Wenn wir unter Unix/Linux bestimmte Befehle ausführen, um Text aus einem String oder einer Datei zu lesen oder zu bearbeiten, versuchen wir meistens, die Ausgabe nach einem bestimmten Abschnitt von Interesse zu filtern. Hier ist die Verwendung von regulären Ausdrücken praktisch.
Lesen Sie auch:10 nützliche Linux-Verkettungsoperatoren mit praktischen Beispielen
Ein regulärer Ausdruck kann als String definiert werden, der mehrere Zeichenfolgen darstellt. Eines der wichtigsten Dinge bei regulären Ausdrücken ist, dass Sie die Ausgabe eines Befehls oder einer Datei filtern, einen Abschnitt einer Text- oder Konfigurationsdatei bearbeiten und so weiter.
Reguläre Ausdrücke bestehen aus:
(.) es entspricht jedem einzelnen Zeichen außer einem Zeilenumbruch.(*) es stimmt mit null oder mehr Existenzen des unmittelbar vorangehenden Zeichens überein.[ Figuren) ] es stimmt mit einem der in Zeichen (s) angegebenen Zeichen überein, man kann auch einen Bindestrich verwenden (-) eine Reihe von Zeichen bedeuten wie [a-f], [1-5], usw.^ es entspricht dem Anfang einer Zeile in einer Datei.$ entspricht dem Zeilenende in einer Datei.\ es ist ein Escape-Zeichen.Um Text zu filtern, muss man ein Textfilter-Tool wie z awk. Sie können sich vorstellen awk als eigene Programmiersprache. Aber für den Umfang dieser Anleitung zur Verwendung awk, werden wir es als einfaches Befehlszeilen-Filterwerkzeug behandeln.
Die allgemeine Syntax von awk lautet:
# awk 'Skript'-Dateiname.
Wo 'Skript' ist eine Reihe von Befehlen, die von verstanden werden awk und werden auf Datei, Dateiname ausgeführt.
Es funktioniert, indem es eine bestimmte Zeile in der Datei liest, eine Kopie der Zeile erstellt und dann das Skript in der Zeile ausführt. Dies wird in allen Zeilen der Datei wiederholt.
Das 'Skript' ist in der form '/Muster/ Aktion' wo Muster ist ein regulärer Ausdruck und die Aktion ist, was awk tun wird, wenn es das angegebene Muster in einer Zeile findet.
In den folgenden Beispielen konzentrieren wir uns auf die Metazeichen, die wir oben unter den Merkmalen von awk besprochen haben.
Das folgende Beispiel druckt alle Zeilen in der Datei /etc/hosts da kein Muster vorgegeben ist.
# awk '//{print}'/etc/hosts.

Ich das Beispiel unten, ein Muster localhost wurde angegeben, also entspricht awk der Zeile mit localhost in dem /etc/hosts Datei.
# awk '/localhost/{print}' /etc/hosts

Das (.) findet Zeichenfolgen, die. enthalten loc, localhost, localnet im Beispiel unten.
Das heißt * l einige_single_character c *.
# awk '/l.c/{print}' /etc/hosts.

Es wird Zeichenfolgen finden, die enthalten localhost, localnet, Linien, fähig, wie im folgenden Beispiel:
# awk '/l*c/{print}' /etc/localhost.

Das wirst du auch merken (*) versucht, Ihnen die längste Übereinstimmung zu verschaffen, die es erkennen kann.
Betrachten Sie einen Fall, der dies demonstriert, nehmen Sie den regulären Ausdruck t*t was bedeutet, dass Zeichenfolgen übereinstimmen, die mit Buchstaben beginnen T und enden mit T in der Zeile unten:
Dies ist tecmint, wo Sie die besten guten Tutorials, Anleitungen, Anleitungen und tecmint erhalten.
Sie erhalten folgende Möglichkeiten, wenn Sie das Muster verwenden /t*t/:
das ist T. das ist tekmint. das ist tecmint, wo du t bekommst. Dies ist tecmint, wo Sie das beste gute t bekommen. Dies ist tecmint, wo Sie die besten guten Tutorials erhalten, wie t. Dies ist tecmint, wo Sie die besten guten Tutorials, Anleitungen, Anleitungen usw. erhalten. Dies ist tecmint, wo Sie die besten guten Tutorials, Anleitungen, Anleitungen und tecmint erhalten.
Und (*) In /t*t/ Platzhalterzeichen ermöglicht es awk, die letzte Option zu wählen:
Dies ist tecmint, wo Sie die besten guten Tutorials, Anleitungen, Anleitungen und tecmint erhalten.
Nehmen Sie zum Beispiel das Set [al1], hier wird awk mit allen Strings übereinstimmen, die Zeichen enthalten ein oder l oder 1 in einer Zeile in der Datei /etc/hosts.
# awk '/[al1]/{print}' /etc/hosts.

