
Каждому системному администратору приходится ежедневно иметь дело с текстовыми файлами. Знание того, как просматривать определенные разделы, как заменять слова и как фильтровать контент из этих файлов, - это навыки, которые вам нужно иметь под рукой, не выполняя поиск в Google.

В этой статье мы рассмотрим sed, известный редактор потоков, и поделимся 15 советами по его использованию для достижения целей, упомянутых ранее, и многого другого.
Такие инструменты как голова и хвост позволяют нам просматривать нижнюю или верхнюю часть файла. Что, если нам нужно просмотреть раздел посередине? Следующий однострочный sed вернет строки 5 через 10 из myfile.txt:
# sed -n '5,10p' myfile.txt.
С другой стороны, возможно, вы захотите распечатать весь файл, кроме определенного диапазона. Чтобы исключить строки 20 через 35 из myfile.txt, делать:
# sed '20, 35d 'myfile.txt.
Возможно, вас интересует набор непоследовательных строк или более одного диапазона. Отобразим линии 5-7 и 10-13 из myfile.txt:
# sed -n -e '5,7p' -e '10, 13p 'myfile.txt.
Как видите, -e опция позволяет нам выполнять заданное действие (в данном случае строки печати) для каждого диапазона.
Чтобы заменить каждое вхождение слова версия с история в myfile.txt, делать:
# sed 's / version / story / g' myfile.txt.
Кроме того, вы можете рассмотреть возможность использования джи вместо г чтобы игнорировать регистр символов:
# sed 's / version / story / gi' myfile.txt.
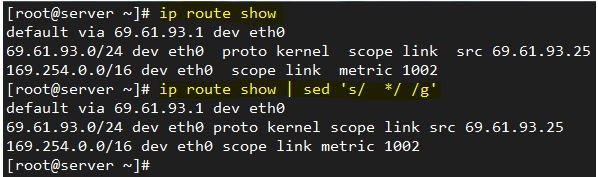
Чтобы заменить несколько пробелов одним пробелом, мы будем использовать вывод ip route show и трубопровод:
# ip route show | sed 's / * / / g'
Сравните вывод ip route show с трубопроводом и без:
Если вас интересует замена слов только в диапазоне строк (30 через 40, например), вы можете:
# sed '30, 40 с / версия / история / g 'myfile.txt.
Конечно, вы можете указать одну строку через соответствующий ей номер вместо диапазона.
Иногда файлы конфигурации загружаются с комментариями. Хотя это, безусловно, полезно, иногда может быть полезно отображать только директивы конфигурации, если вы хотите просмотреть их все сразу.
Чтобы удалить пустые строки или строки, начинающиеся с # из файла конфигурации Apache выполните:
# sed '/ ^ # \ | ^ $ \ | * # / d 'httpd.conf.
Знак каретки, за которым следует знак числа (^#) указывает начало строки, тогда как ^$ представляет собой пустые строки. Вертикальные полосы обозначают логические операции, а обратная косая черта используется для экранирования вертикальных полос.
В этом конкретном случае файл конфигурации Apache содержит строки с # S не в начале некоторых строк, поэтому *# также используется для их удаления.
Чтобы заменить слово, начинающееся с верхнего или нижнего регистра, другим словом, мы также можем использовать sed. Для иллюстрации заменим слово застегивать или Почтовый индекс с rar в myfile.txt:
# sed 's / [Zz] ip / rar / g' myfile.txt.
Не пропустите:Используйте Awk с регулярными выражениями для фильтрации текста в файлах
Другое использование sed состоит в печати строк из файла, соответствующих заданному регулярному выражению. Например, нас может заинтересовать просмотр действий по авторизации и аутентификации, которые имели место на 2 июля, в соответствии с /var/log/secure войти в CentOS 7 сервер.
