
Selle eelmistes artiklites RAID seeria läksite nullist RAID -kangelaseks. Vaatasime läbi mitmed tarkvara RAID -i konfiguratsioonid ja selgitasime igaühe põhitõdesid koos põhjustega, miks te sõltuvalt konkreetsest stsenaariumist ühe või teise poole kalduksite.

Selles juhendis käsitleme, kuidas tarkvara RAID -massiivi taastada ilma andmete kadumiseta ketta rikke korral. Lühiduse huvides kaalume ainult a RAID 1 seadistamine - kuid mõisted ja käsud kehtivad kõikidel juhtudel.
Enne jätkamist veenduge, et olete seadistanud a RAID 1 massiivi, järgides selle seeria 3. osas esitatud juhiseid: RAID 1 (peegel) seadistamine Linuxis.
Ainsad variatsioonid meie praegusel juhul on järgmised:
1) CentOSist (v7) erinev versioon, mida selles artiklis kasutati (v6.5), ja
2) erinevad ketta suurused /dev/sdb ja /dev/sdc (Igaüks 8 GB).
Lisaks, kui SELinux on jõustamisrežiimis lubatud, peate lisama vastavad sildid kataloogi, kuhu RAID -seade paigaldatakse. Vastasel juhul satute selle hoiatusteate juurde, kui proovite seda paigaldada:
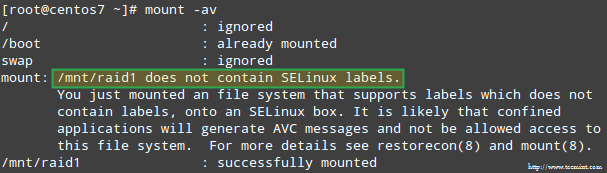
Selle saate parandada, käivitades:
# restorecon -R /mnt /raid1.
Mäluseade võib ebaõnnestuda mitmel põhjusel (SSD -d on selle tõenäosust oluliselt vähendanud), kuid olenemata põhjusest võite olla kindel, et probleeme võib tekkida igal ajal ja peate olema valmis ebaõnnestunud osa välja vahetama ning tagama oma seadme kättesaadavuse ja terviklikkuse andmed.
Kõigepealt üks nõuandev sõna. Isegi siis, kui saate kontrollida /proc/mdstat RAID-i oleku kontrollimiseks on parem ja aegasäästlikum meetod, mis koosneb töötamisest mdadm monitor + skaneerimisrežiimis, mis saadab e -posti teel teatised eelmääratud adressaadile.
Selle seadistamiseks lisage järgmine rida /etc/mdadm.conf:
MAILADDR [e -post kaitstud]
Minu puhul:
MAILADDR [e -post kaitstud]

Jooksma mdadm monitor + skaneerimisrežiimis lisage juurjuurde järgmine kirje crontab:
@reboot /sbin /mdadm --monitor --scan --oneshot.
Algselt, mdadm kontrollib RAID -massiive iga 60 sekundi järel ja saadab probleemi korral märguande. Saate seda käitumist muuta, lisades -viivitus suvandit ülaltoodud kirjele crontab koos sekundite pikkusega (näiteks -viivitus 1800 tähendab 30 minutit).
Lõpuks veenduge, et teil on a E -posti kasutajaagent (MUA) paigaldatud, näiteks mutt või mailx. Vastasel juhul ei saa te teateid.
Mõne minuti pärast näeme, millise teate saatis mdadm tundub, et.
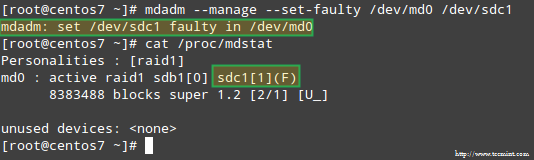
Probleemi simuleerimiseks ühe RAID -massiivi mäluseadmega kasutame -juhtimine ja -komplekt vigane valikud järgmiselt:
# mdadm --haldus-komplekt-vigane /dev /md0 /dev /sdc1
Selle tulemuseks on /dev/sdc1 on märgitud vigaseks, nagu me näeme /proc/mdstat:
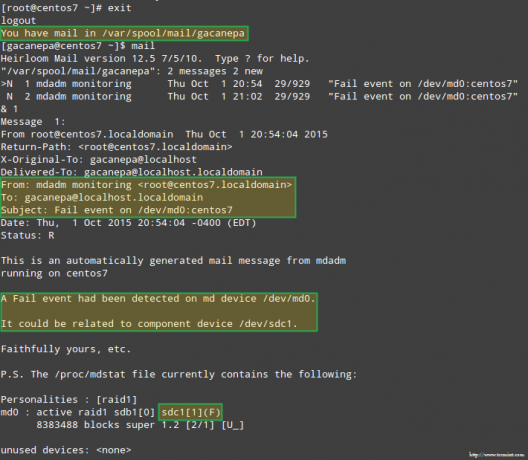
Veelgi olulisem on see, et vaatame, kas saime sama hoiatusega meiliteate:
Sel juhul peate seadme tarkvara RAID -massiivist eemaldama:
# mdadm /dev /md0 -eemaldage /dev /sdc1.
Seejärel saate selle masinalt füüsiliselt eemaldada ja asendada varuosaga (/dev/sdd, kus tüüpi sektsioon fd on varem loodud):
