
Като потребители на Linux, ние взаимодействаме с текстовите файлове редовно. Една от обичайните операции, които извършваме с тези файлове, е филтриране на текст. Linux предоставя много помощни програми от командния ред за филтриране на текст, като – grep, fgrep, сед, awk, и списъкът продължава.
В това ръководство обаче ще обсъдим още една помощна програма за филтриране на текст, наречена разрез, който се използва за премахване на определена секция от входния ред. Командата за изрязване извършва филтриране въз основа на позицията на байта, знака, полето и разделителя.
В това ръководство за начинаещи ще научим за команда за изрязване с примери в командния ред на Linux. След като следват това ръководство, потребителите на командния ред на Linux ще могат да използват ефективно командата cut в ежедневието си.
Синтаксисът на команда за изрязване е точно като всеки друга Linux команда:
$ намаление... [ФАЙЛ-1] [ФАЙЛ-2]...
В горния синтаксис ъгловата скоба (<>) представлява задължителните аргументи, докато квадратната скоба ([]) представлява незадължителните параметри.
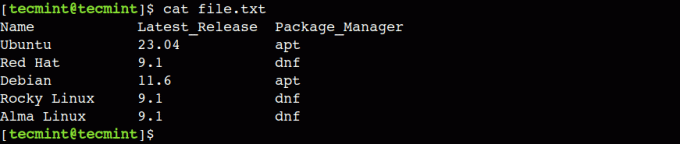
Сега, след като сме запознати със синтаксиса на команда за изрязване. След това нека създадем примерен файл, който да използваме като пример:
$ cat file.txt.
The разрез команда ни позволява да извлечем текста въз основа на позицията на байта, използвайки -б опция.
Нека използваме командата по-долу, за да извлечем първия байт от всеки ред на файла:
$ cut -b 1 файл.txt.
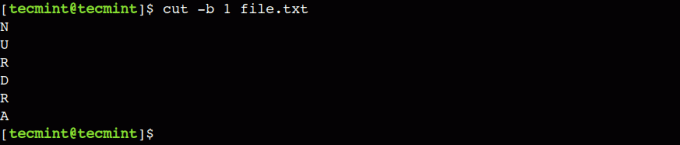
В този пример можем да видим, че разрез командата показва само първия знак, тъй като всички знаци са дълги един байт.
В предишния пример видяхме как да изберете един байт от файла. Въпреки това, командата cut също ни позволява да избираме множество байтове с помощта на запетаята.
Нека използваме командата по-долу, за да изберем първите четири байта от файла:
$ cut -b 1,2,3,4 file.txt.
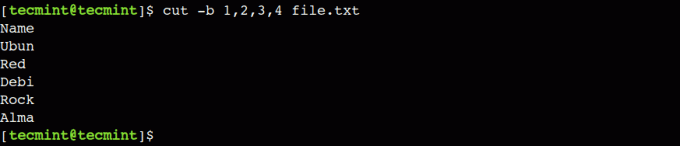
В този пример сме избрали последователните байтове, но това не е задължително. Можем да използваме всяка валидна байтова позиция с разрез команда.
В предишния пример използвахме запетаи, за да изберете последователни байтове. Този подход обаче не е подходящ, ако искаме да изберем голям брой байтове последователно. В такива случаи можем да използваме тирето (-) за да укажете диапазона от байтове.
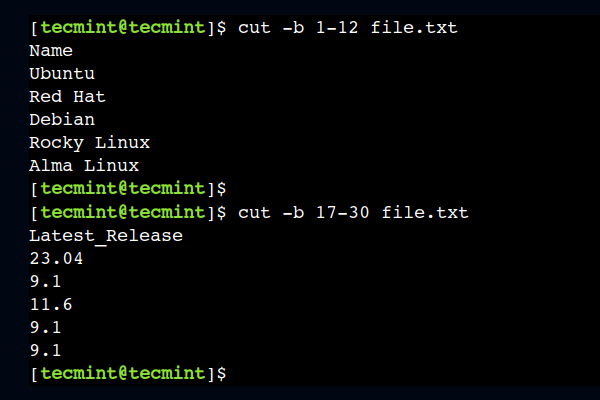
За да разберем това, нека използваме 1-12 като диапазон от байтове, за да изберете първите дванадесет байта от всеки ред:
$ cut -b 1-12 file.txt.
