
Недавно Linux Foundation запустил LFCS (Сертифицированный системный администратор Linux Foundation), это отличный шанс для системных администраторов во всем мире продемонстрировать с помощью экзамена на основе результатов, что они способны выполнять общая операционная поддержка в системах Linux: поддержка системы, диагностика и мониторинг на первом уровне, а также, при необходимости, эскалация проблем для других служб поддержки команды.

Следующее видео представляет собой введение в программу сертификации Linux Foundation.
Этот пост является частью 6 серии из 10 руководств, здесь, в этой части, мы объясним, как собрать Разделы как устройства RAID - создание и управление резервными копиями системы, которые необходимы для LFCS сертификационный экзамен.
Технология, известная как избыточный массив независимых дисков (RAID) - это решение для хранения, которое объединяет несколько жестких дисков в одну логическую единицу для обеспечения избыточности данных и / или повышения производительности операций чтения / записи на диск.
Однако фактическая отказоустойчивость и производительность дискового ввода-вывода зависят от того, как жесткие диски настроены для формирования дискового массива. В зависимости от доступных устройств и требований к отказоустойчивости / производительности определяются разные уровни RAID. Вы можете обратиться к серии RAID здесь, на Tecmint.com, для более подробного объяснения каждого уровня RAID.
Руководство по RAID: Что такое RAID, объяснение концепций RAID и уровней RAID
Наш любимый инструмент для создания, сборки, управления и мониторинга наших программных RAID-массивов называется мдадм (сокращение от администратора нескольких дисков).
Debian и производные # aptitude update && aptitude install mdadm
Системы на базе Red Hat и CentOS # yum update && yum install mdadm.
В openSUSE # zypper refresh && zypper install mdadm #
Процесс сборки существующих разделов как RAID-устройств состоит из следующих шагов.
Если один из разделов был ранее отформатирован или ранее был частью другого RAID-массива, вам будет предложено подтвердить создание нового массива. Предполагая, что вы приняли необходимые меры предосторожности, чтобы избежать потери важных данных, которые могли в них храниться, вы можете безопасно ввести у и нажмите Войти.
# mdadm --create --verbose / dev / md0 --level = stripe --raid-devices = 2 / dev / sdb1 / dev / sdc1.

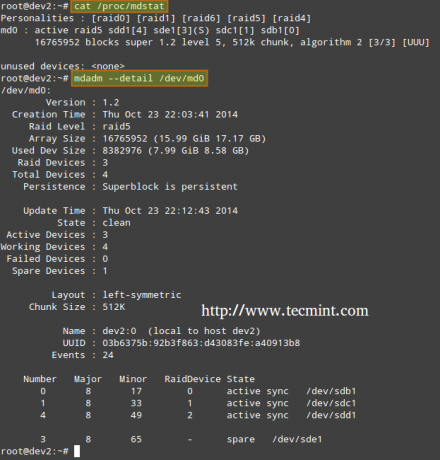
Чтобы проверить статус создания массива, вы будете использовать следующие команды - независимо от типа RAID. Они так же действительны, как когда мы создаем RAID0 (как показано выше), или когда вы находитесь в процессе настройки RAID5, как показано на изображении ниже.
# cat / proc / mdstat. или # mdadm --detail / dev / md0 [Более подробная информация]
Отформатируйте устройство с файловой системой в соответствии с вашими потребностями / требованиями, как описано в Часть 4 из этой серии.
Дайте указание службе мониторинга «следить» за массивом. Добавьте вывод mdadm –detail –scan к /etc/mdadm/mdadm.conf (Debian и производные) или /etc/mdadm.conf (CentOS / openSUSE), вот так.
# mdadm --detail --scan.
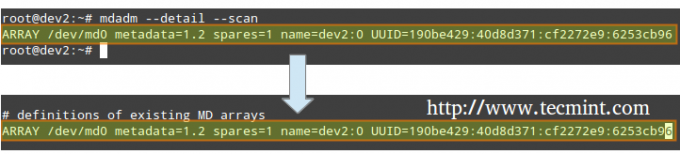
# mdadm --assemble --scan [собрать массив]
Чтобы служба запускалась при загрузке системы, выполните следующие команды от имени пользователя root.
