
Selvom Linux er meget pålidelig, bør kloge systemadministratorer til enhver tid finde en måde at holde øje med systemets adfærd og udnyttelse. Sikring af en oppetid så tæt på 100% som muligt, og tilgængeligheden af ressourcer er kritiske behov i mange miljøer. Undersøgelse af systemets tidligere og nuværende status giver os mulighed for at forudse og sandsynligvis forhindre mulige problemer.

Introduktion til Linux Foundation Certification Program
I denne artikel vil vi præsentere en liste over et par værktøjer, der er tilgængelige i de fleste upstream -distributioner for at kontrollere systemstatus, analysere afbrydelser og fejlfinde igangværende problemer. Specifikt af de utallige tilgængelige data vil vi fokusere på CPU, lagerplads og hukommelsesudnyttelse, grundlæggende processtyring og loganalyse.
Der er 2 velkendte kommandoer i Linux, der bruges til at inspicere lagerpladsforbrug: df og du.
Den første, df (som står for diskfri), bruges typisk til at rapportere den samlede diskpladsforbrug efter filsystem.
Uden muligheder, df rapporterer diskpladsforbrug i bytes. Med -h flag det vil vise de samme oplysninger ved hjælp af MB eller GB i stedet. Bemærk, at denne rapport også indeholder den samlede størrelse af hvert filsystem (i 1-K-blokke), de ledige og tilgængelige pladser og monteringspunktet for hver lagerenhed.
# df. # df -h.

Det er bestemt rart - men der er en anden begrænsning, der kan gøre et filsystem ubrugeligt, og det løber tør for inoder. Alle filer i et filsystem er kortlagt til en inode, der indeholder dens metadata.
# df -hTi.
du kan se mængden af brugte og tilgængelige inoder:
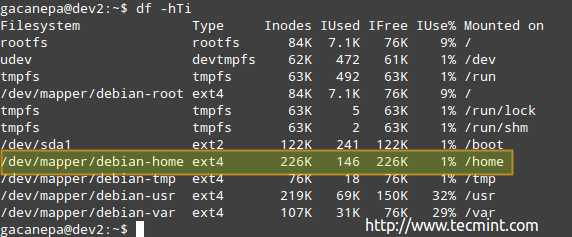
Ifølge billedet ovenfor er der 146 brugte inoder (1%) in /home, hvilket betyder, at du stadig kan oprette 226K filer i det filsystem.
Bemærk, at du kan løbe tør for lagerplads, længe før der løber tør for inoder, og omvendt. Af denne grund skal du ikke kun overvåge lagerpladsudnyttelsen, men også antallet af inoder, der bruges af filsystemet.
Brug følgende kommandoer til at finde tomme filer eller mapper (der optager 0B), der bruger inoder uden grund:
# find /home -type f -empty. # find /home -type d -empty.
Du kan også tilføje -slet flag i slutningen af hver kommando, hvis du også vil slette de tomme filer og mapper:
# find /home -type f -empty --delete. # find /home -type f -empty.
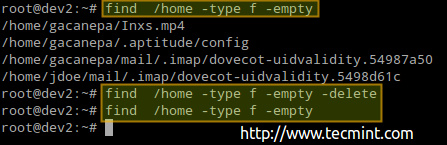
Den tidligere procedure slettede 4 filer. Lad os kontrollere antallet af brugte / tilgængelige noder igen i / home:
# df -hTi | grep hjem.

