
Apache Spark - это распределенная вычислительная среда с открытым исходным кодом, созданная для обеспечения более быстрых результатов вычислений. Это вычислительный механизм в памяти, то есть данные будут обрабатываться в памяти.
Искра поддерживает различные API для потоковой передачи, обработки графиков, SQL, MLLib. Он также поддерживает Java, Python, Scala и R в качестве предпочтительных языков. Spark в основном устанавливается в Кластеры Hadoop но вы также можете установить и настроить Spark в автономном режиме.
В этой статье мы увидим, как установить Apache Spark в Debian и Ubuntuна основе дистрибутивов.
Установить Apache Spark в Ubuntu вам необходимо иметь Джава и Scala установлен на вашем компьютере. Большинство современных дистрибутивов поставляются с установленной по умолчанию Java, и вы можете проверить это с помощью следующей команды.
$ java -версия.

Если нет вывода, вы можете установить Java, используя нашу статью о как установить Java на Ubuntu
или просто выполните следующие команды для установки Java в дистрибутивах на основе Ubuntu и Debian.$ sudo apt update. $ sudo apt install default-jre. $ java -версия.

Далее вы можете установить Scala из репозитория apt, выполнив следующие команды, чтобы найти scala и установить его.
$ sudo apt search scala ⇒ Найдите пакет. $ sudo apt install scala ⇒ Установите пакет.
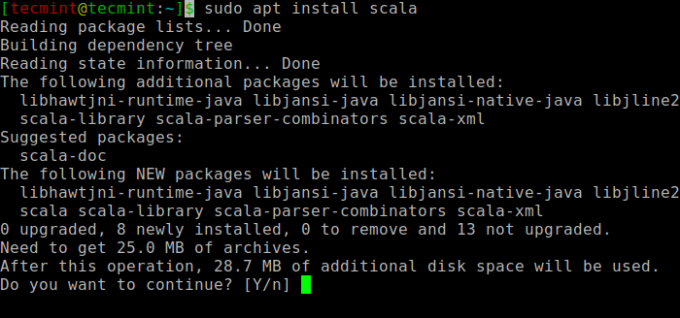
Чтобы проверить установку Scalaвыполните следующую команду.
$ scala -version Средство выполнения кода Scala версии 2.11.12 - Авторские права 2002-2017, LAMP / EPFL
Теперь зайдите в официальный Страница загрузки Apache Spark и скачайте последнюю версию (например, 3.1.1) на момент написания этой статьи. В качестве альтернативы вы можете использовать команда wget чтобы скачать файл прямо в терминал.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz.
Теперь откройте свой терминал, переключитесь туда, где находится загруженный файл, и выполните следующую команду, чтобы извлечь tar-файл Apache Spark.
$ tar -xvzf spark-3.1.1-bin-hadoop2.7.tgz.
Наконец, переместите извлеченный Искра каталог для /opt каталог.
$ sudo mv spark-3.1.1-bin-hadoop2.7 / opt / spark.
Теперь вам нужно установить несколько переменных среды в вашем .профиль файл перед запуском искры.
$ echo "export SPARK_HOME = / opt / spark" >> ~ / .profile. $ echo "экспорт ПУТЬ = $ ПУТЬ: / opt / spark / bin: / opt / spark / sbin" >> ~ / .profile. $ echo "экспорт PYSPARK_PYTHON = / usr / bin / python3" >> ~ / .profile.
Чтобы убедиться, что эти новые переменные среды доступны в оболочке и доступны для Apache Spark, также необходимо выполнить следующую команду, чтобы последние изменения вступили в силу.
$ source ~ / .profile.
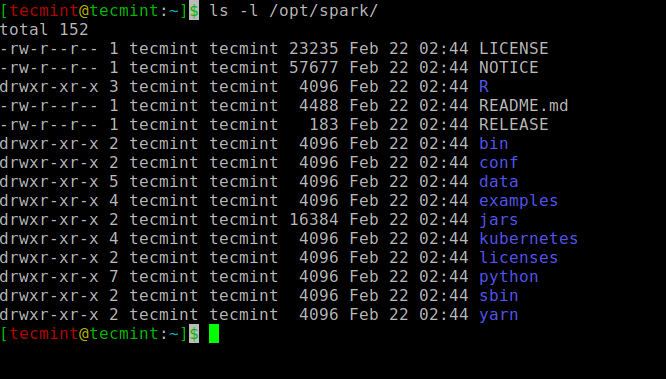
Все связанные с искрой двоичные файлы для запуска и остановки служб находятся под sbin папка.
$ ls -l / opt / spark.
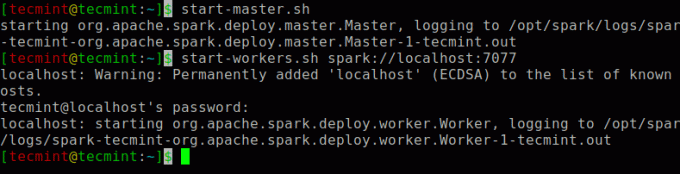
Выполните следующую команду, чтобы запустить Искра главная служба и подчиненная служба.
$ start-master.sh. $ start-workers.sh spark: // localhost: 7077.
После запуска службы зайдите в браузер и введите следующую искровую страницу доступа по URL-адресу. На этой странице вы можете увидеть, что мои ведущие и ведомые службы запущены.
http://localhost: 8080/ ИЛИ. http://127.0.0.1:8080.

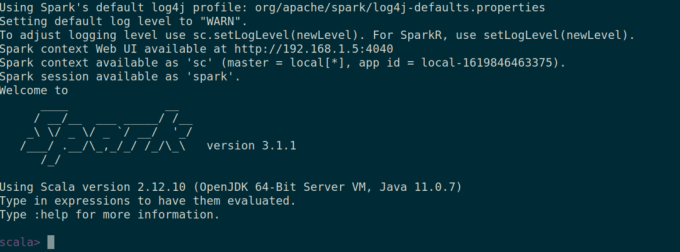
Вы также можете проверить, есть ли искровая гильза отлично работает, запустив искровая гильза команда.
$ Spark-Shell.
Это все для этой статьи. Скоро мы увидим еще одну интересную статью.