Das nächste Beispiel entspricht Strings, die mit entweder. beginnen K oder k gefolgt von T:
# awk '/[Kk]T/{print}' /etc/hosts

Zeichen mit awk verstehen:
[0-9] bedeutet eine einzelne Zahl[a-z] bedeutet, dass ein einzelner Kleinbuchstabe übereinstimmt[A-Z] bedeutet, dass ein einzelner Großbuchstabe übereinstimmt[a-zA-Z] bedeutet, dass ein einzelner Buchstabe übereinstimmt[a-zA-Z 0-9] bedeutet Übereinstimmung mit einem einzelnen Buchstaben oder einer ZahlSchauen wir uns unten ein Beispiel an:
# awk '/[0-9]/{print}' /etc/hosts
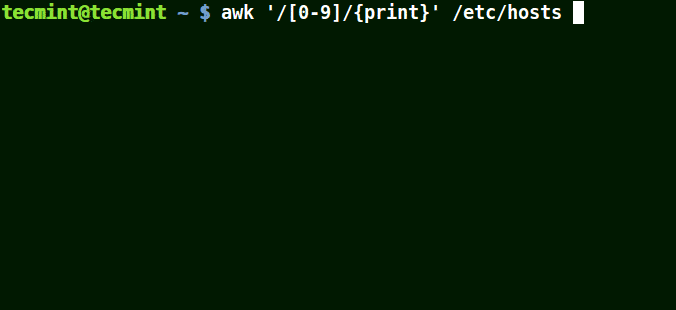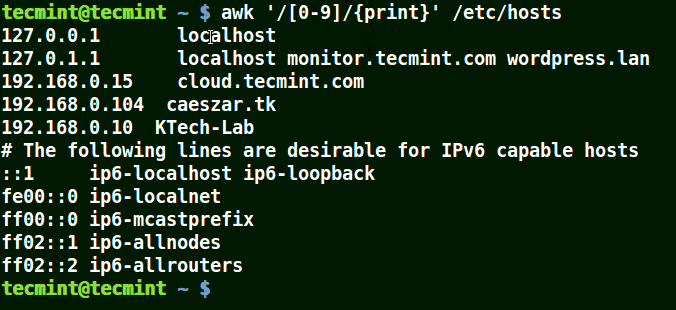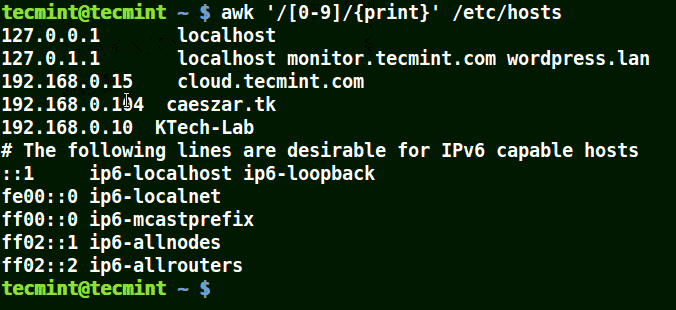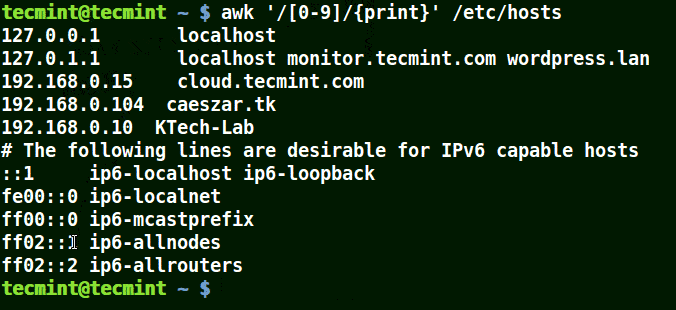
Die ganze Zeile aus der Datei /etc/hosts enthalten mindestens eine einzelne Zahl [0-9] im obigen Beispiel.
Es stimmt mit allen Zeilen überein, die mit dem Muster beginnen, das wie im folgenden Beispiel bereitgestellt wird:
# awk '/^fe/{print}' /etc/hosts. # awk '/^ff/{print}' /etc/hosts.

