Apache Hadoop ist ein Open-Source-Framework für die verteilte Speicherung von Big Data und die Verarbeitung von Daten über Computercluster hinweg. Das Projekt basiert auf folgenden Komponenten:

In diesem Artikel erfahren Sie, wie Sie Apache Hadoop auf einem Single-Node-Cluster in. installieren CentOS 7 (funktioniert auch für RHEL 7 und Fedora 23+ Versionen). Diese Art der Konfiguration wird auch als. bezeichnet Pseudoverteilter Hadoop-Modus.
1. Bevor Sie mit der Java-Installation fortfahren, melden Sie sich zuerst mit dem Root-Benutzer oder einem Benutzer mit Root-Rechten an, richten Sie Ihren Rechner-Hostnamen mit dem folgenden Befehl ein.
# hostnamectl set-hostname master.
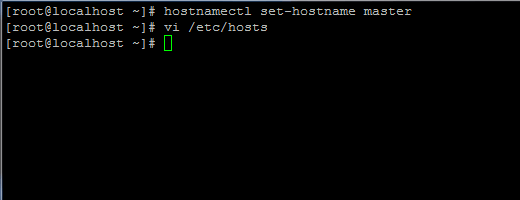
Fügen Sie außerdem einen neuen Datensatz in der Hosts-Datei mit Ihrem eigenen Computer-FQDN hinzu, um auf Ihre System-IP-Adresse zu verweisen.
# vi /etc/hosts.
Fügen Sie die folgende Zeile hinzu:
192.168.1.41 master.hadoop.lan.

Ersetzen Sie die obigen Hostnamen- und FQDN-Einträge durch Ihre eigenen Einstellungen.
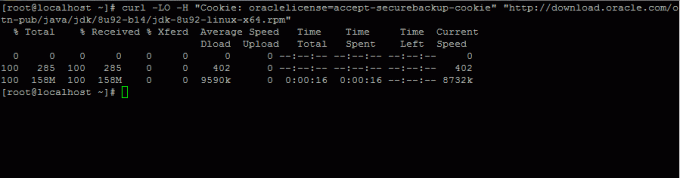
2. Als nächstes gehen Sie zu Oracle Java-Download Seite und holen Sie sich die neueste Version von Java SE-Entwicklungskit 8 auf Ihrem System mit Hilfe von Locken Befehl:
# curl -LO -H "Cookie: oraclelicense=accept-securebackup-cookie" “ http://download.oracle.com/otn-pub/java/jdk/8u92-b14/jdk-8u92-linux-x64.rpm”
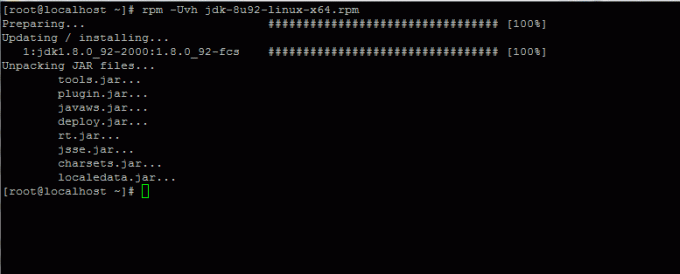
3. Nachdem der Java-Binärdownload abgeschlossen ist, installieren Sie das Paket, indem Sie den folgenden Befehl ausführen:
# rpm -Uvh jdk-8u92-linux-x64.rpm.
4. Erstellen Sie als Nächstes ein neues Benutzerkonto auf Ihrem System ohne Root-Berechtigungen, das wir für den Hadoop-Installationspfad und die Arbeitsumgebung verwenden. Das neue Home-Verzeichnis des Kontos befindet sich in /opt/hadoop Verzeichnis.
# useradd -d /opt/hadoop hadoop. # passwd hadoop.
5. Im nächsten Schritt besuchen Apache Hadoop Seite, um den Link für die neueste stabile Version zu erhalten und das Archiv auf Ihr System herunterzuladen.
# curl -O http://apache.javapipe.com/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz

