
Linux Foundation объявил LFCS (Сертифицированный системный администратор Linux Foundation), новая программа, цель которой - помочь людям во всем мире пройти сертификацию по базовым и промежуточным задачам системного администрирования для систем Linux. Это включает в себя поддержку работающих систем и служб, а также устранение неполадок и анализ из первых рук, а также умное принятие решений для передачи проблем в группы инженеров.

Посмотрите следующее видео, в котором рассказывается о программе сертификации Linux Foundation.
Сериал будет называться «Подготовка к LFCS (Сертифицированный системный администратор Linux Foundation) Детали 1 через 10 и охватите следующие темы для Ubuntu, CentOS и openSUSE:
Часть 1: Как использовать команду GNU «sed» для создания, редактирования и управления файлами в Linux
Важный: В связи с изменениями в требованиях сертификации LFCS вступают в силу Февраль 2, 2016, мы включаем следующие необходимые темы в опубликованную здесь серию LFCS. Для подготовки к этому экзамену вам настоятельно рекомендуется использовать Серия LFCE также.
Этот пост является частью 1 из 20-обучающая серия, который будет охватывать необходимые области и компетенции, необходимые для LFCS сертификационный экзамен. При этом запустите свой терминал и приступим.
Linux обрабатывает ввод и вывод программ как потоки (или последовательности) символов. Чтобы начать понимать перенаправление и каналы, мы должны сначала понять три наиболее важных типа потоков ввода-вывода (ввод и вывод), которые фактически являются специальными файлами (по соглашению в UNIX и Linux потоки данных и периферийные устройства или файлы устройств также рассматриваются как обычные файлы).
Разница между > (оператор перенаправления) и | (оператор конвейера) заключается в том, что в то время как первый связывает команду с файлом, последний связывает вывод команды с другой командой.
# команда> файл. # command1 | команда2.
Поскольку оператор перенаправления автоматически создает или перезаписывает файлы, мы должны использовать его с особой осторожностью и никогда не путать с конвейером. Одним из преимуществ конвейеров в системах Linux и UNIX является отсутствие промежуточного файла, связанного с канал - стандартный вывод первой команды не записывается в файл, а затем читается второй команда.
Для следующих практических упражнений мы будем использовать стихотворение «Счастливый ребенок»(Анонимный автор).
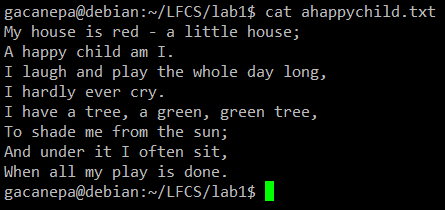
Название sed - сокращение от Stream Editor. Для тех, кто не знаком с этим термином, редактор потока используется для выполнения основных текстовых преобразований во входном потоке (файл или вход из конвейера).
Самое простое (и популярное) использование sed - это замена символов. Мы начнем с изменения каждого вхождения в нижний регистр у в ВЕРХНИЙ РЕГИСТР Y и перенаправляем вывод на ahappychild2.txt. В г Флаг указывает, что sed должен выполнить замену для всех экземпляров термина в каждой строке файла. Если этот флаг опущен, sed заменит только первое вхождение термина в каждой строке.
# файл sed 's / term / replace / flag'.
# sed ‘s / y / Y / g’ ahappychild.txt> ahappychild2.txt.

Если вы хотите найти или заменить специальный символ (например, /, \, &) вам нужно экранировать его в строке термина или замещающей строки обратной косой чертой.
Например, мы заменим слово и на амперсанд. Заодно заменим слово я с Ты когда первый находится в начале строки.
# sed 's / и / \ & / g; s / ^ I / You / g 'ahappychild.txt.
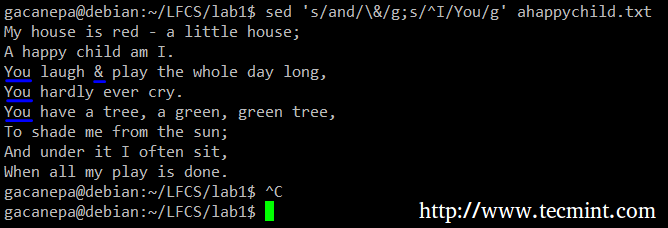
В приведенной выше команде ^ (знак каретки) - хорошо известное регулярное выражение, которое используется для обозначения начала строки.
Как видите, мы можем объединить две или более команды подстановки (и использовать внутри них регулярные выражения), разделив их точкой с запятой и заключив набор в одинарные кавычки.
Другое использование sed - отображение (или удаление) выбранной части файла. В следующем примере мы отобразим первые 5 строк /var/log/messages с 8 июн.
