Lorsque nous exécutons certaines commandes sous Unix/Linux pour lire ou éditer du texte à partir d'une chaîne ou d'un fichier, nous essayons la plupart du temps de filtrer la sortie vers une section donnée d'intérêt. C'est là que l'utilisation d'expressions régulières est utile.
Lire aussi :10 opérateurs de chaînage Linux utiles avec des exemples pratiques
Une expression régulière peut être définie comme une chaîne qui représente plusieurs séquences de caractères. L'une des choses les plus importantes concernant les expressions régulières est qu'elles vous permettent de filtrer la sortie d'une commande ou d'un fichier, de modifier une section d'un texte ou d'un fichier de configuration, etc.
Les expressions régulières sont constituées de :
(.) il correspond à n'importe quel caractère, à l'exception d'un saut de ligne.(*) il correspond à zéro ou plusieurs existences du caractère immédiat qui le précède.[ personnages) ] il correspond à l'un des caractères spécifiés dans le(s) caractère(s), on peut également utiliser un tiret (-) pour signifier une gamme de caractères tels que [un F], [1-5], etc.^ il correspond au début d'une ligne dans un fichier.$ correspond à la fin de la ligne dans un fichier.\ c'est un caractère d'échappement.Pour filtrer du texte, il faut utiliser un outil de filtrage de texte tel que ok. Vous pouvez penser à ok comme langage de programmation à part entière. Mais pour la portée de ce guide d'utilisation ok, nous le couvrirons comme un simple outil de filtrage de ligne de commande.
La syntaxe générale de awk est :
# awk 'script' nom de fichier.
Où 'scénario' est un ensemble de commandes comprises par ok et sont exécutés sur le fichier, nom de fichier.
Il fonctionne en lisant une ligne donnée dans le fichier, fait une copie de la ligne puis exécute le script sur la ligne. Ceci est répété sur toutes les lignes du fichier.
Le 'scénario' est sous la forme '/modèle/action' où modèle est une expression régulière et le action est ce que awk fera lorsqu'il trouvera le motif donné dans une ligne.
Dans les exemples suivants, nous nous concentrerons sur les méta-caractères dont nous avons discuté ci-dessus sous les fonctionnalités de awk.
L'exemple ci-dessous imprime toutes les lignes du fichier /etc/hosts puisqu'aucun modèle n'est donné.
# awk'//{print}'/etc/hosts.

I l'exemple ci-dessous, un modèle hôte local a été donné, donc awk correspondra à la ligne ayant hôte local dans le /etc/hosts fichier.
# awk'/localhost/{imprimer}' /etc/hosts

Le (.) correspondra aux chaînes contenant loc, hôte local, réseau local dans l'exemple ci-dessous.
C'est-à-dire * l some_single_character c *.
# awk'/l.c/{imprimer}' /etc/hosts.

Il correspondra aux chaînes contenant hôte local, réseau local, lignes, capable, comme dans l'exemple ci-dessous :
# awk'/l*c/{imprimer}' /etc/localhost.

Vous vous rendrez également compte que (*) essaie de vous obtenir la correspondance la plus longue possible qu'il puisse détecter.
Regardons un cas qui le démontre, prenons l'expression régulière t*t ce qui signifie correspondre à des chaînes commençant par une lettre t et terminer par t dans la ligne ci-dessous :
c'est tecmint, où vous obtenez les meilleurs bons tutoriels, comment faire, guides, tecmint.
Vous obtiendrez les possibilités suivantes lorsque vous utilisez le modèle /t*t/:
c'est t. c'est parfait. c'est tecmint, où vous obtenez t. c'est tecmint, où vous obtenez le meilleur bon t. c'est tecmint, où vous obtenez les meilleurs bons tutoriels, comment t. c'est tecmint, où vous obtenez les meilleurs bons tutoriels, comment faire, guides, t. c'est tecmint, où vous obtenez les meilleurs bons tutoriels, comment faire, guides, tecmint.
Et (*) dans /t*t/ le caractère générique permet à awk de choisir la dernière option :
c'est tecmint, où vous obtenez les meilleurs bons tutoriels, comment faire, guides, tecmint.
Prenons par exemple l'ensemble [tous1], ici awk correspondra à toutes les chaînes contenant des caractères une ou alors je ou alors 1 dans une ligne du fichier /etc/hosts.
# awk'/[al1]/{imprimer}' /etc/hosts.

