
Ennek korábbi cikkeiben RAID sorozat nulláról RAID -hősré váltál. Áttekintettünk több szoftveres RAID -konfigurációt, és elmagyaráztuk mindegyik lényeges elemeit, valamint azokat az okokat, amelyek miatt az adott forgatókönyvtől függően hajlik az egyik vagy a másik felé.

Ebben az útmutatóban megvitatjuk, hogyan lehet egy szoftver RAID tömböt adatvesztés nélkül újratelepíteni lemezhiba esetén. A rövidség kedvéért csak a RAID 1 beállítás - de a fogalmak és a parancsok minden esetben egyformán érvényesek.
Mielőtt továbblépne, győződjön meg arról, hogy beállította a RAID 1 tömböt a sorozat 3. részében található utasításokat követve: A RAID 1 (Mirror) beállítása Linux alatt.
Jelen esetben az egyetlen variáció a következő lesz:
1) a CentOS (v7) más verziója, mint az adott cikkben (v6.5), és
2) különböző méretű lemezekhez /dev/sdb és /dev/sdc (Egyenként 8 GB).
Ezenkívül, ha SELinux végrehajtási módban engedélyezve van, akkor hozzá kell adnia a megfelelő címkéket ahhoz a könyvtárhoz, ahová a RAID eszközt csatlakoztatja. Ellenkező esetben a figyelmeztető üzenetbe fog ütközni a telepítés során:
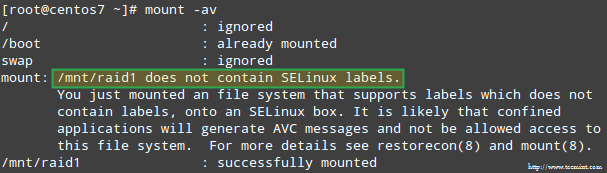
Ezt a következő módon oldhatja meg:
# restorecon -R /mnt /raid1.
Számos oka lehet annak, hogy egy tárolóeszköz meghibásodhat (az SSD -k azonban jelentősen csökkentették ennek esélyét), de az októl függetlenül biztos lehet benne, hogy a problémák bármikor felmerülhetnek, és fel kell készülnie a meghibásodott alkatrész cseréjére, valamint a készülék rendelkezésre állásának és integritásának biztosítására. adat.
Először is egy tanács. Még akkor is, ha ellenőrizheti /proc/mdstat a RAID-ok állapotának ellenőrzéséhez van egy jobb és időtakarékos módszer, amely a futtatásból áll mdadm monitor + szkennelés módban, amely e -mailben küld figyelmeztetéseket egy előre meghatározott címzettnek.
Ennek beállításához adja hozzá a következő sort /etc/mdadm.conf:
MAILADDR [e -mail védett]
Esetemben:
MAILADDR [e -mail védett]

Futni mdadm monitor + szkennelés módban adja hozzá a következő crontab bejegyzést rootként:
@reboot /sbin /mdadm --monitor --scan --oneshot.
Alapértelmezés szerint, mdadm 60 másodpercenként ellenőrzi a RAID tömböket, és figyelmeztetést küld, ha hibát talál. Ezt a viselkedést módosíthatja a --késleltetés opciót a fenti crontab bejegyzéshez a másodpercek számával együtt (pl. --késleltetés 1800 30 percet jelent).
Végül győződjön meg arról, hogy rendelkezik a Mail User Agent (MUA) telepítve, mint pl mutt vagy mailx. Ellenkező esetben nem kap figyelmeztetést.