# mdadm --manage /dev /md0 --add /dev /sdd1.
Meie õnneks hakkab süsteem automaatselt massiivi uuesti üles ehitama just lisatud osaga. Me saame seda märgistades testida /dev/sdb1 vigane, eemaldades selle massiivist ja veendudes, et fail tecmint.txt on endiselt kättesaadav aadressil /mnt/raid1:
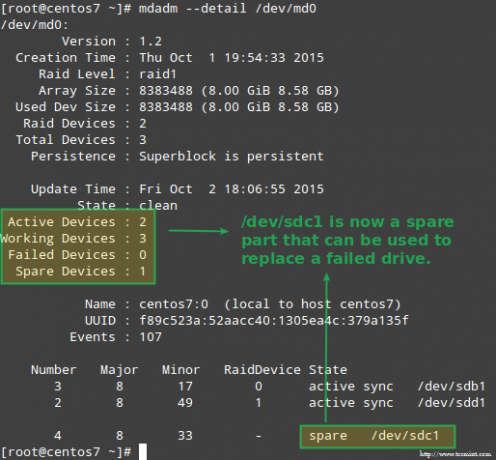
# mdadm --detail /dev /md0. # mount | grep raid1. # ls -l /mnt /raid1 | grep tecmint. # kass /mnt/raid1/tecmint.txt.
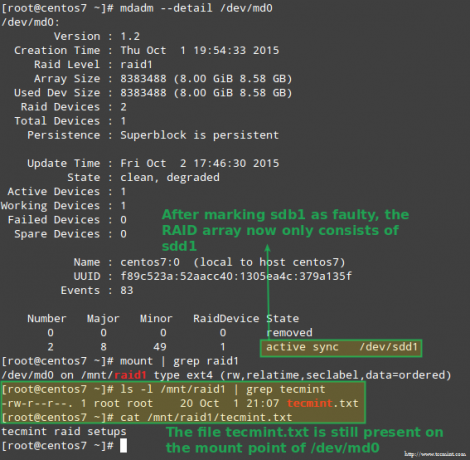
Ülaltoodud pilt näitab seda selgelt pärast lisamist /dev/sdd1 massiivi asendamiseks /dev/sdc1, süsteem teostas andmete ümberehitamise automaatselt ilma meiepoolse sekkumiseta.
Ehkki see pole rangelt nõutud, on suurepärane idee varuteade käepärast, et vigase seadme hea draiviga asendamine toimuks hetkega. Selleks lisame uuesti /dev/sdb1 ja /dev/sdc1:
# mdadm --manage /dev /md0 --add /dev /sdb1. # mdadm --manage /dev /md0 --add /dev /sdc1.
Nagu varem selgitatud, mdadm taastab andmed automaatselt, kui üks ketas ebaõnnestub. Aga mis juhtub, kui massiivi kaks ketast ebaõnnestuvad? Simuleerime sellist stsenaariumi märgistamisega /dev/sdb1 ja /dev/sdd1 nagu vigane:
# umount /mnt /raid1. # mdadm --haldus-komplekt-vigane /dev /md0 /dev /sdb1. # mdadm -peatus /dev /md0. # mdadm --haldus-komplekt-vigane /dev /md0 /dev /sdd1.
Püüab massiivi uuesti luua samal viisil, nagu see sel ajal loodi (või kasutades -eeldatavasti puhas võimalus) võib põhjustada andmete kadumise, seega tuleks see jätta viimaseks abinõuks.
Proovime andmeid taastada /dev/sdb1näiteks sarnasesse kettapartitsiooni (/dev/sde1 - pange tähele, et selleks on vaja luua tüüpi sektsioon fd sisse /dev/sde enne jätkamist) ddrescue:
# ddrescue -r 2 /dev /sdb1 /dev /sde1.
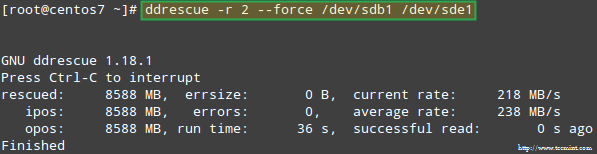
Pange tähele, et siiani pole me puudutanud /dev/sdb või /dev/sdd, partitsioonid, mis olid osa RAID -massiivist.
Nüüd ehitame massiivi uuesti üles /dev/sde1 ja /dev/sdf1:
# mdadm --loo /dev /md0-tase = peegel --raid-seadmed = 2 /dev /sd [e-f] 1.
Pange tähele, et tegelikus olukorras kasutate tavaliselt samu seadmete nimesid nagu algse massiivi puhul, st /dev/sdb1 ja /dev/sdc1 pärast ebaõnnestunud ketaste asendamist uutega.
Selles artiklis olen otsustanud kasutada lisaseadmeid massiivi uuesti loomiseks uhiuute ketastega ja vältida segadust algse ebaõnnestunud draiviga.
Kui küsitakse, kas jätkata massiivi kirjutamist, tippige Y ja vajutage Sisenema. Massiiv tuleks käivitada ja teil peaks olema võimalik jälgida selle edenemist:
# käekell -n 1 kass /proc /mdstat.
Kui protsess on lõpule jõudnud, peaks teil olema juurdepääs oma RAID -i sisule:
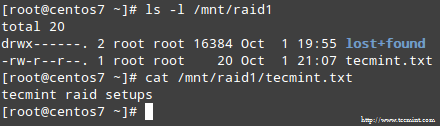
Selles artiklis vaatasime läbi, kuidas sellest taastuda RAID ebaõnnestumisi ja koondamiskaotusi. Siiski peate meeles pidama, et see tehnoloogia on salvestuslahendus ja EI OLE asendage varukoopiad.
Käesolevas juhendis selgitatud põhimõtted kehtivad ühtviisi kõigi RAID -i seadistuste kohta, samuti mõisted, mida käsitleme selle sarja järgmises ja viimases juhendis (RAID -i haldamine).
Kui teil on selle artikli kohta küsimusi, jätke meile märkus, kasutades allolevat kommentaarivormi. Ootame teie arvamust!