# sed -n '/ ^ 8 июня / p' / var / log / messages | sed -n 1,5p.
Обратите внимание, что по умолчанию sed печатает каждую строку. Мы можем изменить это поведение с помощью -n вариант, а затем скажите sed для печати (обозначено п) только часть файла (или конвейера), которая соответствует шаблону (8 июня в начале строки в первом случае и строки с 1 по 5 включительно во втором случае).
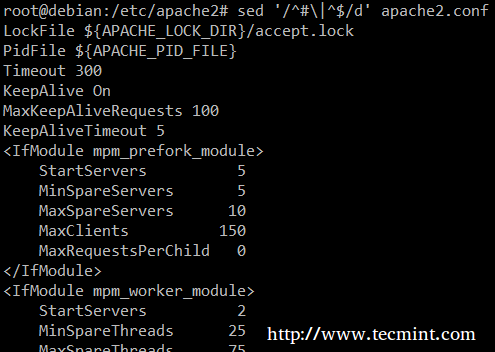
Наконец, это может быть полезно при проверке сценариев или файлов конфигурации, чтобы проверить сам код и оставить комментарии. Следующий однострочный файл sed удаляет (d) пустые строки или строки, начинающиеся с # (в | обозначает логическое ИЛИ между двумя регулярными выражениями).
# sed '/ ^ # \ | ^ $ / d' apache2.conf.
В уникальный Команда позволяет нам сообщать или удалять повторяющиеся строки в файле, по умолчанию записывая в стандартный вывод. Следует отметить, что уникальный не обнаруживает повторяющиеся строки, если они не являются смежными. Таким образом, уникальный обычно используется вместе с предыдущим Сортировать (который используется для сортировки строк текстовых файлов). По умолчанию, Сортировать принимает первое поле (разделенное пробелами) как ключевое поле. Чтобы указать другое ключевое поле, нам нужно использовать -k вариант.
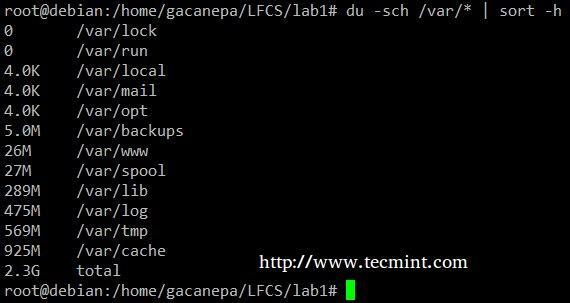
В du –sch / путь / к / каталогу / * команда возвращает использование дискового пространства для подкаталогов и файлов в указанном каталоге в удобочитаемом формате. формат (также показывает общее количество для каждого каталога) и упорядочивает вывод не по размеру, а по подкаталогу и имени файла. Мы можем использовать следующую команду для сортировки по размеру.
# du -sch / var / * | sort –h.
Вы можете подсчитать количество событий в журнале по дате, указав уникальный для выполнения сравнения с использованием первых 6 символов (-w 6) каждой строки (где указана дата) и префикса каждой выходной строки числом вхождений (-c) с помощью следующей команды.
# cat /var/log/mail.log | uniq -c -w 6.

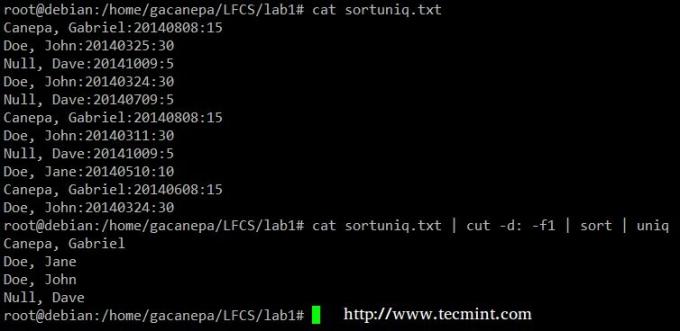
Наконец, вы можете комбинировать Сортировать и уникальный (как обычно). Рассмотрим следующий файл со списком жертвователей, датой пожертвования и суммой. Предположим, мы хотим узнать, сколько существует уникальных доноров. Мы будем использовать следующую команду, чтобы вырезать первое поле (поля разделены двоеточием), отсортировать по имени и удалить повторяющиеся строки.
# cat sortuniq.txt | вырезать -d: -f1 | сортировать | uniq.
Читайте также: 13 примеров команд «cat»
grep ищет текстовые файлы или (вывод команды) на предмет наличия указанного регулярного выражения и выводит любую строку, содержащую совпадение, со стандартным выводом.
Отобразить информацию из /etc/passwd для пользователя gacanepa, без учета регистра.