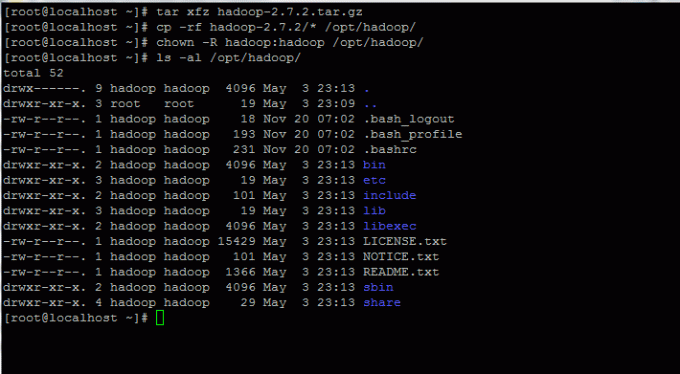
6. Entpacken Sie das Archiv und kopieren Sie den Inhalt des Verzeichnisses in den Home-Pfad des Hadoop-Kontos. Stellen Sie außerdem sicher, dass Sie die Berechtigungen für kopierte Dateien entsprechend ändern.
# tar xfz hadoop-2.7.2.tar.gz. # cp -rf hadoop-2.7.2/* /opt/hadoop/ # chown -R hadoop: hadoop /opt/hadoop/
7. Als nächstes melden Sie sich mit an hadoop Benutzer und konfigurieren Hadoop und Java-Umgebungsvariablen auf Ihrem System, indem Sie die .bash_profile Datei.
# su - Hadoop. $ vi .bash_profile.
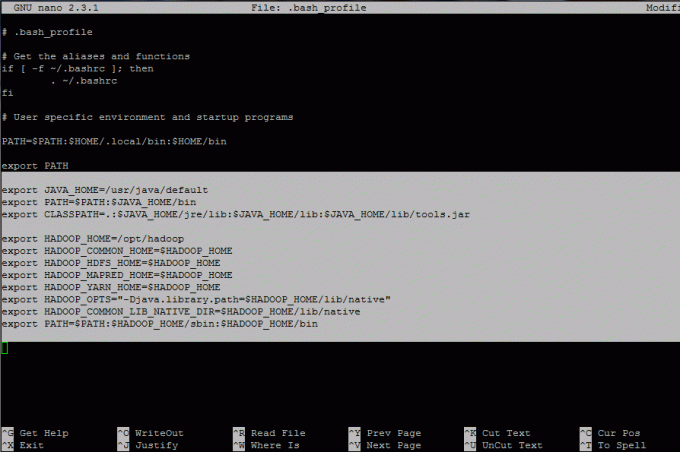
Hängen Sie am Ende der Datei folgende Zeilen an:
## JAVA-Umgebungsvariablen export JAVA_HOME=/usr/java/default. export PFAD=$PFAD:$JAVA_HOME/bin. export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar ## HADOOP-Umgebungsvariablenexport HADOOP_HOME=/opt/hadoop. export HADOOP_COMMON_HOME=$HADOOP_HOME. export HADOOP_HDFS_HOME=$HADOOP_HOME. exportiere HADOOP_MAPRED_HOME=$HADOOP_HOME. exportiere HADOOP_YARN_HOME=$HADOOP_HOME. export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native. export PFAD=$PFAD:$HADOOP_HOME/sbin:$HADOOP_HOME/bin.
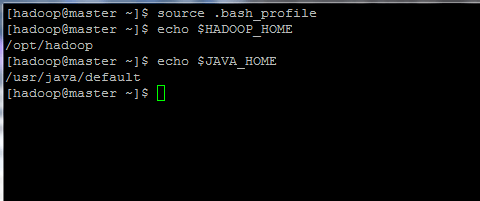
8. Initialisieren Sie nun die Umgebungsvariablen und überprüfen Sie ihren Status, indem Sie die folgenden Befehle ausführen:
$ source .bash_profile. $ echo $HADOOP_HOME. $ echo $JAVA_HOME.
9. Konfigurieren Sie schließlich die ssh-schlüsselbasierte Authentifizierung für hadoop Konto, indem Sie die folgenden Befehle ausführen (ersetzen Sie die Hostname oder FQDN gegen das ssh-copy-id Befehl entsprechend).
Lassen Sie auch die Passphrase leer abgelegt, um sich automatisch per ssh anzumelden.
$ ssh-keygen -t rsa. $ ssh-copy-id master.hadoop.lan.