Som du kan se, er der 142 brugt inoder nu (4 mindre end før).
Hvis brugen af et bestemt filsystem er over en foruddefineret procentdel, kan du bruge du (kort for diskbrug) for at finde ud af, hvilke filer der optager mest plads.
Eksemplet er givet til /var, som du kan se på det første billede ovenfor, bruges til 67%.
# du -sch /var /*
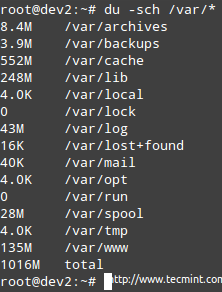
Bemærk: At du kan skifte til en af ovenstående underkataloger for at finde ud af, hvad der præcist er i dem, og hvor meget hvert element fylder. Du kan derefter bruge disse oplysninger til enten at slette nogle filer, hvis der ikke er brug for det, eller hvis det er nødvendigt at udvide størrelsen på den logiske volumen.
Læs også
Det klassiske værktøj i Linux, der bruges til at udføre en samlet kontrol af CPU / hukommelsesudnyttelse og processtyring er øverste kommando. Derudover viser top en realtidsvisning af et kørende system. Der er andre værktøjer, der kan bruges til samme formål, som f.eks htop, men jeg har nøjes med toppen, fordi den er installeret ude af boksen i enhver Linux-distribution.
For at starte toppen skal du blot skrive følgende kommando i din kommandolinje og trykke på Enter.
# top.
Lad os undersøge et typisk topoutput:
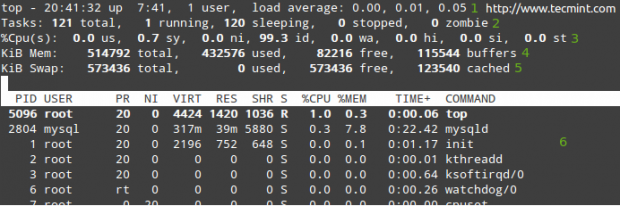
I række 1 til 5 vises følgende oplysninger:
1. Den aktuelle tid (20:41:32 pm) og oppetid (7 timer og 41 minutter). Kun én bruger er logget på systemet og belastningsgennemsnittet i løbet af de sidste 1, 5 og 15 minutter. 0,00, 0,01 og 0,05 angiver, at systemet i løbet af disse tidsintervaller var inaktiv i 0% af tiden (0,00: ingen processer var venter på CPU'en), blev den derefter overbelastet med 1% (0,01: et gennemsnit på 0,01 processer ventede på CPU'en) og 5% (0.05). Hvis mindre end 0 og jo mindre tallet (f.eks. 0,65), var systemet inaktivt i 35% i løbet af de sidste 1, 5 eller 15 minutter, afhængigt af hvor 0,65 vises.
2. I øjeblikket kører der 121 processer (du kan se hele listen i 6). Kun 1 af dem kører (øverst i dette tilfælde, som du kan se i kolonnen %CPU) og de resterende 120 venter i baggrunden, men "sover" og forbliver i den tilstand, indtil vi kalder dem. Hvordan? Du kan bekræfte dette ved at åbne en mysql -prompt og udføre et par forespørgsler. Du vil bemærke, hvordan antallet af løbende processer stiger.
Alternativt kan du åbne en webbrowser og navigere til enhver given side, der betjenes af Apache, og du får det samme resultat. Disse eksempler går naturligvis ud fra, at begge tjenester er installeret på din server.
3. os (tid, der kører brugerprocesser med uændret prioritet), sy (tid, der kører kerneprocesser), ni (tid, der kører brugerprocesser med ændret prioritet), wa (tid venter på I/O færdiggørelse), hej (tid brugt på at servicere hardwareafbrydelser), si (tid brugt på at servicere softwareafbrydelser), st (tid stjålet fra den aktuelle vm af hypervisoren - kun i virtualiseret miljøer).
4. Fysisk hukommelsesbrug.
5. Skift pladsforbrug.
For at inspicere RAM -hukommelse og bytte brug kan du også bruge gratis kommando.
# gratis.

Selvfølgelig kan du også bruge -m (MB) eller -g (GB) skifter til at vise de samme oplysninger i læsbar form:
# fri -m.