Debian и его производные, хотя по умолчанию он должен запускаться при загрузке.
# update-rc.d mdadm defaults.
Отредактируйте /etc/default/mdadm файл и добавьте следующую строку.
АВТОЗАПУСК = истина.
# systemctl запускает mdmonitor. # systemctl включить mdmonitor.
# запуск службы mdmonitor. # chkconfig mdmonitor на.
На уровнях RAID, поддерживающих избыточность, при необходимости заменяйте вышедшие из строя диски. Когда устройство в дисковом массиве выходит из строя, перестройка автоматически начинается только в том случае, если при первом создании массива было добавлено запасное устройство.
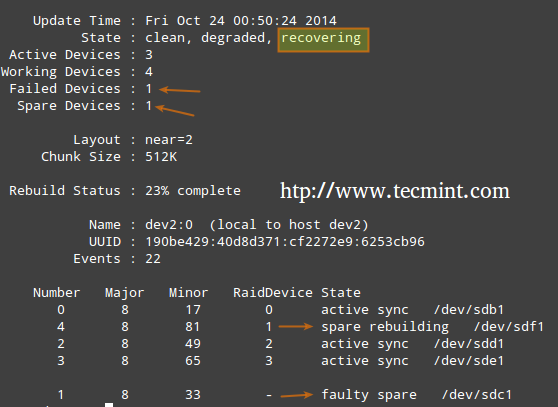
В противном случае нам нужно вручную подключить к нашей системе дополнительный физический диск и запустить его.
# mdadm / dev / md0 --add / dev / sdX1.
Где /dev/md0 это массив, в котором возникла проблема, и /dev/sdX1 это новое устройство.
Возможно, вам придется сделать это, если вам нужно создать новый массив с помощью устройств - (Необязательный шаг).
# mdadm --stop / dev / md0 # Остановить массив. # mdadm --remove / dev / md0 # Удалите устройство RAID. # mdadm --zero-superblock / dev / sdX1 # Заменить существующий суперблок md нулями.
Вы можете настроить действующий адрес электронной почты или системную учетную запись для отправки предупреждений (убедитесь, что у вас есть эта строка в mdadm.conf). – (Необязательный шаг)
MAILADDR корень.
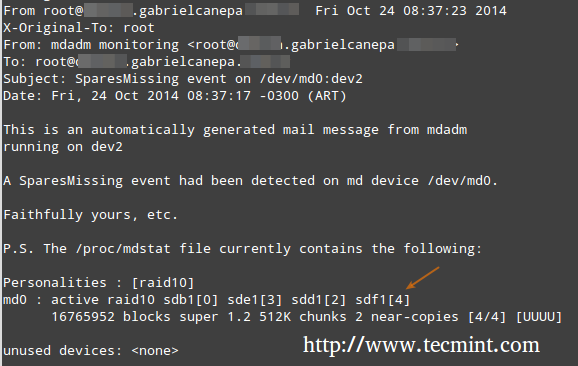
В этом случае все предупреждения, которые собирает демон мониторинга RAID, будут отправляться на почтовый ящик локальной учетной записи root. Одно из таких предупреждений выглядит следующим образом.
Примечание: Это событие связано с примером в ШАГ 5., где устройство было помечено как неисправное, а резервное устройство было автоматически добавлено в массив с помощью mdadm. Таким образом, мы «выбежал”Исправных запасных устройств, и мы получили предупреждение.
Общий размер массива п умноженный на размер наименьшего раздела, где п - количество независимых дисков в массиве (вам понадобится как минимум два диска). Выполните следующую команду, чтобы собрать RAID 0 массив с использованием разделов /dev/sdb1 и /dev/sdc1.
