Apache Spark -це розподілена обчислювальна база з відкритим вихідним кодом, створена для забезпечення більш швидких обчислювальних результатів. Це обчислювальний механізм в пам'яті, тобто дані будуть оброблятися в пам'яті.
Іскра підтримує різні API для потокової передачі, обробки графіків, SQL, MLLib. Він також підтримує Java, Python, Scala та R як бажані мови. Spark в основному встановлюється в Кластери Hadoop але ви також можете встановити та налаштувати spark в автономному режимі.
У цій статті ми розглянемо, як встановити Apache Spark в Debian та Ubuntu-розподіли на основі.
Для встановлення Apache Spark в Ubuntu, ви повинні мати Java та Scala встановлено на вашій машині. Більшість сучасних дистрибутивів за замовчуванням встановлено Java, і ви можете перевірити це за допомогою наведеної нижче команди.
$ java -версія.

Якщо виводу немає, ви можете встановити Java за допомогою нашої статті як встановити Java на Ubuntu або просто виконайте наведені нижче команди, щоб встановити Java на дистрибутивах на основі Ubuntu та Debian.
$ sudo apt update. $ sudo apt install default-jre. $ java -версія.

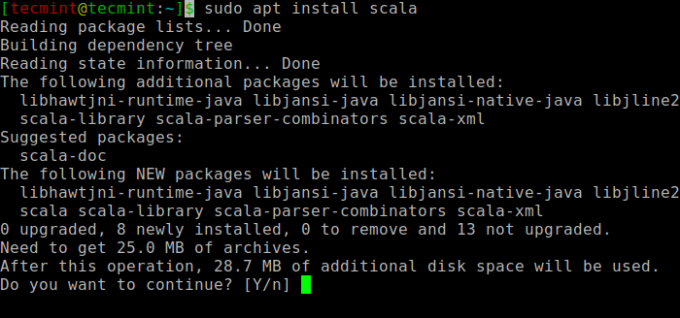
Далі можна встановити Scala зі сховища apt, виконавши наступні команди для пошуку scala та встановлення його.
$ sudo apt search scala ⇒ Знайдіть пакет. $ sudo apt install scala ⇒ Встановіть пакет.
Щоб перевірити установку Scala, виконайте таку команду.
$ scala -версія Версія сканера коду Scala 2.11.12-Авторське право 2002-2017, LAMP/EPFL
Тепер перейдіть до офіційного Сторінка завантаження Apache Spark і завантажте останню версію (тобто 3.1.1) на момент написання цієї статті. Крім того, ви можете використовувати команда wget завантажити файл безпосередньо в терміналі.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz.
Тепер відкрийте свій термінал і перейдіть до місця, де розміщено завантажений файл, і виконайте таку команду, щоб витягти файл tar Apache Spark.
$ tar -xvzf spark-3.1.1-bin-hadoop2.7.tgz.
Нарешті, перемістіть витягнуте Іскра каталог до /opt каталог.
$ sudo mv spark-3.1.1-bin-hadoop2.7 /opt /spark.
Тепер ви повинні встановити кілька змінних середовища у своєму .профіль файл перед запуском іскри.
$ echo "експортувати SPARK_HOME =/opt/spark" >> ~/.profile. $ echo "ШЛЯХ експорту = $ PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile. $ echo "експорт PYSPARK_PYTHON =/usr/bin/python3" >> ~/.profile.
Щоб переконатися, що ці нові змінні середовища доступні в оболонці і доступні для Apache Spark, також необхідно виконати таку команду, щоб ввести останні зміни в дію.
$ source ~/.profile.
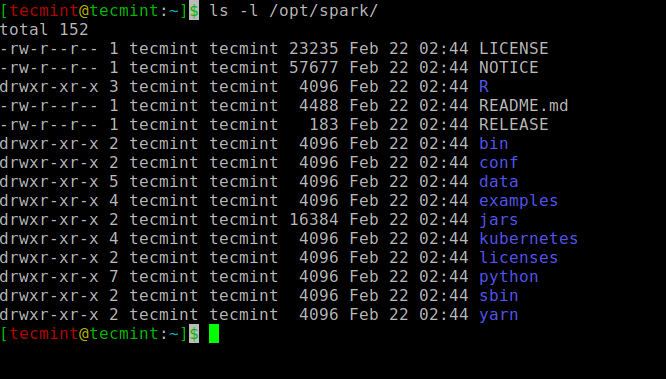
Усі двійкові файли, пов'язані з іскрою, для запуску та зупинки служб знаходяться під sbin папку.
$ ls -l /opt /spark.
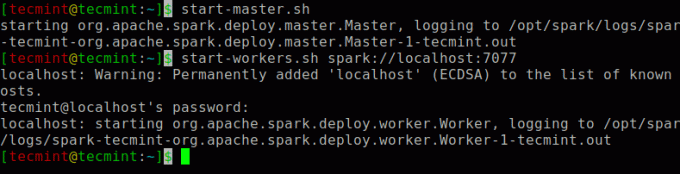
Виконайте таку команду, щоб запустити Іскра майстер -служба та служба рабів.
$ start-master.sh. $ start-workers.sh spark: // localhost: 7077.
Після запуску служби перейдіть до веб -переглядача та введіть наступну сторінку доступу до URL -адреси. На цій сторінці ви можете побачити, як запущено мою службу господаря та підлеглих.
http://localhost: 8080/ АБО. http://127.0.0.1:8080.

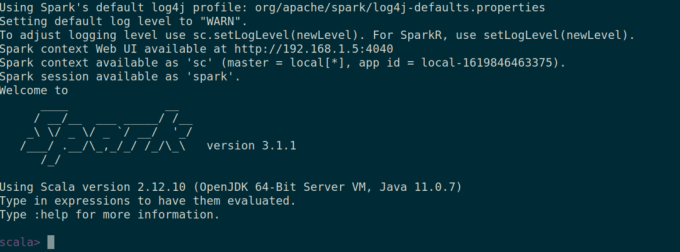
Ви також можете перевірити, чи так іскра-оболонка працює добре, запустивши іскра-оболонка команду.
$ іскра-оболонка.
Ось і все для цієї статті. Незабаром ми зустрінемо вас з іншою цікавою статтею.