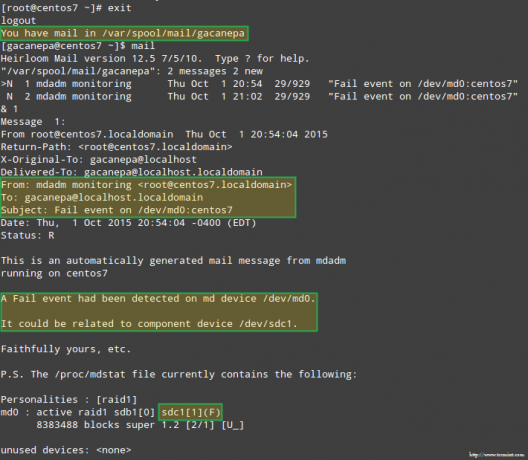
Egy perc múlva látni fogjuk, milyen riasztást küldött mdadm úgy néz ki, mint a.
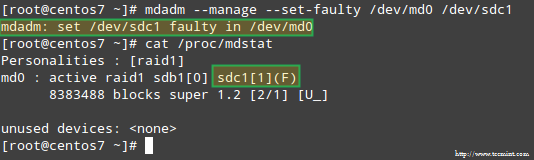
A RAID tömb egyik tárolóeszközével kapcsolatos probléma szimulálásához a -menedzsment és -készlet hibás opciók az alábbiak szerint:
# mdadm --manage-set-hibás /dev /md0 /dev /sdc1
Ennek eredménye lesz /dev/sdc1 hibásnak jelölték, ahogy belátjuk /proc/mdstat:
Ami még fontosabb, nézzük meg, hogy kaptunk -e e -mail értesítést ugyanazzal a figyelmeztetéssel:
Ebben az esetben el kell távolítania az eszközt a szoftver RAID tömbjéből:
# mdadm /dev /md0 --remove /dev /sdc1.
Ezután fizikailag eltávolíthatja a gépből, és kicserélheti egy pótalkatrészre (/dev/sdd, ahol egy típusú partíció fd korábban létrehozott):
# mdadm --manage /dev /md0 --add /dev /sdd1.
Szerencsénkre a rendszer automatikusan megkezdi a tömb újjáépítését az imént hozzáadott résszel. Ezt jelöléssel tesztelhetjük /dev/sdb1 hibásnak, távolítsa el a tömbből, és győződjön meg arról, hogy a fájl tecmint.txt címen továbbra is elérhető /mnt/raid1:
# mdadm --detail /dev /md0. # mount | grep raid1. # ls -l /mnt /raid1 | grep tecmint. # cat /mnt/raid1/tecmint.txt.
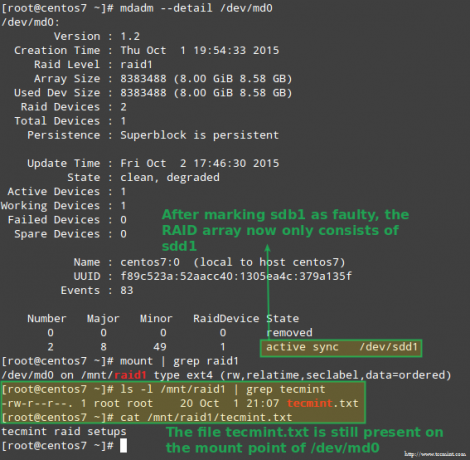
A fenti kép jól mutatja, hogy a hozzáadás után /dev/sdd1 helyett a tömbhöz /dev/sdc1, az adatok újjáépítését a rendszer automatikusan elvégezte, részünkről történő beavatkozás nélkül.
Bár nem feltétlenül szükséges, nagyszerű ötlet, ha kéznél van egy tartalék eszköz, hogy a hibás készülék jó meghajtóval történő cseréje pillanatok alatt elvégezhető legyen. Ehhez adjunk hozzá újra /dev/sdb1 és /dev/sdc1:
# mdadm --manage /dev /md0 --add /dev /sdb1. # mdadm --manage /dev /md0 --add /dev /sdc1.
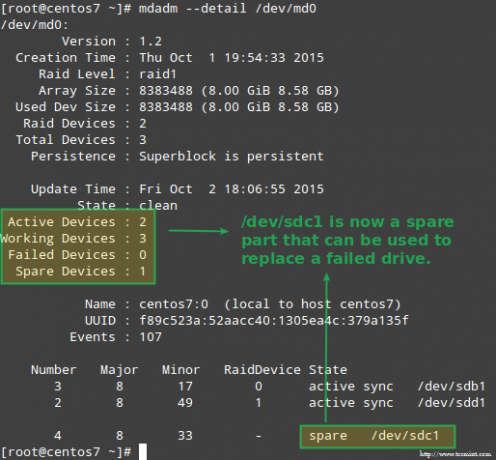
Amint azt korábban kifejtettük, mdadm automatikusan újraépíti az adatokat, ha egy lemez meghibásodik. De mi történik, ha a tömbben lévő 2 lemez meghibásodik? Szimuláljuk az ilyen forgatókönyvet a jelöléssel /dev/sdb1 és /dev/sdd1 mint hibás:
# umount /mnt /raid1. # mdadm --manage-set-hibás /dev /md0 /dev /sdb1. # mdadm -stop /dev /md0. # mdadm --manage-set-hibás /dev /md0 /dev /sdd1.
Megpróbálja újra létrehozni a tömböt, ahogyan az ekkor létrehozta (vagy a -feltételezzük, hogy tiszta lehetőség) adatvesztést eredményezhet, ezért azt utolsó lehetőségként kell hagyni.
Próbáljuk meg visszaállítani az adatokat /dev/sdb1például egy hasonló lemezpartícióba (/dev/sde1 - vegye figyelembe, hogy ehhez típusú partíciót kell létrehoznia fd ban ben /dev/sde folytatás előtt) ddrescue:
# ddrescue -r 2 /dev /sdb1 /dev /sde1.
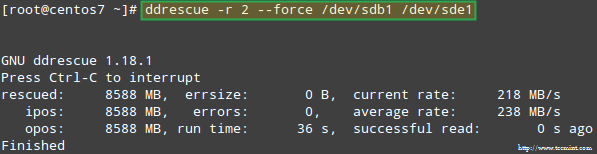
Felhívjuk figyelmét, hogy eddig nem érintettük /dev/sdb vagy /dev/sdd, a RAID tömb részét képező partíciókat.
Most építsük újra a tömböt a segítségével /dev/sde1 és /dev/sdf1:
# mdadm --create /dev /md0-szint = tükör --raid-eszközök = 2 /dev /sd [e-f] 1.
Kérjük, vegye figyelembe, hogy valós helyzetben általában ugyanazokat az eszközneveket fogja használni, mint az eredeti tömbnél, azaz /dev/sdb1 és /dev/sdc1 miután a meghibásodott lemezeket újakra cserélték.
Ebben a cikkben úgy döntöttem, hogy extra eszközöket használok a tömb újjáalakításához új lemezekkel, és elkerülöm az összetévesztést az eredeti meghibásodott meghajtókkal.
Amikor a rendszer megkérdezi, hogy folytatja -e a tömb írását, írja be Y és nyomja meg a gombot Belép. A tömböt el kell indítani, és látnia kell a fejlődését:
# watch -n 1 cat /proc /mdstat.
A folyamat befejezése után hozzá kell férnie a RAID tartalmához:
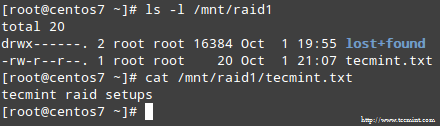
Ebben a cikkben áttekintettük, hogyan lehet felépülni RAJTAÜTÉS meghibásodások és redundancia veszteségek. Azonban emlékeznie kell arra, hogy ez a technológia egy tárolási megoldás és NEM biztonsági másolatok cseréje.
Az ebben az útmutatóban ismertetett elvek minden RAID -beállításra vonatkoznak, valamint azokra a fogalmakra, amelyekkel a sorozat következő és utolsó útmutatójában foglalkozunk (RAID -kezelés).
Ha bármilyen kérdése van ezzel a cikkel kapcsolatban, írjon nekünk egy megjegyzést az alábbi megjegyzés űrlap segítségével. Várom válaszukat!