По подобен начин можем да изберем диапазон от байтове и от средата. Например командата по-долу избира байтове от колони с номера от 17 до 30:
$ cut -b 17-30 file.txt.
Понякога искаме да извлечем целия текст от определена байтова позиция. В такива случаи можем да пропуснем позицията на крайния байт.
Например, можем да използваме следната команда, за да отпечатаме всички байтове, започвайки от позиция 17:
$ cut -b 17- file.txt

В горната команда 17 представлява позицията на началния байт, докато тирето (-) представлява края на реда.
По подобен начин можем също да посочим само позицията на крайния байт. Например командата по-долу отпечатва всички байтове от началото на реда до 12-та колона:
$ cut -b -12 файл.txt.
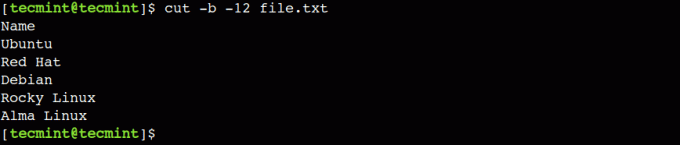
В горната команда тирето (-) представлява началото на реда, докато 12 представлява позицията на крайния байт.
В последните няколко раздела видяхме как да извършим извличане на текст въз основа на позиция на байт. Сега нека видим как да извършим извличането на текст по позиция на символа.
За да постигнем това, можем да използваме -° С опция за изрязване на първия байт от следния многобайтов низ:
$ echo école | изрежете -b 1.
В горния резултат можем да видим, че командата за изрязване показва въпросителен знак вместо знака é. Това се случва, защото се опитваме да отпечатаме първия байт от многобайтовия знак.
Сега нека използваме -° С опция за изрязване на същия многобайтов знак и наблюдение на резултата:
$ echo école | изрежете -c 1 é
В горния изход можем да видим, че сега командата cut показва очаквания изход.
Важно е да се отбележи, че не всички версии на командите за изрязване поддържат многобайтови знаци. Например, Ubuntu и неговите производни не поддържат многобайтови знаци.
За да разберем това, нека изпълним същата команда на Linux Mint който се извлича от Ubuntu:

Тук можем да видим това, разрез командата третира еднакво многобайтовите и еднобайтовите знаци. Следователно не генерира очаквания резултат.
По подразбиране, разрез командата използва a РАЗДЕЛ символ като разделител. Въпреки това можем да отменим това поведение по подразбиране с помощта на -д опция.
Често пъти, -д опция се използва в комбинация с -f опция, която се използва за избор на конкретно поле.
За да разберем това, нека използваме знака за интервал като разделител и отпечатаме първите две полета с помощта на -f опция:
$ cut -d " " -f 1,2 file.txt.
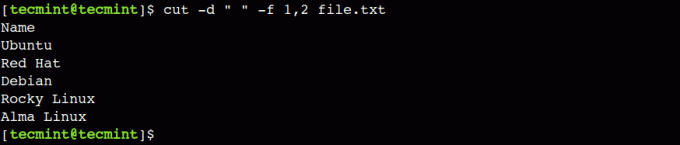
В горния пример сме използвали запетаята с -f опция за избор на множество полета.
Понякога искаме да отпечатаме всички символи с изключение на няколко. В такива случаи можем да използваме --допълнение опция. Както подсказва името, тази опция отпечатва всички колони с изключение на посочените.
$ cut -c 1 --complement file.txt.
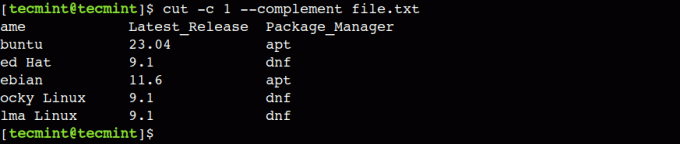
В горния резултат можем да видим, че --допълнение опцията отпечатва всички символи с изключение на първия знак.
Важно е да се отбележи, че в този пример сме използвали запетаи, за да изберете множество полета. Въпреки това можем да използваме и другите поддържани диапазони. Можем да се позовем на първите няколко примера от този урок, за да разберем повече за диапазоните.
В това ръководство за начинаещи обсъдихме практическите примери за разрез команда с филтриране на текст въз основа на позицията на байта, позицията на символа и разделителя.
Знаете ли за някой друг най-добър пример за командата cut в Linux? Кажете ни вашето мнение в коментарите по-долу.
