
В предыдущих статьях этого Серия RAID вы прошли с нуля до RAID героя. Мы рассмотрели несколько программных конфигураций RAID и объяснили основы каждой из них, а также причины, по которым вы склоняетесь к тому или иному в зависимости от вашего конкретного сценария.

В этом руководстве мы обсудим, как восстановить программный RAID-массив без потери данных в случае сбоя диска. Для краткости мы будем рассматривать только RAID 1 setup - но концепции и команды применимы во всех случаях одинаково.
Прежде чем продолжить, убедитесь, что вы настроили RAID 1 array, следуя инструкциям, приведенным в Части 3 этой серии: Как настроить RAID 1 (зеркало) в Linux.
Единственными вариациями в нашем настоящем случае будут:
1) другая версия CentOS (v7), чем та, которая использовалась в этой статье (v6.5), и
2) разные размеры дисков для /dev/sdb и /dev/sdc (По 8 ГБ).
Кроме того, если SELinux включен в принудительном режиме, вам нужно будет добавить соответствующие метки в каталог, в который вы будете монтировать устройство RAID. В противном случае вы столкнетесь с этим предупреждающим сообщением при попытке смонтировать его:
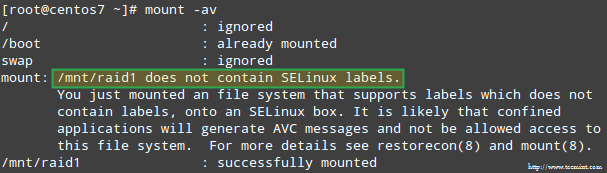
Вы можете исправить это, запустив:
# restorecon -R / mnt / raid1.
Существует множество причин, по которым устройство хранения может выйти из строя (хотя твердотельные накопители значительно снизили вероятность этого), но независимо от причины вы можете быть уверены, что проблемы могут возникнуть в любое время, и вы должны быть готовы заменить вышедшую из строя деталь и обеспечить доступность и целостность вашего данные.
Сначала небольшой совет. Даже когда вы можете осмотреть /proc/mdstat Чтобы проверить состояние ваших RAID-массивов, есть лучший и экономящий время метод, заключающийся в запуске мдадм в режиме монитора + сканирования, который отправляет оповещения по электронной почте заранее определенному получателю.
Чтобы настроить это, добавьте следующую строку в /etc/mdadm.conf:
MAILADDR [электронная почта защищена]
В моем случае:
MAILADDR [электронная почта защищена]

Бежать мдадм в режиме монитора + сканирования добавьте следующую запись crontab как root:
@reboot / sbin / mdadm --monitor --scan --oneshot.
По умолчанию, мдадм будет проверять массивы RAID каждые 60 секунд и отправлять предупреждение, если обнаружит проблему. Вы можете изменить это поведение, добавив --задерживать параметр в записи crontab выше вместе с количеством секунд (например, --задерживать 1800 означает 30 минут).
Наконец, убедитесь, что у вас есть Почтовый пользовательский агент (MUA) установлен, например mutt или mailx. В противном случае вы не получите никаких предупреждений.
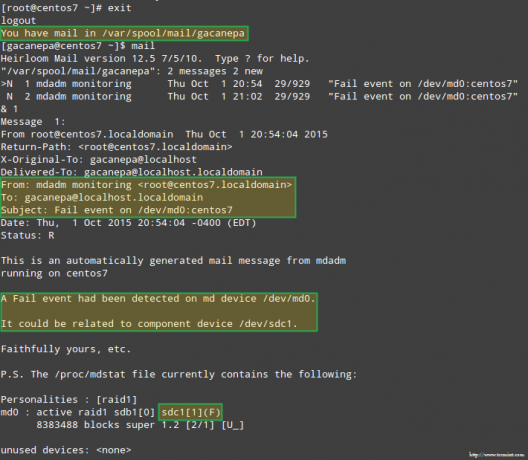
Через минуту мы увидим, какое оповещение отправил мдадм похоже.
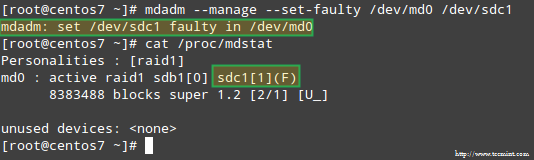
Чтобы смоделировать проблему с одним из устройств хранения в массиве RAID, мы будем использовать --управлять и --set-неисправный следующие варианты:
# mdadm --manage --set-faulty / dev / md0 / dev / sdc1
Это приведет к /dev/sdc1 помечены как неисправные, как мы видим на /proc/mdstat:
Что еще более важно, давайте посмотрим, получили ли мы уведомление по электронной почте с таким же предупреждением:
В этом случае потребуется удалить устройство из программного RAID-массива:
# mdadm / dev / md0 --remove / dev / sdc1.
Затем вы можете физически снять его с машины и заменить на запчасть (/dev/sdd, где раздел типа fd был создан ранее):
# mdadm --manage / dev / md0 --add / dev / sdd1.
К счастью для нас, система автоматически начнет перестраивать массив с той частью, которую мы только что добавили. Мы можем проверить это, отметив /dev/sdb1 как неисправный, удалив его из массива и убедившись, что файл tecmint.txt все еще доступен в /mnt/raid1:
# mdadm --detail / dev / md0. # mount | grep raid1. # ls -l / mnt / raid1 | grep tecmint. # cat /mnt/raid1/tecmint.txt.
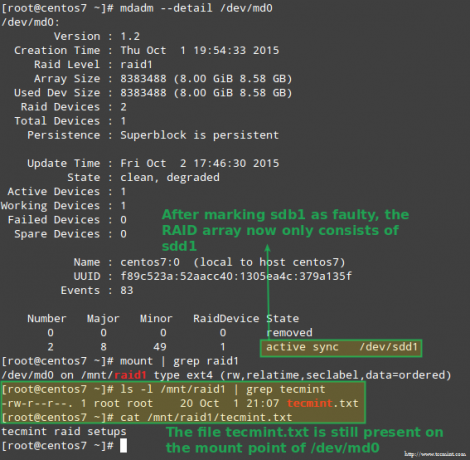
Изображение выше ясно показывает, что после добавления /dev/sdd1 в массив в качестве замены /dev/sdc1, восстановление данных было выполнено системой автоматически без нашего вмешательства.
Хотя это и не является обязательным требованием, неплохо иметь под рукой запасное устройство, чтобы процесс замены неисправного устройства на исправный диск можно было выполнить в мгновение ока. Для этого давайте повторно добавим /dev/sdb1 и /dev/sdc1:
# mdadm --manage / dev / md0 --add / dev / sdb1. # mdadm --manage / dev / md0 --add / dev / sdc1.
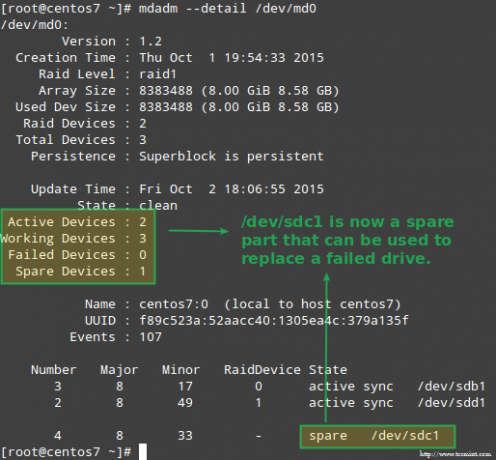
Как объяснялось ранее, мдадм автоматически восстановит данные при выходе из строя одного диска. Но что произойдет, если 2 диска в массиве выйдут из строя? Смоделируем такой сценарий, отметив /dev/sdb1 и /dev/sdd1 как неисправный:
# umount / mnt / raid1. # mdadm --manage --set-faulty / dev / md0 / dev / sdb1. # mdadm --stop / dev / md0. # mdadm --manage --set-faulty / dev / md0 / dev / sdd1.
Попытки воссоздать массив таким же образом, как он был создан в это время (или с помощью - считать-чистым option) может привести к потере данных, поэтому его следует оставить в крайнем случае.
Попробуем восстановить данные из /dev/sdb1, например, в аналогичный раздел диска (/dev/sde1 - обратите внимание, что для этого необходимо создать раздел типа fd в /dev/sde перед продолжением) используя ddrescue:
# ddrescue -r 2 / dev / sdb1 / dev / sde1.
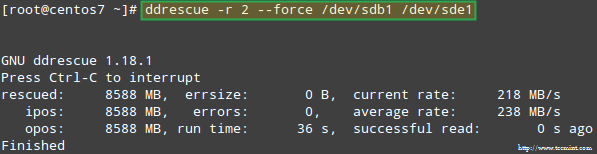
Обратите внимание, что до этого момента мы не затронули /dev/sdb или /dev/sdd, разделы, которые были частью RAID-массива.
Теперь давайте перестроим массив, используя /dev/sde1 и /dev/sdf1:
# mdadm --create / dev / md0 --level = mirror --raid-devices = 2 / dev / sd [e-f] 1.
Обратите внимание, что в реальной ситуации вы обычно будете использовать те же имена устройств, что и исходный массив, то есть /dev/sdb1 и /dev/sdc1 после замены вышедших из строя дисков на новые.
В этой статье я решил использовать дополнительные устройства для воссоздания массива с новыми дисками и во избежание путаницы с исходными неисправными дисками.
Когда вас спросят, продолжать ли писать массив, введите Y и нажмите Войти. Массив должен быть запущен, и вы сможете наблюдать за его развитием с помощью:
# смотреть -n 1 cat / proc / mdstat.
Когда процесс завершится, вы сможете получить доступ к содержимому вашего RAID:
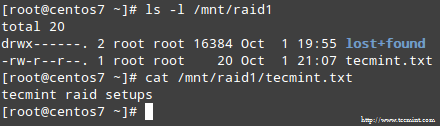
В этой статье мы рассмотрели, как восстановить RAID отказы и потери избыточности. Однако нужно помнить, что эта технология - решение для хранения и НЕ заменить бэкапы.
Принципы, описанные в этом руководстве, применимы как ко всем конфигурациям RAID, так и к концепциям, которые мы рассмотрим в следующем и последнем руководстве этой серии (управление RAID).
Если у вас есть какие-либо вопросы по этой статье, напишите нам, используя форму комментариев ниже. Мы с нетерпением ждем вашего ответа!