В этом случае шаблон для поиска 2 июл в начале каждой строки:
# sed -n '/ ^ 1 июля / p' / var / log / secure.

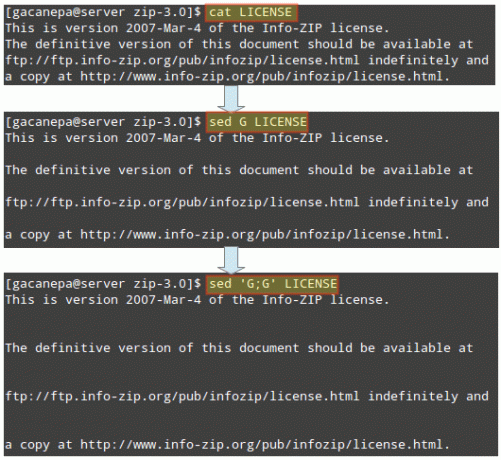
С sed, мы также можем вставлять пробелы (пустые строки) для каждой непустой строки в файле. Чтобы вставить одну пустую строку в каждую вторую строку в ЛИЦЕНЗИЯ, обычный текстовый файл, выполните:
# sed G myfile.txt.
Чтобы вставить две пустые строки, выполните:
# sed 'G; G 'myfile.txt.
Добавить прописная G разделенные точкой с запятой, если вы хотите добавить больше пустых строк. Следующее изображение иллюстрирует пример, изложенный в этом совете:
Этот совет может пригодиться, если вы хотите проверить большой файл конфигурации. Вставка пустого пространства в каждую вторую строку и уменьшение вывода по конвейеру приведет к более удобному чтению.
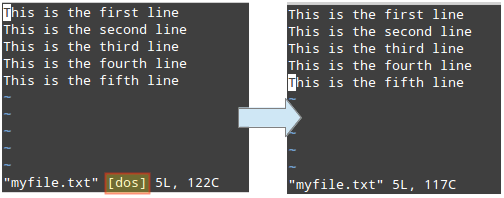
В dos2unix Программа конвертирует простые текстовые файлы из форматирования Windows / Mac в Unix / Linux, удаляя скрытые символы новой строки, вставленные некоторыми текстовыми редакторами, используемыми на этих платформах. Если он не установлен в вашей системе Linux, вы можете имитировать его функциональность с помощью sed вместо того, чтобы устанавливать его.
На изображении слева мы видим несколько символов новой строки DOS. (^ M), которые позже были удалены с помощью:
# sed -i 's / \ r //' myfile.txt.
Обратите внимание, что -я опция указывает редактирование на месте. Тогда изменения не вернутся на экран, а будут сохранены в файл.
Примечание: Вы можете вставлять символы новой строки DOS, пока редактирование файла в редакторе vim с Ctrl + V и Ctrl + M.
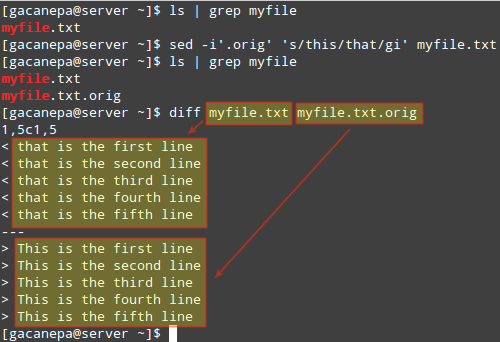
В предыдущем совете мы использовали sed чтобы изменить файл, но не сохранил исходный файл. Иногда на всякий случай рекомендуется сохранить резервную копию исходного файла.
Для этого укажите суффикс после -я вариант (в одинарных кавычках), который будет использоваться для переименования исходного файла.
В следующем примере мы заменим все экземпляры это или Этот (без учета регистра) с тем, что в myfile.txt, и мы сохраним исходный файл как myfile.txt.orig.
Наконец, мы будем использовать утилита diff чтобы определить различия между обоими файлами:
# sed -i'.orig '' s / this / that / gi 'myfile.txt.
Предположим, у вас есть файл, содержащий полные имена в формате Имя, Фамилия. Чтобы правильно обработать файл, вы можете переключить Фамилия и Имя.