# mdadm --create --verbose / dev / md0 --level = stripe --raid-devices = 2 / dev / sdb1 / dev / sdc1.
Общее использование: Установки, поддерживающие приложения реального времени, где производительность важнее отказоустойчивости.
Общий размер массива равен размеру самого маленького раздела (вам понадобится как минимум два диска). Выполните следующую команду, чтобы собрать RAID 1 массив с использованием разделов /dev/sdb1 и /dev/sdc1.
# mdadm --create --verbose / dev / md0 --level = 1 --raid-devices = 2 / dev / sdb1 / dev / sdc1.
Общее использование: Установка операционной системы или важных подкаталогов, таких как /home.
Общий размер массива будет (п - 1), умноженное на размер наименьшего раздела. Значок «потерянный”Пробел в (п-1) используется для расчета четности (избыточности) (потребуется как минимум три диска).
Обратите внимание, что вы можете указать запасное устройство (/dev/sde1 в этом случае) для замены неисправной детали при возникновении проблемы. Выполните следующую команду, чтобы собрать RAID 5 массив с использованием разделов /dev/sdb1, /dev/sdc1, /dev/sdd1, и /dev/sde1 как запасной.
# mdadm --create --verbose / dev / md0 --level = 5 --raid-devices = 3 / dev / sdb1 / dev / sdc1 / dev / sdd1 --spare-devices = 1 / dev / sde1.
Общее использование: Веб-серверы и файловые серверы.
Общий размер массива будет (н * с) -2 * с, куда п - количество независимых дисков в массиве и s это размер самого маленького диска. Обратите внимание, что вы можете указать запасное устройство (/dev/sdf1 в этом случае) для замены неисправной детали при возникновении проблемы.
Выполните следующую команду, чтобы собрать RAID 6 массив с использованием разделов /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, и /dev/sdf1 как запасной.
# mdadm --create --verbose / dev / md0 --level = 6 --raid-devices = 4 / dev / sdb1 / dev / sdc1 / dev / sdd1 / dev / sde --spare-devices = 1 / dev / sdf1.
Общее использование: Файловые серверы и серверы резервного копирования с большой емкостью и высокими требованиями к доступности.
Общий размер массива вычисляется по формулам для RAID 0 и RAID 1, поскольку RAID 1 + 0 представляет собой комбинацию обоих. Сначала рассчитайте размер каждого зеркала, а затем размер полосы.
Обратите внимание, что вы можете указать запасное устройство (/dev/sdf1 в этом случае) для замены неисправной детали при возникновении проблемы. Выполните следующую команду, чтобы собрать RAID 1 + 0 массив с использованием разделов /dev/sdb1, /dev/sdc1, /dev/sdd1, /dev/sde1, и /dev/sdf1 как запасной.
# mdadm --create --verbose / dev / md0 --level = 10 --raid-devices = 4 / dev / sd [b-e] 1 --spare-devices = 1 / dev / sdf1
Общее использование: Серверы баз данных и приложений, требующие быстрых операций ввода-вывода.
Никогда не помешает вспомнить тот рейд со всеми его наградами НЕ ЯВЛЯЕТСЯ ЗАМЕНА РЕЗЕРВНЫХ КОПИЙ! Если нужно, напишите это 1000 раз на доске, но всегда помните об этом. Прежде чем мы начнем, мы должны отметить, что нет универсальный решение для резервного копирования системы, но вот некоторые вещи, которые вам необходимо принять во внимание при планировании стратегии резервного копирования.
Способ 1: Резервное копирование целых дисков с дд команда. Вы можете создать резервную копию всего жесткого диска или раздела, создав точный образ в любой момент времени. Обратите внимание, что это лучше всего работает, когда устройство находится в автономном режиме, то есть оно не подключено и нет процессов, обращающихся к нему для операций ввода-вывода.
