Kao što su web, web stranica i bili.
Kako bismo prevladali ovo ograničenje, možemo -w opcija, koja nameće podudaranje cijele riječi.
$ egrep -w we sample.txt.

Do sada smo koristili egrep naredba za ispis redaka u kojima je prisutan zadani uzorak. Međutim, ponekad želimo operaciju izvesti na suprotan način.
Na primjer, možemo htjeti ispisati retke u kojima zadani uzorak nije prisutan. To možemo postići uz pomoć -v opcija:
$ egrep -v we sample.txt.

Ovdje možemo vidjeti da naredba ispisuje sve retke koji ne sadrže tekst mi.
Možemo koristiti -n opcija naredbe za omogućavanje numeriranja redaka, koja prikazuje broj retka u izlazu kada usklađivanje uzorka uspije. Ovaj jednostavan trik čini rezultat smislenijim.
$ egrep -n profesionalci sample.txt.

U gornjem izlazu možemo vidjeti da riječ profesionalci prisutan je u 5 crta.
U tihom načinu rada, egrep naredba ne ispisuje odgovarajući uzorak. Dakle, moramo upotrijebiti povratnu vrijednost naredbe kako bismo utvrdili je li podudaranje uzoraka uspjelo ili nije.
Možemo koristiti -q opciju naredbe za uključivanje tihog načina rada, što je zgodno prilikom pisanja shell skripti.
$ egrep -q profesionalci sample.txt. $ egrep -q uzorak nepostojećeg uzorka.txt.
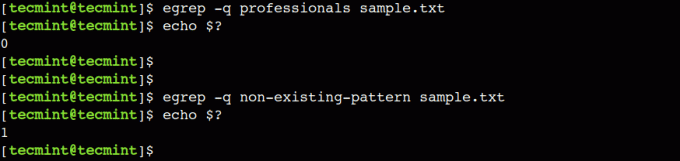
U ovom primjeru, nula povratna vrijednost označava prisutnost uzorka dok vrijednost različita od nule označava odsutnost uzorka.
Ponekad ima smisla prikazati nekoliko linija oko odgovarajućeg uzorka. Za takve scenarije možemo koristiti -B opcija naredbe, koja se prikazuje N linije prije usklađenog uzorka.
Na primjer, donja naredba ispisat će redak za koji je uspjelo podudaranje uzorka, kao i 2 retka prije njega.
$ egrep -B 2 -n profesionalci sample.txt

U ovom primjeru koristili smo -n mogućnost prikaza brojeva redaka.
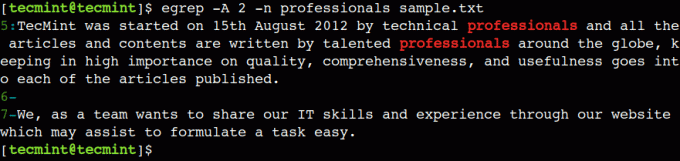
Na sličan način možemo koristiti -A opcija naredbe za prikaz linija nakon podudaranja uzorka. Na primjer, donja naredba ispisat će redak za koji je uspjelo podudaranje uzorka, kao i sljedeća 2 retka.
$ egrep -A 2 -n professionals sample.txt.
Pored ovoga, egrep naredba podržava -C opcija koja kombinira funkcionalnost opcija -A i -B, koji prikazuje crte prije i poslije podudarnog uzorka.
$ egrep -C 2 -n professionals sample.txt

Kao što je prethodno objašnjeno, možemo izvršiti podudaranje uzoraka na više datoteka. Međutim, situacija postaje škakljiva kada su datoteke prisutne u više poddirektorija i sve ih prosljeđujemo kao argumente naredbe.
U takvim slučajevima možemo izvršiti podudaranje uzorka na rekurzivan način koristeći -r opcija kao što je prikazano u sljedećem primjeru.
Najprije stvorite 2 poddirektorija i kopirajte uzorak.txt datoteku u njih:
$ mkdir -p dir1/dir2. $ cp sample.txt dir1/ $ cp sample.txt dir1/dir2/
Izvedimo sada operaciju pretraživanja na rekurzivan način:
$ egrep -r profesionalci dir1.

U gornjem primjeru možemo vidjeti da je podudaranje uzorka uspjelo za dir1/dir2/uzorak.txt i dir1/uzorak.txt datoteke.
Možemo koristiti točku (.) znak za podudaranje s bilo kojim pojedinačnim znakom osim za kraj retka. Na primjer, regularni izraz u nastavku odgovara tekstu har, hat i ima:
$ egrep "ha." uzorak.txt.

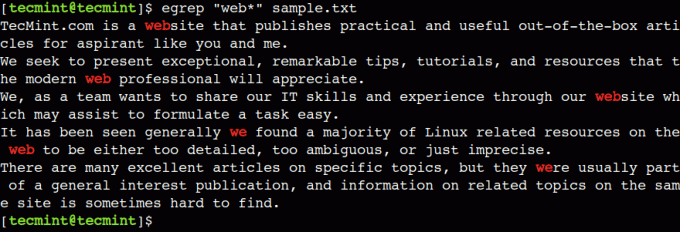
Možemo koristiti zvjezdicu (*) za podudaranje s nula ili više pojavljivanja prethodnog znaka. Na primjer, donji regularni izraz odgovara tekstu koji sadrži niz mi nakon čega slijedi nula ili više pojavljivanja znaka b.
$ egrep "web*" sample.txt.
Možemo koristiti plus (+) za podudaranje s jednim ili više pojavljivanja prethodnog znaka. Na primjer, donji regularni izraz odgovara tekstu koji sadrži niz mi nakon čega slijedi barem jedno pojavljivanje znaka b.
$ egrep "web+" sample.txt.
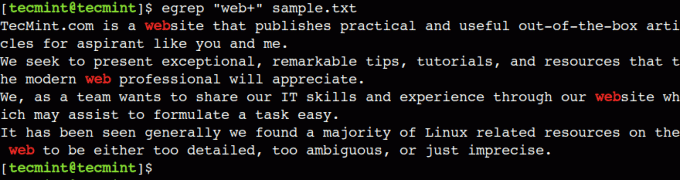
Ovdje možemo vidjeti da podudaranje uzoraka ne uspijeva za riječi - mi i bili, zbog odsutnosti lika b.
Možemo koristiti karet (^) predstavljati početak retka. Na primjer, donji regularni izraz ispisuje retke koji počinju s tekstom Mi:
$ egrep "^Mi" sample.txt.

Možemo koristiti dolar ($) predstavljati kraj retka. Na primjer, donji regularni izraz ispisuje retke koji završavaju tekstom e.:
$ egrep "e.$" sample.txt.

Možemo koristiti karet (^) odmah nakon toga slijedi dolar ($) za predstavljanje prazne linije. Upotrijebimo ovo u regularnom izrazu za uklanjanje praznih redaka:
$ egrep -n -v "^$" uzorak.txt.

U gornjem izlazu možemo vidjeti da brojevi redaka 2, 4, 6, 8 i 10 nisu prikazani jer su prazni.
U ovom smo članku raspravljali o nekim korisnim primjerima egrep naredbe. Ovi se primjeri mogu koristiti u svakodnevnom životu za poboljšanje produktivnosti.
Znate li za neki drugi najbolji primjer naredbe egrep u Linuxu? Recite nam svoje stavove u komentarima ispod.