Мы можем сделать это с sed довольно легко:
# sed 's / ^ \ (. * \), \ (. * \) $ / \, / g' names.txt.
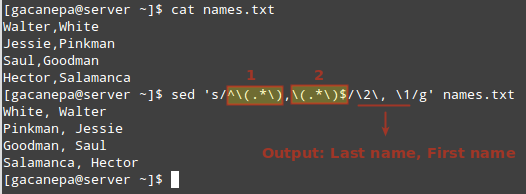
На изображении выше мы видим, что скобки, являющиеся специальными символами, должны быть экранированы, как и числа 1 и 2.
Эти числа представляют собой выделенные регулярные выражения (которые должны быть заключены в круглые скобки):
Желаемый результат указывается в формате SecondColumn (Фамилия) + запятая + пространство + FirstColumn (Имя). Не стесняйтесь менять его на то, что хотите.
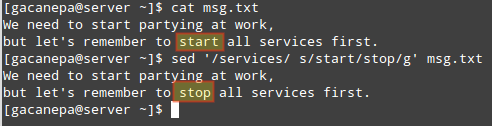
Иногда замена всех экземпляров данного слова или нескольких случайных - это не совсем то, что нам нужно. Возможно, нам потребуется произвести замену, если будет найдено отдельное совпадение.
Например, мы можем захотеть заменить Начало с останавливаться только если слово services находится в той же строке. В этом случае произойдет следующее:
Нам нужно начинать вечеринки на работе, но не забудьте сначала запустить все службы.
В первой строке Начало не будет заменен на останавливаться поскольку слово services не появляется в этой строке, в отличие от второй строки.
# sed '/ services / s / start / stop / g' msg.txt.
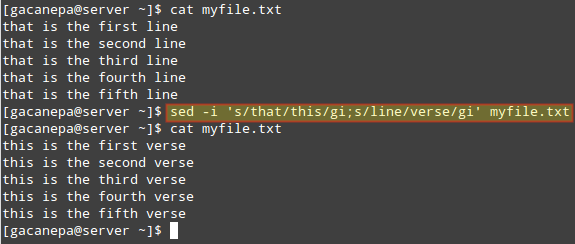
Вы можете объединить две и более замены в одну sed команда. Давайте заменим слова that и line в myfile.txt с Этим и стихом соответственно.
Обратите внимание, как это можно сделать с помощью обычного sed команда замены, за которой следует точка с запятой и вторая команда замены:
# sed -i 's / that / this / gi; s / line / verse / gi 'myfile.txt.
Этот совет проиллюстрирован на следующем изображении:
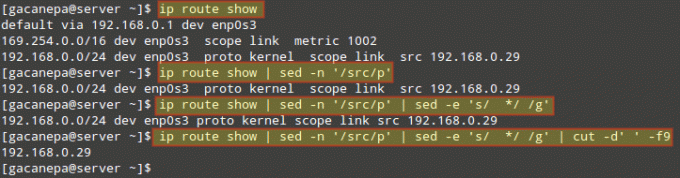
Конечно, sed можно комбинировать с другими инструментами для создания более мощных команд. Например, давайте воспользуемся примером, приведенным в СОВЕТ № 4 и извлеките наш IP-адрес из вывода IP-маршрут команда.
Мы начнем с печати только той строки, где слово src является. Затем мы конвертируем несколько пробелов в одно. Наконец, мы разрежем 9-е поле (с учетом одного пробела в качестве разделителя полей), в котором находится IP-адрес:
# ip route show | sed -n '/ src / p' | sed -e 's / * / / g' | вырезать -d '' -f9.
На изображении ниже показан каждый шаг вышеуказанной команды:
В этом руководстве мы поделились 15 советов и хитростей по sed чтобы помочь вам с повседневными задачами системного администрирования. Есть ли какой-нибудь другой совет, которым вы регулярно пользуетесь и которым хотели бы поделиться с нами и остальным сообществом?
Если да, дайте нам знать, используя форму комментариев ниже. Вопросы и комментарии также приветствуются - мы ждем от вас ответа!
Не пропустите:Освоение команды Linux «Awk» с помощью советов и приемов