# grep -i gacanepa / etc / passwd.

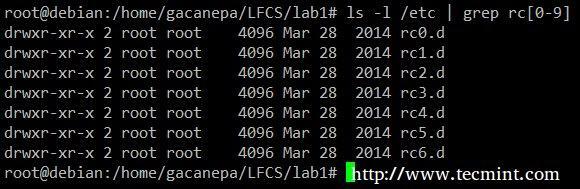
Показать все содержимое /etc чье имя начинается с rc за которым следует любое число.
# ls -l / etc | grep rc [0-9]
Читайте также: 12 примеров команд «grep»
В tr Команда может использоваться для перевода (изменения) или удаления символов из стандартного ввода и записи результата в стандартный вывод.
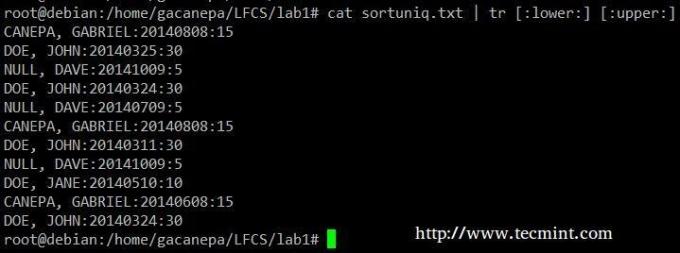
Измените все строчные буквы на прописные в файле sortuniq.txt.
# cat sortuniq.txt | tr [: lower:] [: upper:]
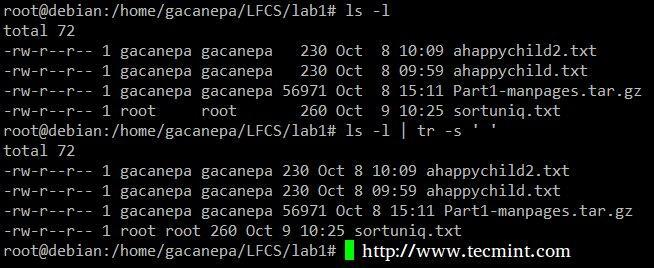
Сожмите разделитель в выводе ls –l только в одно пространство.
# ls -l | tr -s ''
В резать команда извлекает части входных строк (из stdin или файлов) и отображает результат в стандартном выводе на основе количества байтов (-b вариант), символы (-c) или поля (-f). В этом последнем случае (на основе полей) разделителем полей по умолчанию является табуляция, но можно указать другой разделитель с помощью -d вариант.
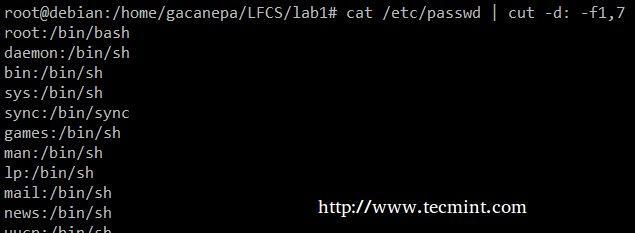
Извлеките учетные записи пользователей и назначенные им оболочки по умолчанию из /etc/passwd (в –D опция позволяет нам указать разделитель полей, а –F переключатель указывает, какие поля будут извлечены.
# cat / etc / passwd | вырезать -d: -f1,7.
Подводя итог, создадим текстовый поток, состоящий из первого и третьего непустых файлов вывода последний команда. Мы будем использовать grep в качестве первого фильтра для проверки сеансов пользователя гаканепа, затем сожмите разделители только до одного пробела (tr -s ‘ ‘). Затем мы извлечем первое и третье поля с помощью резать, и, наконец, сортировка по второму полю (в данном случае IP-адресам), показывающему уникальность.
# последний | grep gacanepa | тр-с '' | вырезать -d '' -f1,3 | sort -k2 | uniq.
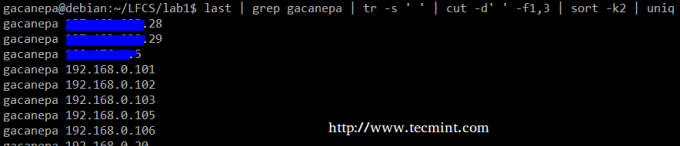
Приведенная выше команда показывает, как можно объединить несколько команд и каналов, чтобы получить отфильтрованные данные в соответствии с нашими желаниями. Не стесняйтесь запускать его по частям, чтобы помочь вам увидеть вывод, который конвейерно передается от одной команды к другой (кстати, это может быть отличным опытом для обучения!).
Хотя этот пример (вместе с остальными примерами в текущем руководстве) на первый взгляд может показаться не очень полезным, они хорошая отправная точка, чтобы начать экспериментировать с командами, которые используются для создания, редактирования и управления файлами с помощью команды Linux линия. Не стесняйтесь оставлять свои вопросы и комментарии ниже - мы будем очень признательны!

