Apache Spark este un cadru de calcul distribuit open-source care este creat pentru a oferi rezultate de calcul mai rapide. Este un motor de calcul în memorie, ceea ce înseamnă că datele vor fi procesate în memorie.
Scânteie acceptă diverse API-uri pentru streaming, procesare grafică, SQL, MLLib. De asemenea, acceptă Java, Python, Scala și R ca limbi preferate. Spark este instalat mai ales în Clustere Hadoop dar puteți instala și configura scânteia în modul independent.
În acest articol, vom vedea cum se instalează Apache Spark în Debian și Ubuntu-distribuții pe bază.
A instala Apache Spark în Ubuntu, trebuie să aveți Java și Scala instalat pe aparat. Majoritatea distribuțiilor moderne vin cu Java instalat implicit și îl puteți verifica folosind următoarea comandă.
$ java -version.

Dacă nu există ieșire, puteți instala Java folosind articolul nostru de pe cum se instalează Java pe Ubuntu sau pur și simplu executați următoarele comenzi pentru a instala Java pe distribuțiile bazate pe Ubuntu și Debian.
$ sudo apt actualizare. $ sudo apt install default-jre. $ java -version.

Apoi, puteți instala Scala din depozitul apt executând următoarele comenzi pentru a căuta scala și a o instala.
$ sudo apt căutare scala ⇒ Căutați pachetul. $ sudo apt install scala ⇒ Instalați pachetul.
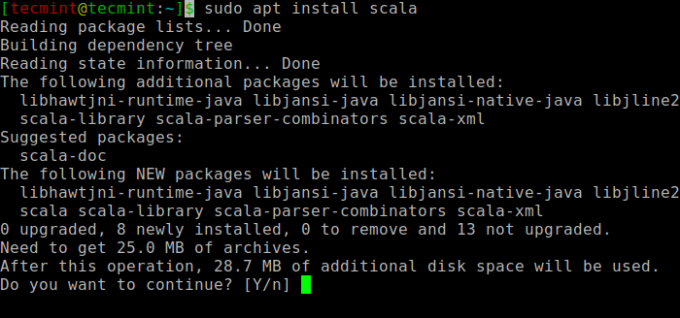
Pentru a verifica instalarea Scala, executați următoarea comandă.
$ scala -version Versiunea 2.11.12 a codului Scala Runner - Copyright 2002-2017, LAMP / EPFL
Acum mergi la oficial Pagina de descărcare Apache Spark și apucați cea mai recentă versiune (adică 3.1.1) în momentul redactării acestui articol. Alternativ, puteți utiliza fișierul comanda wget pentru a descărca fișierul direct în terminal.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz.
Acum deschideți terminalul și treceți la locul unde este plasat fișierul descărcat și rulați următoarea comandă pentru a extrage fișierul tar Apache Spark.
$ tar -xvzf spark-3.1.1-bin-hadoop2.7.tgz.
În cele din urmă, mutați extrasul Scânteie director către /opt director.
$ sudo mv spark-3.1.1-bin-hadoop2.7 / opt / spark.
Acum trebuie să setați câteva variabile de mediu în .profil înainte de a porni scânteia.
$ echo "export SPARK_HOME = / opt / spark" >> ~ / .profile. $ echo "export PATH = $ PATH: / opt / spark / bin: / opt / spark / sbin" >> ~ / .profile. $ echo "export PYSPARK_PYTHON = / usr / bin / python3" >> ~ / .profile.
Pentru a vă asigura că aceste noi variabile de mediu sunt accesibile în shell și disponibile pentru Apache Spark, este obligatoriu să rulați următoarea comandă pentru a intra în vigoare modificările recente.
$ source ~ / .profile.
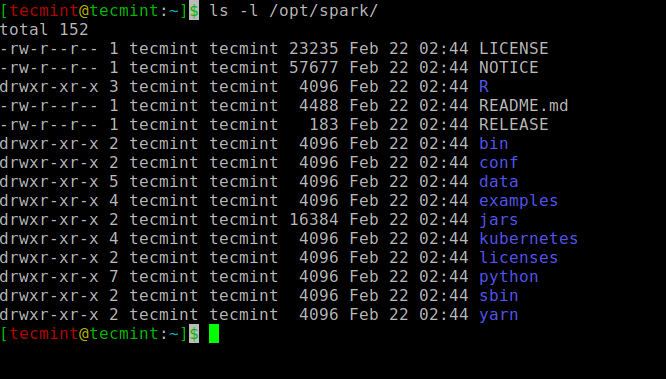
Toate binarele legate de scânteie pentru a porni și a opri serviciile se află sub sbin pliant.
$ ls -l / opt / spark.
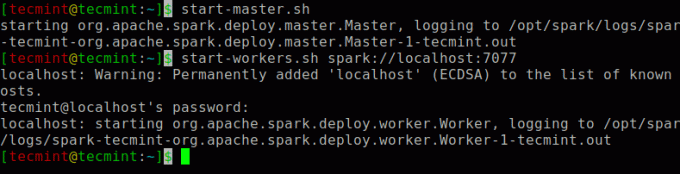
Rulați următoarea comandă pentru a porni Scânteie serviciu stăpân și serviciu sclav.
$ start-master.sh. $ start-workers.sh spark: // localhost: 7077.
Odată ce serviciul este pornit, accesați browserul și tastați următoarea pagină de accesare a URL-ului. Din pagină, puteți vedea că serviciul meu stăpân și sclav este pornit.
http://localhost: 8080/ SAU. http://127.0.0.1:8080.

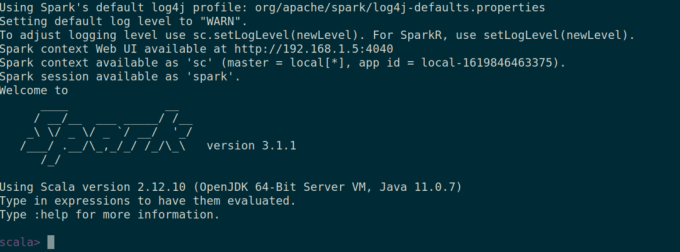
De asemenea, puteți verifica dacă scânteie funcționează bine prin lansarea scânteie comanda.
$ spark-shell.
Gata pentru acest articol. Vă vom prinde cu un alt articol interesant foarte curând.