L'exemple suivant correspond aux chaînes commençant par K ou alors k suivi par T:
# awk'/[Kk]T/{imprimer}' /etc/hosts

Comprendre les caractères avec awk :
[0-9] signifie un seul nombre[a-z] signifie correspondre à une seule lettre minuscule[A-Z] signifie correspondre à une seule lettre majuscule[a-zA-Z] signifie correspondre à une seule lettre[a-zA-Z 0-9] signifie correspondre à une seule lettre ou un seul chiffreRegardons un exemple ci-dessous :
# awk'/[0-9]/{imprimer}' /etc/hosts
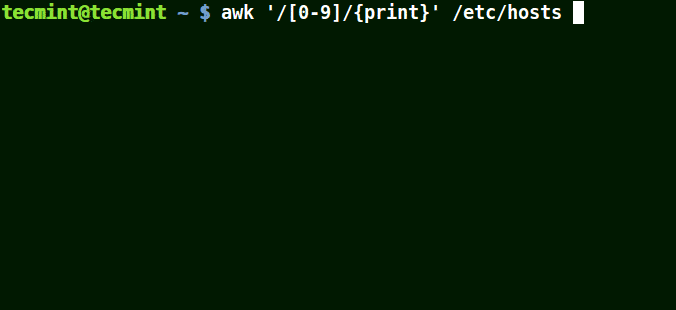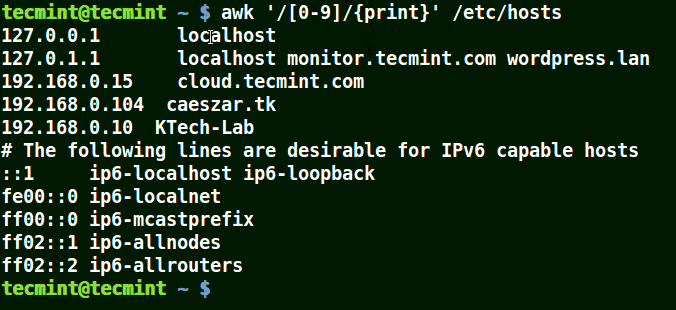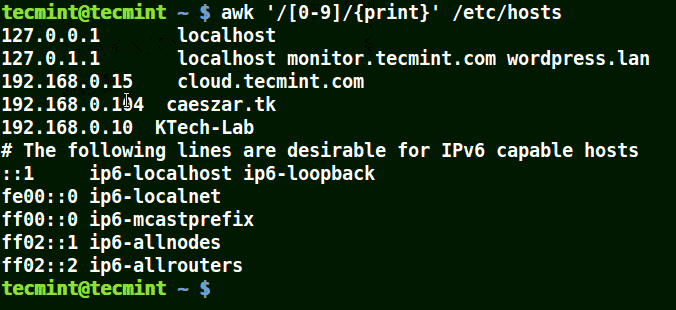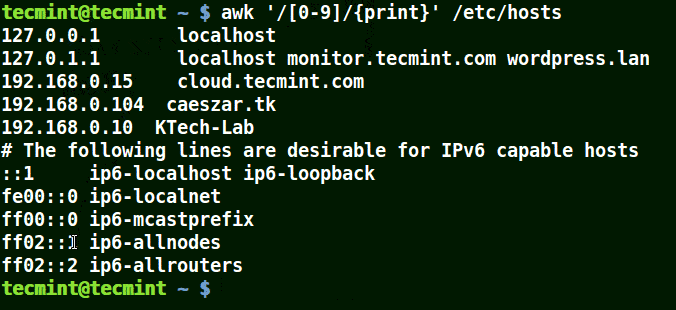
Toute la ligne du fichier /etc/hosts contenir au moins un seul nombre [0-9] dans l'exemple ci-dessus.
Il correspond à toutes les lignes qui commencent par le motif fourni comme dans l'exemple ci-dessous :
# awk'/^fe/{imprimer}' /etc/hosts. # awk'/^ff/{imprimer}' /etc/hosts.