Uanset hvad skal du være opmærksom på, at kernen forbeholder sig så meget hukommelse som muligt og gør den tilgængelig for processer, når de anmoder om det. Især "-/+ buffere/cache”-Linjen viser de faktiske værdier, efter at denne I/O -cache er taget i betragtning.
Med andre ord, mængden af hukommelse, der bruges af processer, og mængden, der er tilgængelig for andre processer (i dette tilfælde, 232 MB brugt og 270 MB henholdsvis tilgængelig). Når processer har brug for denne hukommelse, reducerer kernen automatisk størrelsen på I/O -cachen.
Læs også: 10 Nyttig "gratis" kommando til at kontrollere Linux -hukommelsesforbrug
Til enhver tid kører der mange processer på vores Linux -system. Der er to værktøjer, som vi vil bruge til at overvåge processer nøje: ps og pstree.
Bruger -e og -f muligheder kombineret til en (-ef) kan du liste alle de processer, der aktuelt kører på dit system. Du kan rør denne output til andre værktøjer, f.eks grep (som forklaret i Del 1 af LFCS -serien) for at indsnævre output til din (e) ønskede proces (er):
# ps -ef | grep -i blæksprutte | grep -v grep.
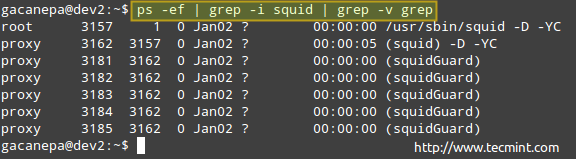
Ovenstående procesoversigt viser følgende oplysninger:
ejer af processen, PID, forælder -PID (forælderprocessen), processorudnyttelse, tidspunkt da kommandoen startede, tty (the? angiver, at det er en dæmon), den kumulerede CPU -tid og kommandoen, der er knyttet til processen.
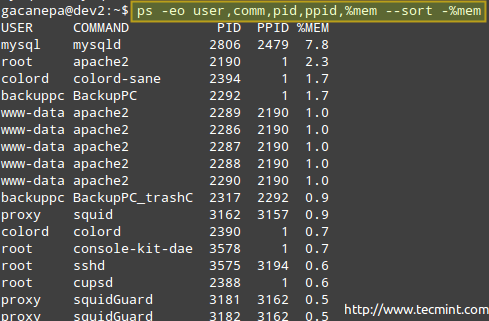
Men måske har du ikke brug for alle disse oplysninger og vil gerne vise ejeren af processen, kommandoen der startede den, dens PID og PPID, og procentdelen af hukommelse, den bruger i øjeblikket - i den rækkefølge og sorter efter hukommelsesbrug i faldende rækkefølge (bemærk, at ps som standard er sorteret efter PID).
# ps -eo bruger, komm, pid, ppid,%mem --sort -%mem.
Hvor minustegnet foran %mem angiver sortering i faldende rækkefølge.
Hvis en proces af en eller anden grund begynder at tage for mange systemressourcer, og det sandsynligvis vil bringe helheden i fare systemets funktionalitet, vil du ønsker at stoppe eller sætte udførelsen på pause ved at sende et af følgende signaler ved hjælp af det dræbe program til det. Andre grunde til, at du ville overveje at gøre dette, er når du har startet en proces i forgrunden, men ønsker at sætte den på pause og genoptage i baggrunden.
| Signalnavn | Signalnummer | Beskrivelse |
| SIGTERM | 15 | Dræb processen graciøst. |
| SKILT | 2 | Dette er det signal, der sendes, når vi trykker på Ctrl + C. Det har til formål at afbryde processen, men processen kan ignorere den. |
| SIGKILL | 9 | Dette signal afbryder også processen, men det gør det ubetinget (brug med omtanke!), Da en proces ikke kan ignorere det. |
| OPSKRIFT | 1 | Kort for "Hang UP", instruerer disse signaler dæmoner i at genlæse sin konfigurationsfil uden egentlig at stoppe processen. |
| SIGTSTP | 20 | Stop udførelsen, og vent klar til at fortsætte. Dette er det signal, der sendes, når vi skriver tastekombinationen Ctrl + Z. |
| SIGSTOP | 19 | Processen er sat på pause og får ikke mere opmærksomhed fra CPU -cyklusser, før den genstartes. |
| SIGCONT | 18 | Dette signal fortæller processen om at genoptage udførelsen efter at have modtaget enten SIGTSTP eller SIGSTOP. Dette er det signal, der sendes af skallen, når vi bruger kommandoer fg eller bg. |
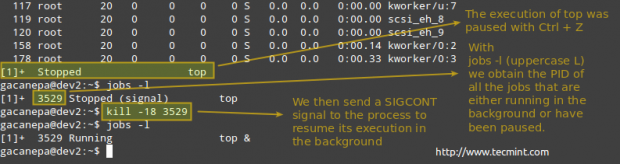
Når den normale udførelse af en bestemt proces indebærer, at der ikke sendes noget output til skærmen, mens det er kører, kan du enten starte det i baggrunden (tilføje et ampersand i slutningen af kommando).
procesnavn &
eller,
Når det er begyndt at køre i forgrunden, skal du sætte det på pause og sende det til baggrunden med
Ctrl + Z.
# kill -18 PID.
Bemærk, at hver distribution giver værktøjer til graciøst at stoppe / starte / genstarte / genindlæse almindelige tjenester, som f.eks service i SysV-baserede systemer eller systemctl i system-baserede systemer.
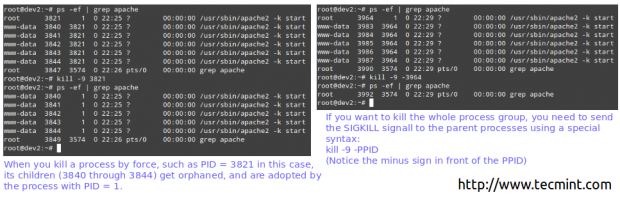
Hvis en proces ikke reagerer på disse hjælpeprogrammer, kan du dræbe den med magt ved at sende den SIGKILL -signalet til den.
# ps -ef | grep apache. # dræb -9 3821.
Når der har været nogen form for afbrydelse i systemet (det være sig en strømafbrydelse, en hardwarefejl, en planlagt eller ikke planlagt afbrydelse af en proces eller nogen abnormitet overhovedet), logger der på /var/log er dine bedste venner til at afgøre, hvad der skete, eller hvad der kunne forårsage de problemer, du står over for.
# cd /var /log.

