
V předchozích článcích tohoto Série RAID přešli jste z nuly na hrdinu RAID. Zkontrolovali jsme několik softwarových konfigurací RAID a vysvětlili jsme základy každé z nich spolu s důvody, proč byste se přikláněli k jedné nebo druhé v závislosti na vašem konkrétním scénáři.

V této příručce budeme diskutovat o tom, jak v případě selhání disku obnovit softwarové pole RAID bez ztráty dat. Pro stručnost budeme zvažovat pouze a RAID 1 nastavení - ale koncepty a příkazy platí pro všechny případy stejně.
Než budete pokračovat, ujistěte se, že jste nastavili a RAID 1 pole podle pokynů uvedených v části 3 této série: Jak nastavit RAID 1 (Mirror) v Linuxu.
Jediné varianty v našem současném případě budou:
1) jinou verzi CentOS (v7) než tu, která byla použita v tomto článku (v6.5), a
2) různé velikosti disků pro /dev/sdb a /dev/sdc (8 GB každý).
Navíc pokud SELinux je povolena v režimu vynucování, budete muset přidat odpovídající štítky do adresáře, kam připojíte zařízení RAID. Jinak se vám při pokusu o připojení zobrazí tato varovná zpráva:
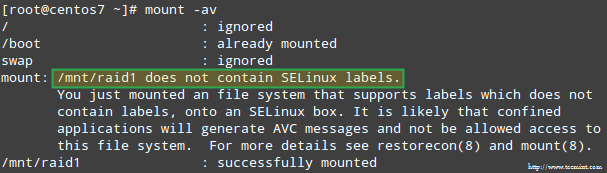
Můžete to opravit spuštěním:
# restorecon -R /mnt /raid1.
Existuje celá řada důvodů, proč může úložné zařízení selhat (disky SSD však výrazně snížily pravděpodobnost, že k tomu dojde), ale bez ohledu na příčinu můžete si být jisti, že problémy mohou nastat kdykoli, a musíte být připraveni vyměnit vadnou součást a zajistit dostupnost a integritu vašeho data.
Nejprve rada. I když můžete kontrolovat /proc/mdstat Aby bylo možné zkontrolovat stav vašich RAIDů, existuje lepší a časově úspornější metoda, která spočívá v běhu mdadm v režimu monitor + skenování, které bude odesílat upozornění e -mailem na předem definovaného příjemce.
Chcete -li to nastavit, přidejte do něj následující řádek /etc/mdadm.conf:
MAILADDR [chráněno emailem]
V mém případě:
MAILADDR [chráněno emailem]

Běžet mdadm v režimu monitor + skenování přidejte následující položku crontab jako root:
@reboot /sbin /mdadm --monitor --scan --oneshot.
Ve výchozím stavu, mdadm zkontroluje pole RAID každých 60 sekund a pošle upozornění, pokud zjistí problém. Toto chování můžete upravit přidáním souboru --zpoždění možnost výše uvedeného záznamu crontab spolu s počtem sekund (např. --zpoždění 1800 znamená 30 minut).
Nakonec se ujistěte, že máte a Mail User Agent (MUA) nainstalován, jako například mutt nebo mailx. V opačném případě nebudete dostávat žádná upozornění.
Za minutu uvidíme, jaké upozornění odeslal mdadm vypadá jako.
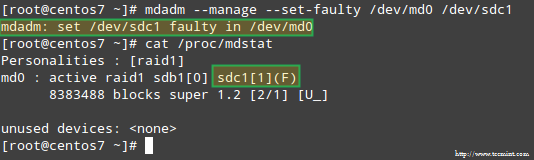
K simulaci problému s jedním z úložných zařízení v poli RAID použijeme --spravovat a --set-vadný možnosti následovně:
# mdadm --manage --set-faulty /dev /md0 /dev /sdc1
Výsledkem bude /dev/sdc1 jsou označeny jako vadné, jak vidíme v /proc/mdstat:
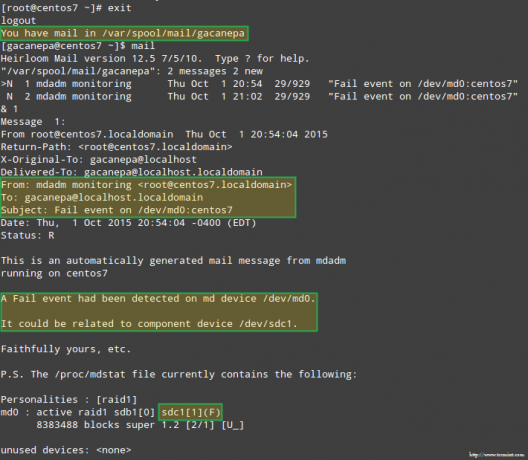
Ještě důležitější je zjistit, zda jsme obdrželi e -mailové upozornění se stejným upozorněním:
V takovém případě budete muset zařízení odebrat ze softwarového pole RAID:
# mdadm /dev /md0 -remove /dev /sdc1.
Poté jej můžete fyzicky odebrat ze stroje a nahradit jej náhradním dílem (/dev/sdd, kde je typový oddíl fd byl dříve vytvořen):
# mdadm --manage /dev /md0 --add /dev /sdd1.
Naštěstí pro nás systém automaticky začne znovu sestavovat pole s částí, kterou jsme právě přidali. Můžeme to vyzkoušet označením /dev/sdb1 jako vadný, odstraníte jej z pole a ujistíte se, že soubor tecmint.txt je stále přístupný na adrese /mnt/raid1:
# mdadm --detail /dev /md0. # mount | grep raid1. # ls -l /mnt /raid1 | grep tecmint. # kočka /mnt/raid1/tecmint.txt.
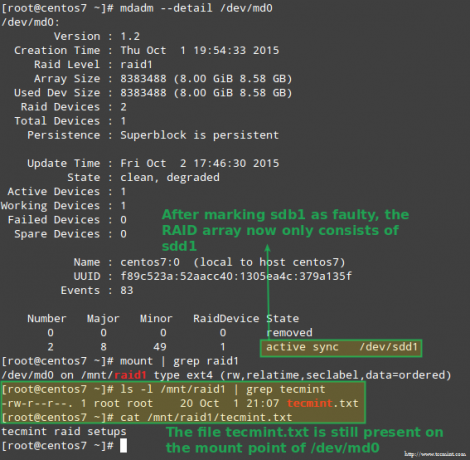
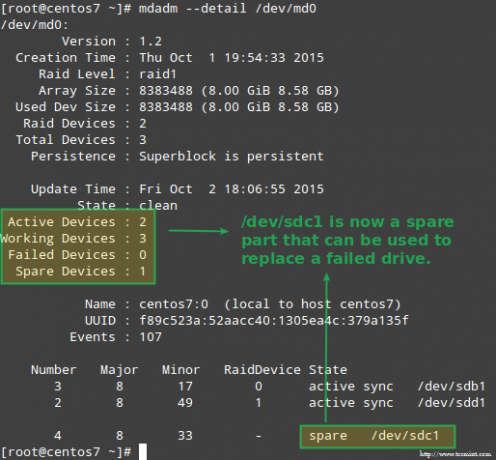
Obrázek výše to jasně ukazuje po přidání /dev/sdd1 do pole jako náhrada za /dev/sdc1, obnovu systému automaticky provedl systém bez zásahu z naší strany.
I když to není striktně vyžadováno, je skvělé mít po ruce náhradní zařízení, aby bylo možné proces výměny vadného zařízení za dobrý disk provést rychle. Chcete-li to provést, přidáme znovu /dev/sdb1 a /dev/sdc1:
# mdadm --manage /dev /md0 --add /dev /sdb1. # mdadm --manage /dev /md0 --add /dev /sdc1.
Jak již bylo vysvětleno dříve, mdadm automaticky selže data, když jeden disk selže. Co se ale stane, když 2 disky v poli selžou? Simulujme takový scénář označením /dev/sdb1 a /dev/sdd1 jako vadný:
# umount /mnt /raid1. # mdadm --manage --set-faulty /dev /md0 /dev /sdb1. # mdadm -stop /dev /md0. # mdadm --manage --set-faulty /dev /md0 /dev /sdd1.
Pokusí se znovu vytvořit pole stejným způsobem, jakým bylo vytvořeno v tuto chvíli (nebo pomocí -vyčistit možnost) může mít za následek ztrátu dat, takže by mělo být ponecháno jako poslední možnost.
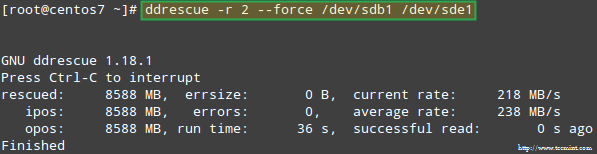
Pokusme se obnovit data z /dev/sdb1například do podobného diskového oddílu (/dev/sde1 - Všimněte si, že to vyžaduje, abyste vytvořili typový oddíl fd v /dev/sde než budete pokračovat) pomocí ddrescue:
# ddrescue -r 2 /dev /sdb1 /dev /sde1.
Vezměte prosím na vědomí, že až do tohoto okamžiku jsme se nedotkli /dev/sdb nebo /dev/sdd, oddíly, které byly součástí pole RAID.
Nyní znovu sestavíme pole pomocí /dev/sde1 a /dev/sdf1:
# mdadm --create /dev /md0 --level = mirror --raid-devices = 2 /dev /sd [e-f] 1.
Vezměte prosím na vědomí, že ve skutečné situaci budete obvykle používat stejná jména zařízení jako u původního pole, tj. /dev/sdb1 a /dev/sdc1 poté, co byly poškozené disky nahrazeny novými.
V tomto článku jsem se rozhodl použít další zařízení k opětovnému vytvoření pole se zbrusu novými disky a aby nedošlo k záměně s původními selhanými jednotkami.
Na dotaz, zda pokračovat v psaní pole, zadejte Y a stiskněte Vstupte. Pole by mělo být spuštěno a měli byste být schopni sledovat jeho průběh pomocí:
# hodinky -n 1 kočka /proc /mdstat.
Po dokončení procesu byste měli mít přístup k obsahu svého pole RAID:
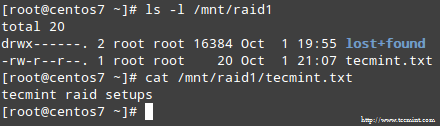
V tomto článku jsme zkontrolovali, jak se z něj zotavit NÁLET selhání a ztráty redundance. Musíte však mít na paměti, že tato technologie je řešením úložiště a NENÍ nahradit zálohy.
Principy vysvětlené v této příručce platí pro všechna nastavení RAID stejně, stejně jako koncepty, kterým se budeme věnovat v další a závěrečné příručce této řady (správa RAID).
Pokud máte nějaké dotazy k tomuto článku, neváhejte nám napsat poznámku pomocí níže uvedeného formuláře pro komentář. Těšíme se na setkání s Vámi!