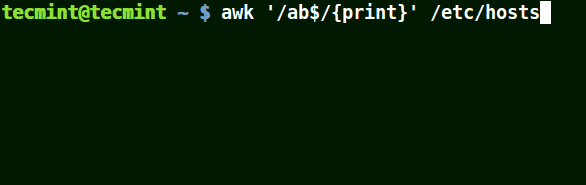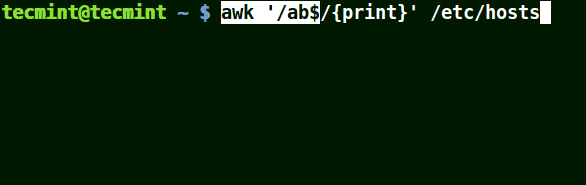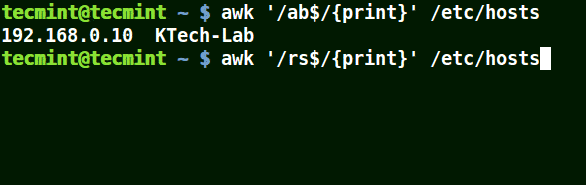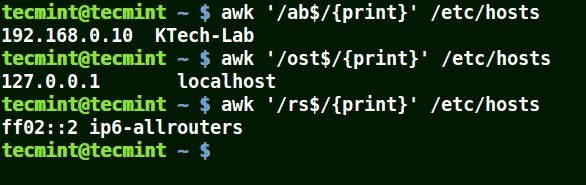
Il correspond à toutes les lignes qui se terminent par le motif fourni :
# awk'/ab$/{imprimer}' /etc/hosts. # awk'/ost$/{imprimer}' /etc/hosts. # awk'/rs$/{imprimer}' /etc/hosts.
Il permet de prendre le caractère qui le suit comme un littéral c'est-à-dire de le considérer tel qu'il est.
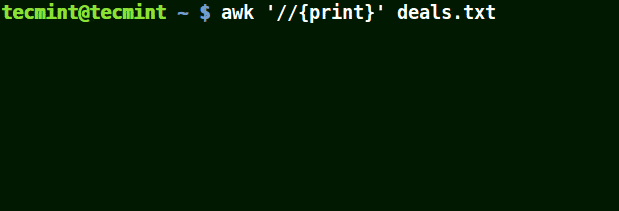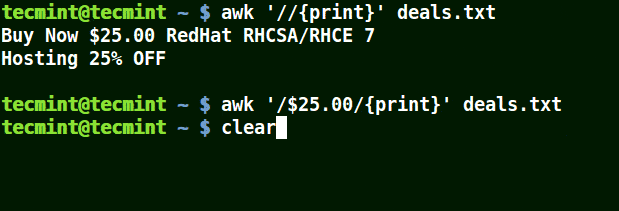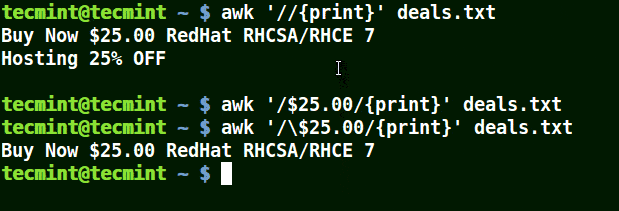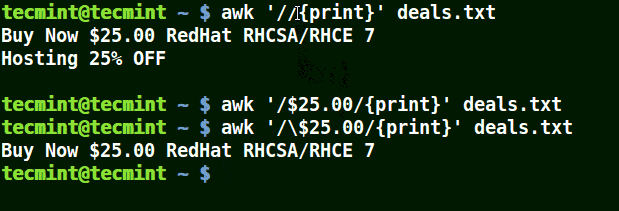
Dans l'exemple ci-dessous, la première commande imprime toutes les lignes du fichier, la deuxième commande n'affiche rien car je veux faire correspondre une ligne qui a $25.00, mais aucun caractère d'échappement n'est utilisé.
La troisième commande est correcte car un caractère d'échappement a été utilisé pour lire $ tel quel.
# awk'//{imprimer}' deals.txt. # awk'/$25.00/{imprimer}' deals.txt. # awk'/\$25.00/{imprimer}' deals.txt.
Ce n'est pas tout avec le ok outil de filtrage de ligne de commande, les exemples ci-dessus sont les opérations de base de awk. Dans les prochaines parties, nous avancerons sur la façon d'utiliser les fonctionnalités complexes de awk. Merci d'avoir lu et pour tout ajout ou clarification, postez un commentaire dans la section commentaires.