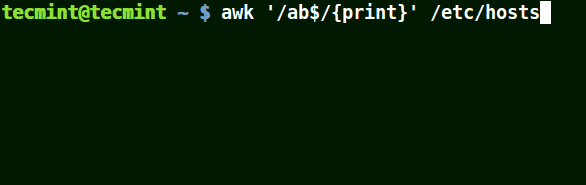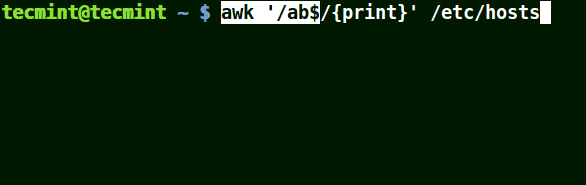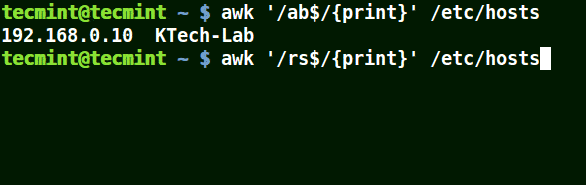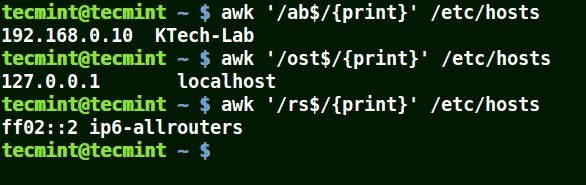
Es stimmt mit allen Zeilen überein, die mit dem bereitgestellten Muster enden:
# awk '/ab$/{print}' /etc/hosts. # awk '/ost$/{print}' /etc/hosts. # awk '/rs$/{print}' /etc/hosts.
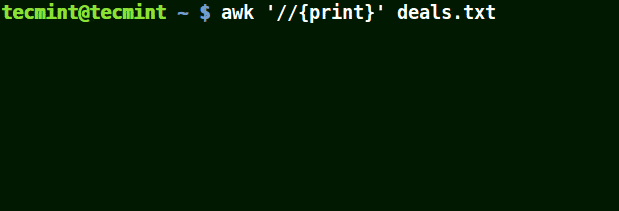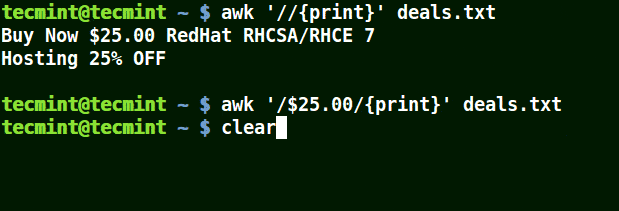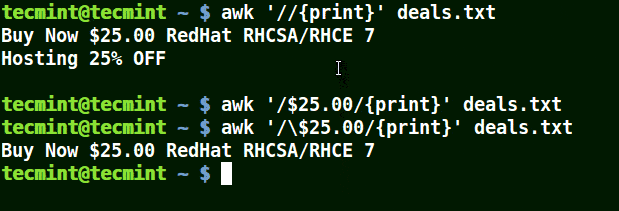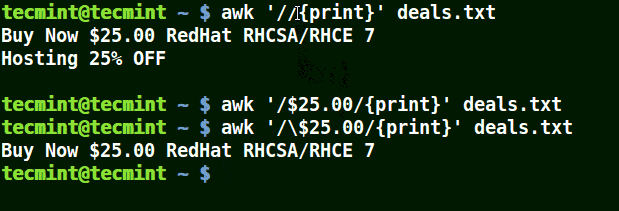
Es ermöglicht Ihnen, das darauf folgende Zeichen wörtlich zu nehmen, dh es so zu betrachten, wie es ist.
Im folgenden Beispiel druckt der erste Befehl alle Zeilen in der Datei aus, der zweite Befehl gibt nichts aus, weil ich eine Zeile abgleichen möchte, die hat $25.00, aber es wird kein Escape-Zeichen verwendet.
Der dritte Befehl ist korrekt, da ein Escape-Zeichen zum Lesen verwendet wurde $ wie es ist.
# awk '//{print}' deal.txt. # awk '/$25.00/{print}' deal.txt. # awk '/\$25.00/{print}' deal.txt.
Das ist nicht alles mit dem awk Befehlszeilen-Filtertool, die obigen Beispiele und die grundlegenden Operationen von awk. In den nächsten Teilen werden wir die Verwendung komplexer Funktionen von awk vorantreiben. Vielen Dank fürs Durchlesen und für Ergänzungen oder Klarstellungen, posten Sie einen Kommentar im Kommentarbereich.