Обратной стороной этого подхода к резервному копированию является то, что образ будет иметь тот же размер, что и диск или раздел, даже если фактические данные занимают небольшой процент от него. Например, если вы хотите создать образ раздела 20 ГБ это только 10% полный, файл изображения по-прежнему будет 20 ГБ по размеру. Другими словами, резервное копирование выполняется не только для фактических данных, но и для всего раздела. Вы можете использовать этот метод, если вам нужны точные резервные копии ваших устройств.
# dd if = / dev / sda of = / system_images / sda.img. ИЛИ. В качестве альтернативы вы можете сжать файл изображения # dd if = / dev / sda | gzip -c> /system_images/sda.img.gz
# dd if = / system_images / sda.img of = / dev / sda. ИЛИ В зависимости от вашего выбора при создании образа gzip -dc /system_images/sda.img.gz | dd of = / dev / sda
Способ 2: Резервное копирование определенных файлов / каталоги с деготь команда - уже охвачена Часть 3 из этой серии. Вы можете использовать этот метод, если вам нужно сохранить копии определенных файлов и каталогов (файлы конфигурации, домашние каталоги пользователей и т. Д.).
Способ 3: Синхронизировать файлы с rsync команда. Rsync - это универсальный инструмент удаленного (и локального) копирования файлов. Если вам нужно сделать резервную копию и синхронизировать файлы с / на сетевые диски, rsync вам подойдет.
Независимо от того, синхронизируете ли вы два локальных каталога или локальные удаленные каталоги, смонтированные в локальной файловой системе, основной синтаксис остается одинаковым.
# rsync -av исходный_каталог целевой каталог.
Где, -а рекурсивно переходить в подкаталоги (если они существуют), сохранять символические ссылки, временные метки, разрешения и исходного владельца / группы и -v подробный.
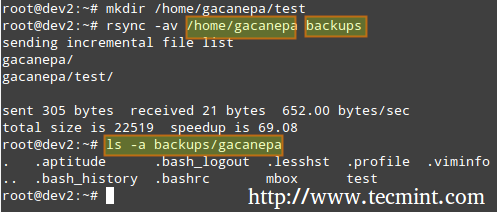
Кроме того, если вы хотите повысить безопасность передачи данных по проводам, вы можете использовать ssh над rsync.
# rsync -авже резервные копии ssh [электронная почта защищена]_host: / remote_directory /
В этом примере синхронизируется каталог резервных копий на локальном хосте с содержимым /root/remote_directory на удаленном хосте.
Где -час опция показывает размеры файлов в удобочитаемом формате, а -e Флаг используется для обозначения ssh-соединения.
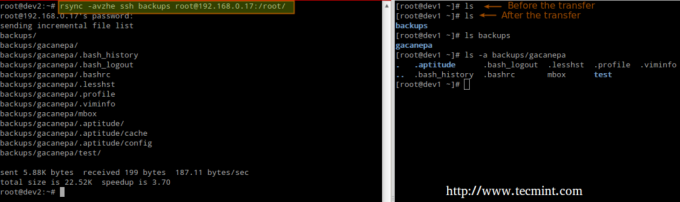
Синхронизация удаленных → локальных каталогов по ssh.
В этом случае переключите исходный и целевой каталоги из предыдущего примера.
# rsync -avzhe ssh [электронная почта защищена]_host: / удаленный_каталог / резервные копии
Обратите внимание, что это всего 3 примера (наиболее частые случаи, с которыми вы, вероятно, столкнетесь) использования rsync. Дополнительные примеры и использование команд rsync можно найти в следующей статье.
Читайте также: 10 команд rsync для синхронизации файлов в Linux
Как системный администратор, вы должны убедиться, что ваши системы работают как можно лучше. Если вы хорошо подготовлены и если целостность ваших данных хорошо поддерживается такой технологией хранения, как RAID и регулярное резервное копирование системы, вы будете в безопасности.
Если у вас есть вопросы, комментарии или дальнейшие идеи о том, как можно улучшить эту статью, не стесняйтесь высказываться ниже. Кроме того, рассмотрите возможность публикации этой серии через свои профили в социальных сетях.