Nogle af emnerne i /var/log er almindelige tekstfiler, andre er mapper, og endnu andre er komprimerede filer med roterede (historiske) logfiler. Du vil gerne kontrollere dem med ordfejl i deres navn, men inspektion af resten kan også være praktisk.
Forestil dig dette scenario. Dine LAN -klienter kan ikke udskrive til netværksprintere. Det første trin til fejlfinding af denne situation går til /var/log/cups bibliotek og se, hvad der er der.
Du kan bruge hale kommando for at vise de sidste 10 linjer i filen error_log, eller hale -f error_log for en real-time visning af loggen.
# cd/var/log/cups. # ls. # hale fejl_log.
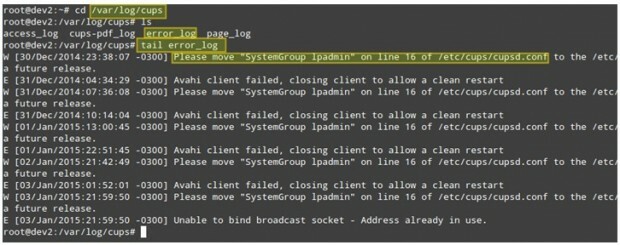
Ovenstående skærmbillede giver nogle nyttige oplysninger for at forstå, hvad der kan forårsage dit problem. Bemærk, at det ikke er muligt at løse det overordnede problem ved at følge trinene eller rette fejlen i processen, men hvis du bliver brugt lige fra starten for at tjekke logfilerne hver gang der opstår et problem (det være sig et lokalt eller et netværksproblem) vil du helt sikkert være til højre spore.
Selvom hardwarefejl kan være vanskelige at fejlfinde, skal du kontrollere dmesg og meddelelseslogfiler og grep for relaterede ord til en hardwaredel, der formodes at være defekt.
Billedet herunder er taget fra /var/log/messages efter at have ledt efter ordfejl ved hjælp af følgende kommando:
# mindre/var/log/meddelelser | grep -i fejl.
Vi kan se, at vi har et problem med to lagerenheder: /dev/sdb og /dev/sdc, hvilket igen forårsager et problem med RAID -arrayet.

I denne artikel har vi undersøgt nogle af de værktøjer, der kan hjælpe dig med altid at være opmærksom på dit systems samlede status. Derudover skal du sikre dig, at dit operativsystem og installerede pakker er opdateret til deres seneste stabile versioner. Og glem aldrig at tjekke logfiler! Derefter går du i den rigtige retning for at finde den endelige løsning på eventuelle problemer.
Efterlad gerne dine kommentarer, forslag eller spørgsmål - hvis du har nogen - ved hjælp af formularen herunder.

