
Dans les articles précédents de ce Série RAID vous êtes passé de zéro à RAID hero. Nous avons passé en revue plusieurs configurations RAID logicielles et expliqué l'essentiel de chacune, ainsi que les raisons pour lesquelles vous pencheriez vers l'une ou l'autre en fonction de votre scénario spécifique.

Dans ce guide, nous expliquerons comment reconstruire une matrice RAID logicielle sans perte de données en cas de panne de disque. Par souci de concision, nous ne considérerons qu'un RAID 1 setup - mais les concepts et les commandes s'appliquent à tous les cas de la même manière.
Avant d'aller plus loin, assurez-vous d'avoir configuré un RAID 1 tableau en suivant les instructions fournies dans la partie 3 de cette série: Comment configurer RAID 1 (Miroir) sous Linux.
Les seules variantes dans notre cas présent seront :
1) une version différente de CentOS (v7) que celle utilisée dans cet article (v6.5), et
2) différentes tailles de disque pour /dev/sdb et /dev/sdc (8 Go chacun).
De plus, si SELinux est activé en mode d'application, vous devrez ajouter les étiquettes correspondantes au répertoire où vous monterez le périphérique RAID. Sinon, vous rencontrerez ce message d'avertissement en essayant de le monter :
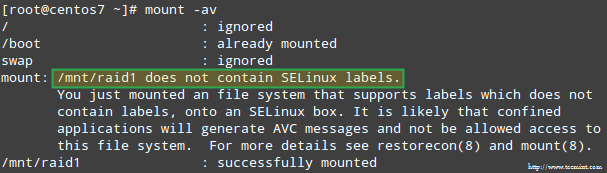
Vous pouvez résoudre ce problème en exécutant :
# restorecon -R /mnt/raid1.
Il existe diverses raisons pour lesquelles un périphérique de stockage peut tomber en panne (les SSD ont considérablement réduit les chances que cela se produise), mais quelle qu'en soit la cause. vous pouvez être sûr que des problèmes peuvent survenir à tout moment et vous devez être prêt à remplacer la pièce défectueuse et à garantir la disponibilité et l'intégrité de votre Les données.
Un conseil d'abord. Même quand tu peux inspecter /proc/mdstat afin de vérifier l'état de vos RAID, il existe une méthode meilleure et plus rapide qui consiste à exécuter mddam en mode moniteur + scan, qui enverra des alertes par e-mail à un destinataire prédéfini.
Pour configurer cela, ajoutez la ligne suivante dans /etc/mdadm.conf:
MAILADDR [email protégé]
Dans mon cas:
MAILADDR [email protégé]

Courir mddam en mode moniteur + analyse, ajoutez l'entrée crontab suivante en tant que root :
@reboot /sbin/mdadm --monitor --scan --oneshot.
Par défaut, mddam vérifiera les matrices RAID toutes les 60 secondes et enverra une alerte s'il détecte un problème. Vous pouvez modifier ce comportement en ajoutant le --retard option à l'entrée crontab ci-dessus avec le nombre de secondes (par exemple, --retard 1800 signifie 30 minutes).
Enfin, assurez-vous d'avoir un Agent d'utilisateur de messagerie (MUA) installés, tels que cabot ou mailx. Sinon, vous ne recevrez aucune alerte.
Dans une minute, nous verrons ce qu'est une alerte envoyée par mddam ressemble à.
Pour simuler un problème avec l'un des périphériques de stockage de la matrice RAID, nous utiliserons le --gérer et --set-faulty options comme suit :
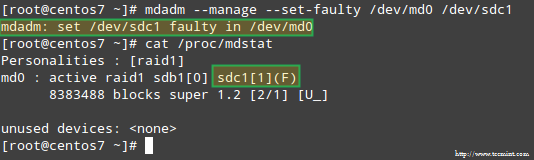
# mdadm --manage --set-faulty /dev/md0 /dev/sdc1
Cela se traduira par /dev/sdc1 étant marqué comme défectueux, comme on peut le voir dans /proc/mdstat:
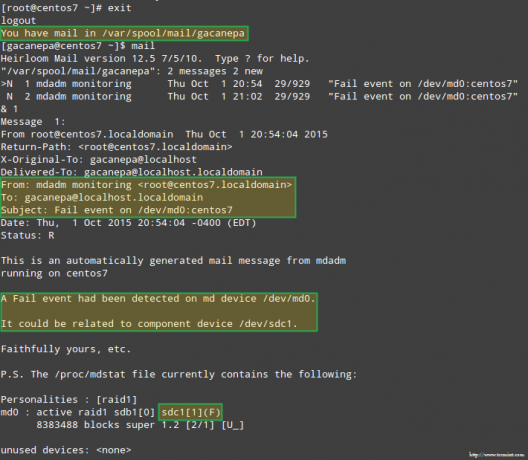
Plus important encore, voyons si nous avons reçu une alerte par e-mail avec le même avertissement :
Dans ce cas, vous devrez retirer le périphérique de la matrice RAID logicielle :
# mdadm /dev/md0 --remove /dev/sdc1.
Ensuite, vous pouvez le retirer physiquement de la machine et le remplacer par une pièce de rechange (/dev/sdd, où une partition de type fd a déjà été créé):
# mdadm --manage /dev/md0 --add /dev/sdd1.
Heureusement pour nous, le système commencera automatiquement à reconstruire le tableau avec la partie que nous venons d'ajouter. Nous pouvons tester cela en marquant /dev/sdb1 comme défectueux, en le supprimant du tableau et en s'assurant que le fichier tecmint.txt est toujours accessible sur /mnt/raid1:
# mdadm --detail /dev/md0. # monture | grep raid1. # ls -l /mnt/raid1 | grep tecmint. # cat /mnt/raid1/tecmint.txt.
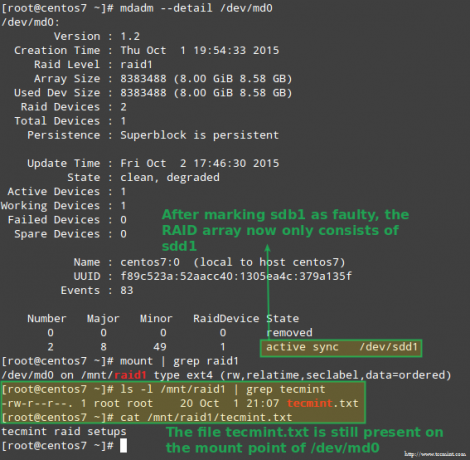
L'image ci-dessus montre clairement qu'après avoir ajouté /dev/sdd1 au tableau en remplacement de /dev/sdc1, la reconstruction des données a été effectuée automatiquement par le système sans intervention de notre part.
Bien que cela ne soit pas strictement requis, c'est une excellente idée d'avoir un appareil de rechange à portée de main afin que le processus de remplacement de l'appareil défectueux par un bon lecteur puisse être effectué en un clin d'œil. Pour ce faire, rajoutons /dev/sdb1 et /dev/sdc1:
# mdadm --manage /dev/md0 --add /dev/sdb1. # mdadm --manage /dev/md0 --add /dev/sdc1.
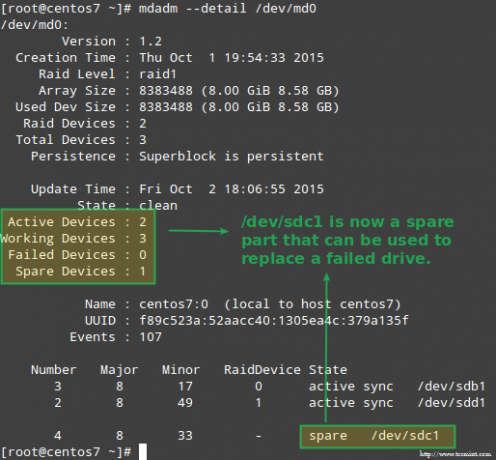
Comme expliqué précédemment, mddam reconstruira automatiquement les données lorsqu'un disque tombe en panne. Mais que se passe-t-il si 2 disques de la matrice échouent? Simulons un tel scénario en marquant /dev/sdb1 et /dev/sdd1 comme défectueux :
# umount /mnt/raid1. # mdadm --manage --set-faulty /dev/md0 /dev/sdb1. # mdadm --stop /dev/md0. # mdadm --manage --set-faulty /dev/md0 /dev/sdd1.
Tente de recréer le tableau de la même manière qu'il a été créé à ce moment (ou en utilisant le --assume-propre option) peut entraîner une perte de données, elle doit donc être laissée en dernier recours.
Essayons de récupérer les données de /dev/sdb1, par exemple, dans une partition de disque similaire (/dev/sde1 – notez que cela nécessite que vous créiez une partition de type fd dans /dev/sde avant de continuer) en utilisant ddrescue:
# ddrescue -r 2 /dev/sdb1 /dev/sde1.
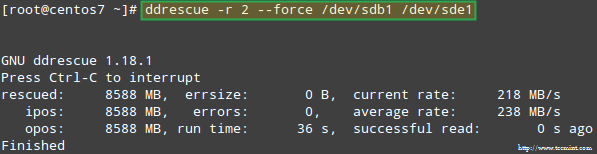
Veuillez noter que jusqu'à présent, nous n'avons pas touché /dev/sdb ou alors /dev/sdd, les partitions qui faisaient partie de la matrice RAID.
Reconstruisons maintenant le tableau en utilisant /dev/sde1 et /dev/sdf1:
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1.
Veuillez noter que dans une situation réelle, vous utiliserez généralement les mêmes noms de périphérique qu'avec la baie d'origine, c'est-à-dire /dev/sdb1 et /dev/sdc1 après que les disques défaillants aient été remplacés par de nouveaux.
Dans cet article, j'ai choisi d'utiliser des périphériques supplémentaires pour recréer la matrice avec de nouveaux disques et éviter toute confusion avec les disques défectueux d'origine.
Lorsqu'on lui a demandé s'il faut continuer à écrire le tableau, tapez Oui et appuyez sur Entrer. La baie doit être démarrée et vous devriez pouvoir suivre sa progression avec :
# watch -n 1 cat /proc/mdstat.
Une fois le processus terminé, vous devriez pouvoir accéder au contenu de votre RAID :
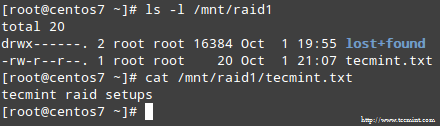
Dans cet article, nous avons examiné comment récupérer de RAID les pannes et les pertes de redondance. Cependant, vous devez vous rappeler que cette technologie est une solution de stockage et NE FAIT PAS remplacer les sauvegardes.
Les principes expliqués dans ce guide s'appliquent à toutes les configurations RAID, ainsi que les concepts que nous aborderons dans le prochain et dernier guide de cette série (gestion RAID).
Si vous avez des questions sur cet article, n'hésitez pas à nous laisser un message en utilisant le formulaire de commentaire ci-dessous. Nous avons hâte d'avoir de tes nouvelles!
