У претходним чланцима овога РАИД серија прешли сте са нуле на РАИД хероја. Прегледали смо неколико софтверских РАИД конфигурација и објаснили основе сваке од њих, заједно са разлозима зашто бисте се приклонили једном или другом у зависности од вашег специфичног сценарија.

У овом водичу ћемо расправљати о томе како обновити софтверски РАИД низ без губитка података у случају квара диска. Ради сажетости, размотрићемо само а РАИД 1 сетуп - али концепти и команде се примењују на све случајеве.
Пре него што наставите, проверите да ли сте подесили а РАИД 1 низ пратећи упутства дата у 3. делу ове серије: Како поставити РАИД 1 (Миррор) у Линуку.
Једине варијације у нашем садашњем случају биће:
1) другачију верзију ЦентОС -а (в7) од оне која се користи у том чланку (в6.5), и
2) различите величине диска за /dev/sdb и /dev/sdc (По 8 ГБ).
Осим тога, ако СЕЛинук је омогућен у режиму спровођења, мораћете да додате одговарајуће ознаке у директоријум у који ћете монтирати РАИД уређај. У супротном ћете наићи на ову поруку упозорења док покушавате да је монтирате:
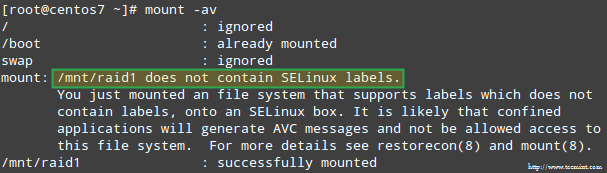
То можете поправити покретањем:
# ресторецон -Р /мнт /раид1.
Постоје различити разлози зашто уређај за складиштење може да откаже (ССД -ови су ипак значајно смањили шансе да се то догоди), али без обзира на узрок можете бити сигурни да се проблеми могу појавити у било ком тренутку и морате бити спремни да замените неуспели део и да обезбедите доступност и интегритет вашег података.
Прво један савет. Чак и када можете да прегледате /proc/mdstat да бисте проверили статус ваших РАИД-ова, постоји бољи начин који штеди време и састоји се од покретања мдадм у режиму монитора + скенирања, који ће слати упозорења путем е -поште унапред дефинисаном примаоцу.
Да бисте ово подесили, додајте следећи ред /etc/mdadm.conf:
МАИЛАДДР [заштићена е -пошта]
У мом случају:
МАИЛАДДР [заштићена е -пошта]

Трчати мдадм у режиму монитора + скенирања, додајте следећи цронтаб унос као роот:
@ребоот /сбин /мдадм --монитор --сцан --онесхот.
Подразумевано, мдадм провераваће низове РАИД -а сваких 60 секунди и слати упозорење ако открије проблем. Ово понашање можете изменити додавањем --одлагање опцију за горњи унос цронтаба заједно са количином секунди (на пример, --одлагање 1800 значи 30 минута).
На крају, уверите се да имате Кориснички агент поште (МУА) инсталиран, као што је мутт или маилк. У супротном нећете добити никаква упозорења.
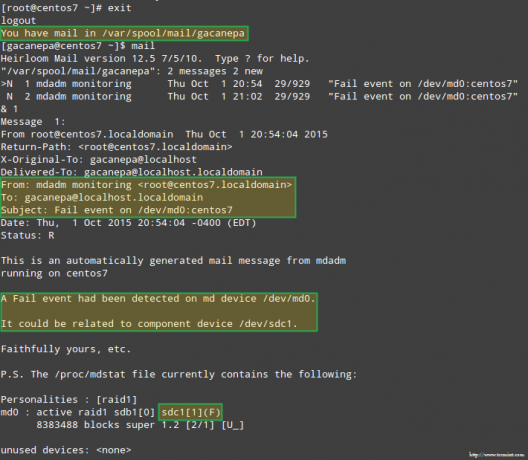
За минут ћемо видети какво је упозорење послало мдадм Изгледа.
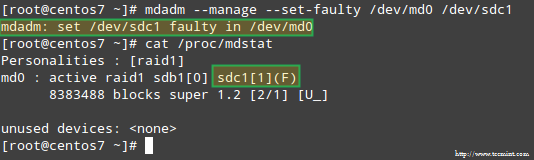
Да бисмо симулирали проблем са једним од уређаја за складиштење у низу РАИД, користићемо --управљати и -сет-неисправан следеће опције:
# мдадм --манаге --сет-фаулти /дев /мд0 /дев /сдц1
Ово ће резултирати /dev/sdc1 означени као неисправни, као што видимо у /proc/mdstat:
Још важније, да видимо да ли смо примили упозорење путем е -поште са истим упозорењем:
У овом случају морате да уклоните уређај из софтверског РАИД низа:
# мдадм /дев /мд0 --ремове /дев /сдц1.
Тада га можете физички уклонити из машине и заменити резервним делом (/dev/sdd, где је партиција типа фд је претходно креиран):
# мдадм --манаге /дев /мд0 --адд /дев /сдд1.
На нашу срећу, систем ће аутоматски започети поновну изградњу низа са делом који смо управо додали. Ово можемо тестирати означавањем /dev/sdb1 као неисправан, уклоните га из низа и уверите се да је датотека тецминт.ткт још увек је доступна на адреси /mnt/raid1:
# мдадм --детаил /дев /мд0. # моунт | греп раид1. # лс -л /мнт /раид1 | греп тецминт. # цат /мнт/раид1/тецминт.ткт.
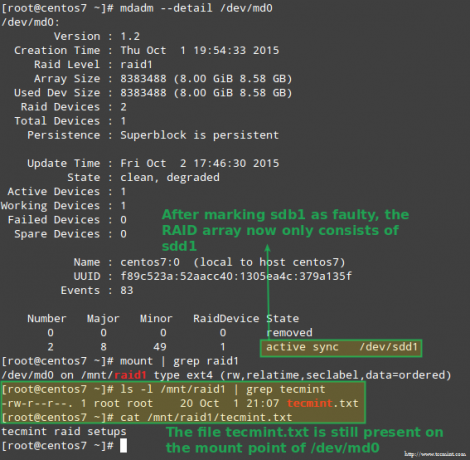
Горња слика јасно показује да након додавања /dev/sdd1 у низ као замена за /dev/sdc1, систем је аутоматски извршио поновну изградњу података без наше интервенције.
Иако то није стриктно потребно, добра је идеја имати при руци резервни уређај како би се процес замене неисправног уређаја добрим погоном могао обавити у трену. Да бисмо то урадили, додајмо поново /dev/sdb1 и /dev/sdc1:
# мдадм --манаге /дев /мд0 --адд /дев /сдб1. # мдадм --манаге /дев /мд0 --адд /дев /сдц1.
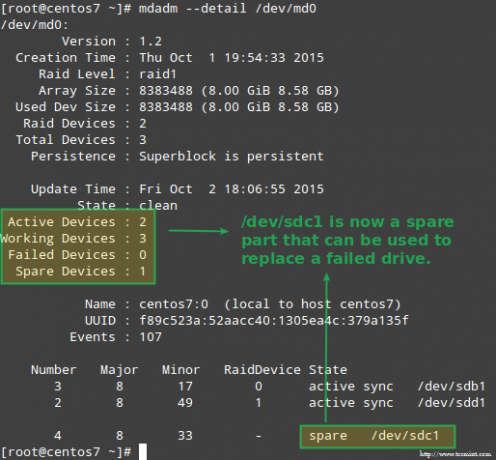
Као што је раније објашњено, мдадм ће аутоматски обновити податке када један диск откаже. Али шта се дешава ако 2 диска у низу не успеју? Симулирајмо такав сценарио означавањем /dev/sdb1 и /dev/sdd1 као неисправан:
# умоунт /мнт /раид1. # мдадм --манаге --сет-фаулти /дев /мд0 /дев /сдб1. # мдадм --стоп /дев /мд0. # мдадм --манаге --сет-фаулти /дев /мд0 /дев /сдд1.
Покушава да поново створи низ на исти начин на који је направљен у овом тренутку (или користећи --асуме-цлеан опција) може довести до губитка података, па их треба оставити као крајње средство.
Покушајмо да повратимо податке /dev/sdb1, на пример, на сличну партицију диска (/dev/sde1 - имајте на уму да ово захтева да креирате партицију типа фд у /dev/sde пре него што наставите) коришћењем ддресцуе:
# ддресцуе -р 2 /дев /сдб1 /дев /сде1.
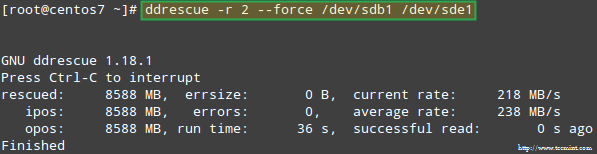
Имајте на уму да до овог тренутка нисмо додиривали /dev/sdb или /dev/sdd, партиције које су биле део РАИД низа.
Сада поново изградимо низ помоћу /dev/sde1 и /dev/sdf1:
# мдадм --цреате /дев /мд0 --левел = миррор --раид-девицес = 2 /дев /сд [е-ф] 1.
Имајте на уму да ћете у стварној ситуацији обично користити исте називе уређаја као у оригиналном низу, тј. /dev/sdb1 и /dev/sdc1 након што су неуспели дискови замењени новим.
У овом чланку сам одлучио да користим додатне уређаје за поновно креирање низа са потпуно новим дисковима и да избегнем забуну са оригиналним неуспелим погонима.
На питање да ли желите да наставите са писањем низа, откуцајте И и притисните Ентер. Низ треба покренути и моћи ћете да пратите његов напредак са:
# ватцх -н 1 цат /проц /мдстат.
Када се процес заврши, требали бисте моћи приступити садржају вашег РАИД -а:
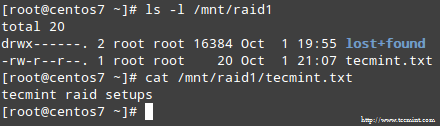
У овом чланку смо прегледали како се опоравити РАИД кварови и губици редундантности. Међутим, морате запамтити да је ова технологија решење за складиштење и НЕ замените резервне копије.
Принципи објашњени у овом водичу подједнако се примењују на све поставке РАИД -а, као и концепти које ћемо обрадити у следећем и последњем водичу ове серије (управљање РАИД -ом).
Ако имате питања о овом чланку, слободно нам пошаљите белешку користећи образац за коментаре испод. Ми очекујемо да чујемо од вас!